基于PostgreSQL/openGauss 的分布式数据库解决方案
在 MySQL ShardingSphere-Proxy 逐渐成熟并被广泛采用的同时,ShardingSphere 团队也在 PostgreSQL ShardingSphere-Proxy 上持续发力。相比前期的 alpha 与 beta,5.0.0 正式版对 PostgreSQL 的协议实现、SQL 支持度、权限控制等方面进行了大量的完善,为后续全面对接 PostgreSQL 生态打下基础。ShardingSphere-Proxy 与 PostgreSQL 的生态对接,让用户能够在 PostgreSQL 数据库的基础上获得如数据分片、读写分离、影子库、数据加密/脱敏、分布式治理等透明化的增量能力。
除了 PostgreSQL 方面,由华为开源的国产数据库 openGauss 的热度持续攀升。openGauss 具备优秀的单机性能,配合 ShardingSphere 的能力和生态,能够打造出覆盖更多场景的国产分布式数据库解决方案。
ShardingSphere PostgreSQL/openGauss Proxy 目前能够支持数据分片、读写分离、影子库、数据加密/脱敏、分布式治理等 Apache ShardingSphere 生态中大部分能力,在完善程度上逐渐对齐 ShardingSphere MySQL Proxy。
本文将给大家介绍 ShardingSphere-Proxy 5.0.0 在 PostgreSQL 上所做的提升以及与 openGauss 的生态对接。
作者介绍
吴伟杰
Apache ShardingSphere Committer,SphereEx 中间件工程师。目前专注于 Apache ShardingSphere 及其子项目 ElasticJob 的研发。
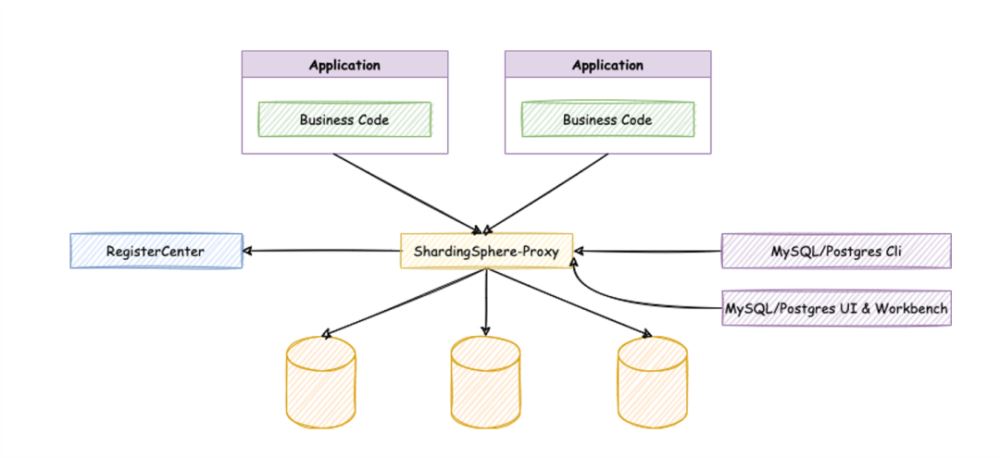
ShardingSphere-Proxy 介绍
ShardingSphere-Proxy 是 ShardingSphere 生态中的一个接入端,定位为对客户端透明的数据库代理。ShardingSphere Proxy 不局限于 Java,其实现了 MySQL、PostgreSQL 数据库协议,可以使用各种兼容 MySQL / PostgreSQL 协议的客户端连接并操作数据。
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| 数据库 | 任意 | 基于 MySQL / PostgreSQL 协议的数据库 |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 支持 Java 等基于 JVM 语言 | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
在做了分库分表或其他规则的情况下,数据会分散到多个数据库实例上,在管理上难免会有一些不便;或者使用非 Java 语言的开发者,需要 ShardingSphere 所提供的能力…… 以上这些情况,正是 ShardingSphere-Proxy 力所能及之处。
ShardingSphere-Proxy 隐藏了后端实际数据库,对于客户端来说就是在使用一个数据库,不需要关心 ShardingSphere 如何协调背后的数据库,对于使用非 Java 语言的开发者或 DBA 更友好。
在协议方面,ShardingSphere PostgreSQL Proxy 实现了 Simple Query 与大部分 Extended Query 协议,支持异构语言通过 PostgreSQL/openGauss 驱动连接 Proxy。ShardingSphere openGauss Proxy 在复用 PostgreSQL 协议的基础上,还支持 openGauss 特有的批量插入协议。
不过,由于 ShardingSphere-Proxy 相比 ShardingSphere-JDBC 增加了一层网络交互,SQL 执行的延时会有所增加,损耗相比 ShardingSphere-JDBC 略高。
ShardingSphere-Proxy 与 PostgreSQL 的生态对接
兼容 PostgreSQL Simple Query 与 Extended Query

Simple Query 与 Extended Query 是大多数用户在使用 PostgreSQL 时最常用的协议。
比如,使用如下命令行工具 psql 连接 PostgreSQL 数据库进行 CRUD 操作时,主要使用 Simple Query 协议与数据库交互。
$ psql -h 127.0.0.1 -U postgres psql (14.0 (Debian 14.0-1.pgdg110+1)) Type "help" for help. postgres=# select id, name from person where age < 35; id | name ----+------ 1 | Foo (1 row)
Simple Query 的协议交互示意图如下:

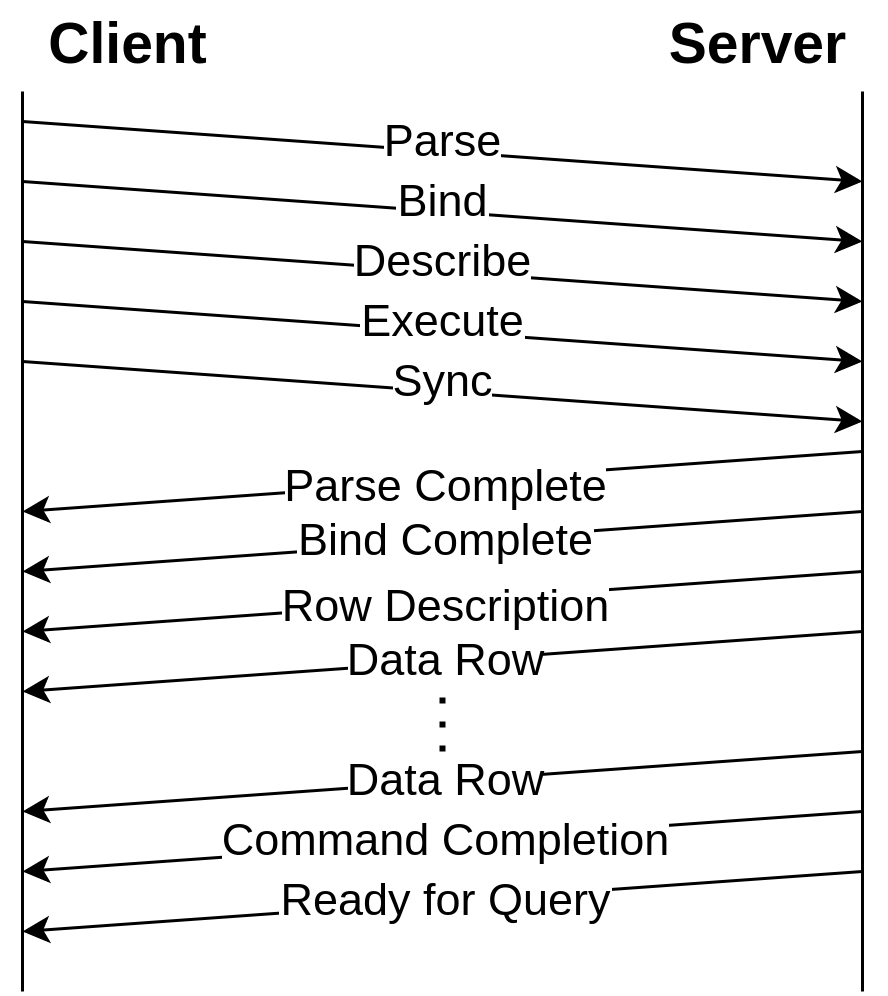
当用户使用 PostgreSQL JDBC Driver 等驱动时,可能会如下代码使用 PreparedStatement,默认情况下对应着 Extended Query 协议。
String sql = "select id, name from person where age > ?"; PreparedStatement ps = connection.prepareStatement(sql); ps.setInt(1, 35); ResultSet resultSet = ps.executeQuery();
Extended Query 的协议交互示意图如下:
目前,ShardingSphere PostgreSQL Proxy 实现了 Simple Query 与大部分 Extended Query 协议,不过,因为数据库客户端与驱动已经封装好 API 供用户使用,一般用户并不需要关心数据库协议层面的事情。
ShardingSphere-Proxy 兼容 PostgreSQL 的 Simple Query 与 Extended Query 意味着:用户可以使用常见的 PostgreSQL 客户端或驱动连接 ShardingSphere-Proxy 进行 CRUD 操作,利用 ShardingSphere 在数据库上层提供的增量能力。
ShardingSphere-Proxy 与 openGauss 的生态对接
支持 openGauss JDBC Driver
openGauss 数据库有对应的 JDBC 驱动,JDBC URL 的前缀jdbc:opengauss。虽然用 PostgreSQL 的 JDBC 驱动也能够连接 openGauss 数据库,但这样就无法完全利用 openGauss 特有的批量插入等特性。ShardingSphere 增加了 openGauss 数据库类型,能够识别 openGauss JDBC Driver,开发者在使用 ShardingSphere 的时候可以直接使用 openGauss 的 JDBC 驱动。
支持 openGauss 批量插入协议
举一个例子,当我们 prepare 一个 insert 语句如下
insert into person (id, name, age) values (?, ?, ?)
以 JDBC 为例,我们可能会使用如下方法执行批量插入:
String sql = "insert into person (id, name, age) values (?, ?, ?)"; PreparedStatement ps = connection.prepareStatement(sql); ps.setLong(1, 1); ps.setString(2, "Foo"); ps.setInt(3, 18); ps.addBatch(); ps.setLong(1, 2); ps.setString(2, "Bar"); ps.setInt(3, 36); ps.addBatch(); ps.setLong(1, 3); ps.setString(2, "Tom"); ps.setInt(3, 54); ps.addBatch(); ps.executeBatch();
在 PostgreSQL 协议层面,Bind 消息每次能够传递一组参数形成 Portal,Execute 每次能够执行一个 Portal。执行批量插入可以通过反复执行 Bind 和 Execute 实现。协议交互示意图如下:

Batch Bind 是 openGauss 特有的消息类型,相比原本的 Bind,Batch Bind 一次能够传递多组参数,使用 Batch Bind 执行批量插入的协议交互示意如下:

ShardingSphere-Proxy openGauss 实现了对 Batch Bind 协议的支持,也就是说,客户端能够直接用 openGauss 的客户端或驱动对 ShardingSphere Proxy 执行批量插入。
ShardingSphere-Proxy 后续要做的事情
支持 ShardingSphere PostgreSQL Proxy 逻辑 MetaData 查询
ShardingSphere-Proxy 作为透明数据库代理,用户无需关心 Proxy 如何协调背后的数据库。
以下图为例,在 ShardingSphere-Proxy 中配置逻辑库 sharding_db 和逻辑表 person,Proxy背后实际对应了 2 个数据库共 4 个表。

目前在 ShardingSphere MySQL Proxy 中分别执行 show schemas、show tables 语句,查询的结果能够正常的列出逻辑库 sharding_db 和逻辑表 person。
使用 psql 连接 PostgreSQL 时可以通过 \l、\d 等命令查询库、表。但与 MySQL 不同的是,show tables是 MySQL 所支持的语句,而在 psql 中所使用的 \d 实际上对应了一条比较复杂的 SQL,目前使用 ShardingSphere PostgreSQL Proxy 暂时无法查询出逻辑库或逻辑表。
支持 Extended Query 的 Describe Prepared Statement
PostgreSQL 协议的 Describe 消息有两种变体,分别是 Describe Portal 和 Describe Prepared Statement。目前 ShardingSphere Proxy 仅支持 Describe Portal,暂时不支持 Describe Prepared Statement。
Describe Prepared Statement 的实际应用举例:在 PreparedStatement 执行之前获取结果集的 MetaData。
PreparedStatement preparedStatement = connection.prepareStatement("select * from t_order limit ?");
ResultSetMetaData metaData = preparedStatement.getMetaData();
ShardingSphere 与 PostgreSQL/openGauss 生态对接的过程仍在进行,后续需要做的事情还有很多。如果您对我们所做的事情感兴趣,欢迎通过 GitHub 或邮件列表参与 ShardingSphere 社区。
GitHub: https://github.com/apache/shardingsphere
参考资料
https://www.postgresql.org/docs/current/protocol.html
到此这篇关于打造基于 PostgreSQL/openGauss 的分布式数据库解决方案的文章就介绍到这了,更多相关PostgreSQL分布式数据库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Postgresql分布式插件plproxy的使用详解
Simple remote function call 节点61/62(datanode) CREATE TABLE users (username text, email text); insert into users values ('user0', 'user0@gmail.com'); insert into users values ('user1', 'user1@gmail.com'); insert into users values ('user2', 'user2@gmai
-

基于PostgreSQL/openGauss 的分布式数据库解决方案
在 MySQL ShardingSphere-Proxy 逐渐成熟并被广泛采用的同时,ShardingSphere 团队也在 PostgreSQL ShardingSphere-Proxy 上持续发力.相比前期的 alpha 与 beta,5.0.0 正式版对 PostgreSQL 的协议实现.SQL 支持度.权限控制等方面进行了大量的完善,为后续全面对接 PostgreSQL 生态打下基础.ShardingSphere-Proxy 与 PostgreSQL 的生态对接,让用户能够在 Postg
-
详解SpringBoot基于Dubbo和Seata的分布式事务解决方案
1. 分布式事务初探 一般来说,目前市面上的数据库都支持本地事务,也就是在你的应用程序中,在一个数据库连接下的操作,可以很容易的实现事务的操作. 但是目前,基于SOA的思想,大部分项目都采用微服务架构后,就会出现了跨服务间的事务需求,这就称为分布式事务. 本文假设你已经了解了事务的运行机制,如果你不了解事务,那么我建议先去看下事务相关的文章,再来阅读本文. 1.1 什么是分布式事务 对于传统的单体应用而言,实现本地事务可以依赖Spring的@Transactional注解标识方法,实现事务非常简
-
利用C#实现分布式数据库查询
随着传统的数据库.计算机网络和数字通信技术的飞速发展,以数据分布存储和分布处理为主要特征的分布式数据库系统的研究和开发越来越受到人们的关注.但由于其开发较为复杂,在一定程度上制约了它的发展.基于此,本文提出了在.Net环境下使用一种新的开发语言C#结合ADO.Net数据访问模型来开发分布式数据库系统,大大简化了开发过程. 1 分布式数据库系统 就其本质而言,分布式数据库系统的数据在逻辑上是统一的,而在物理上却是分散的.与集中式数据库相比它有如下主要优点: · 解决组织机构分散而数据需要相互联系的
-
基于springboot实现redis分布式锁的方法
在公司的项目中用到了分布式锁,但只会用却不明白其中的规则 所以写一篇文章来记录 使用场景:交易服务,使用redis分布式锁,防止重复提交订单,出现超卖问题 分布式锁的实现方式 基于数据库乐观锁/悲观锁 Redis分布式锁(本文) Zookeeper分布式锁 redis是如何实现加锁的? 在redis中,有一条命令,实现锁 SETNX key value 该命令的作用是将 key 的值设为 value ,当且仅当 key 不存在.若给定的 key 已经存在,则 SETNX不做任何动作.设置成功,返
-
Spring Cloud + Nacos + Seata整合过程(分布式事务解决方案)
目录 一.简介 二.seata-server部署 1.官网下载 2.解压到本地 3.修改配置文件 4.seata数据库初始化 5.业务数据库 6.启动seata-server 三.微服务项目集成Seata 1.引入依赖 2.配置文件 一.简介 Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务. 2019 年 1 月,阿里巴巴中间件团队发起了开源项目 Fescar(Fast & EaSy Commit And Rollback),和社区
-
redis分布式ID解决方案示例详解
目录 常用的分布式ID解决方案 UUID Snowflake Snowflake算法的Java代码: Leaf Leaf算法的Java代码: 基于数据库自增ID生成 基于UUID生成 基于Redis生成 基于ZooKeeper生成 常用的分布式ID解决方案 在分布式系统中,生成全局唯一ID是非常重要的,因为在分布式系统中,多个节点同时生成ID可能会导致ID冲突. 下面介绍几种常用的分布式ID解决方案. UUID UUID(通用唯一标识符)是由128位数字组成的标识符,它可以保证在全球范围内的唯一
-
常见PHP数据库解决方案分析介绍
我们在使用PHP连接数据库的时候会遇到很多问题,文章这里揭露PHP应用程序中出现的常见数据库问题 -- 包括数据库模式设计.数据库访问和使用数据库的业务逻辑代码 -- 以及它们的解决方案.如果只有一种方式使用数据库是正确的. PHP数据库问题:直接使用MySQL 一个常见问题是较老的 PHP 代码直接使用 mysql_ 函数来访问数据库.清单 1 展示了如何直接访问数据库. 清单 1. Access/get.php <?php function get_user_id( $name ) {
-
详解基于Android App 安全登录认证解决方案
近几年移动互联网的高速发展,智能手机的使用用户呈现爆炸性增长,手机终端上的App 种类繁多,大多数App 都需要与后台系统进行交互,交互的第一步需要进行登录认证,过于简单的认证方式可能被破解从而造成用户信息的泄露甚至威胁着用户的财产安全.为此基于Android 系统,对比现有几种常见的App 登录认证方式,并提出一种采用RSA 非对称加密和加入Token 时效机制的登录认证解决方案.在登录验证阶段采用RSA 非对称加密方式,App 端对服务器端返回的Token 信息加上时间戳,将处理后的Toke
-
LCN分布式事务解决方案详解
目录 一.什么是分布式事务? 二.lcn的实现思路 2.1 本地执行的状态怎么提交给全局事务? 2.2 本地事务的提交或回滚怎么实现? 三.lcn的使用 3.1 下载lcn-manager (全局的事务管理器) 3.2 配置lcn-manager 3.3 启动lcn 3.4 模拟转账服务 3.4.1 add-service 3.4.2 decr-service 3.5 2 个微服务都需要添加依赖 3.6 需要自定义数据库的连接池 3.7 使用 3.7.1 事务的发起者 3.7.2 添加配置文件
-
一文搞明白Java Spring Boot分布式事务解决方案
目录 前言 1. 什么是反向补偿 2. 基本概念梳理 3. 什么是两阶段提交 4. AT 模式 5. TCC 模式 6. XA 模式 7. Saga 模式 前言 分布式事务,咱们前边也聊过很多次了,网上其实也有不少文章在介绍分布式事务,不过里边都会涉及到不少专业名词,看的大家云里雾里,所以还是有一些小伙伴在微信上问我. 那么今天,我就再来一篇文章,和大家捋一捋这个话题.以下的内容主要围绕阿里的 seata 来和大家解释. 1. 什么是反向补偿 首先,来和大家解释一个名词,大家在看分布式事务相关资