Java 讲解两种找二叉树的最近公共祖先的方法
目录
- 思路一:先假设这棵树是二叉搜索树
- 思路二:假设该树是用孩子双亲表示法
思路一:先假设这棵树是二叉搜索树
首先我们补充说明一下什么是二叉搜索树:
在二叉搜索树中,对于每一个节点来说,他的左子树中的值都比他小,右子树的中的值都比他大。所以二叉搜索树的中序遍历是一组有序的数据。

对于上述这棵树,假设要求 p q 的最近公共祖先。
那么它有以下情况:


对于普通的二叉树来说,也无非就这几种情况:pq都在左,pq都在右,pq一左一右,pq有一个是根节点。
所以分别递归的去左子树和右子树中找 p q 节点的公共祖先,找到了则返回该节点,没有找到则返回空。



根据上述思路,我们很容易写出代码
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null) return null;
// p 为当前树的根节点
if(p == root) return p;
// q 为当前树的根节点
if(q == root) return q;
// 去左子树中找
TreeNode left = lowestCommonAncestor(root.left,p,q);
// 去右子树中找
TreeNode right = lowestCommonAncestor(root.right,p,q);
// 左边右边都找到了
if(left != null && right != null) {
return root;
}
// 左边找到了,右边没找到
if(left != null) {
return left;
}
if(right != null) {
return right;
}
return null;
}
思路二:假设该树是用孩子双亲表示法
每个节点会保存它父亲节点的地址,可以层层网上找,直到找到两链表的第一个交点,该交点就是他们的公共祖先。

而对于普通的二叉树来说,只能层层往下找,不能往上,所以要保留两节点的路径,直到两路径的最后一个相同节点。这里我们用栈来保留两个节点的路径。
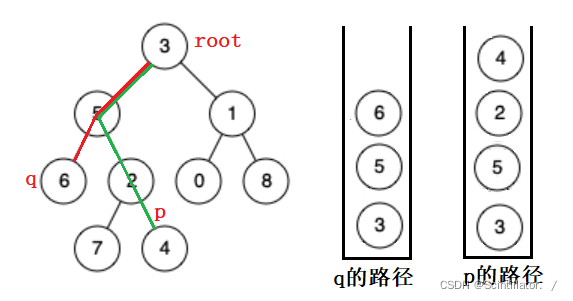
先弹出元素多的栈中的元素,然后两个栈再一起弹出,直到要弹出的节点相等,就是其最近公共祖先。

那么这里最大的难点就是存储路径。
这里用栈来存储路径,当遍历到一个节点时,将该节点放入栈中,再递归该节点的左树和右树找,如果找到了则保留路径,没找到则弹出。
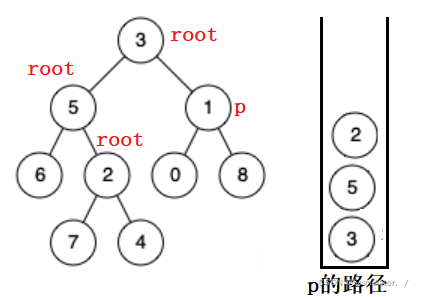
假设找下图的p:

先将根节点放入栈,递归root节点的左子树找,找不到则弹出,在右子树中找。

当 root 走到 6 的时候,发现该节点的左右均为空,说明在该子树中没找到目标节点,弹出 6 ,在 5 的右子树中继续找。
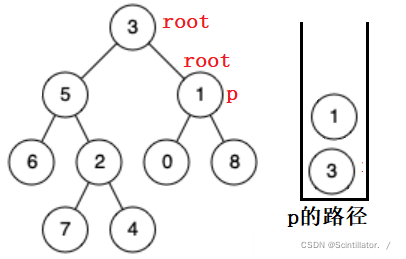
同理在 5 的右子树中也找不到,会弹出直到去 3 的右子树找,来到 1 ,找到。
// 用于找节点的路径
public boolean getPath(TreeNode root, TreeNode node, Stack<TreeNode> stack) {
if(root == null || node == null) {
return false;
}
// 将当前节点放入栈中
stack.push(root);
if(root.val == node.val) {
return true;// 找到了
}
// 当前节点没找到,去左子树找
boolean flag = getPath(root.left,node,stack);
// 左子树中找到了,直接返回
if(flag) {
return true;
}
// 左子树没找到,去右子树找
flag = getPath(root.right,node,stack);
// 右子树中找到了,直接返回
if(flag) {
return true;
}
// 左右子树都没找到,弹出节点
stack.pop();
return false;
}
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null) {
return null;
}
Stack<TreeNode> stackp = new Stack<>();
Stack<TreeNode> stackq = new Stack<>();
// 分别得到 p q 的路径
getPath(root,p,stackp);
getPath(root,q,stackq);
int sizep = stackp.size();
int sizeq = stackq.size();
if(sizep > sizeq) {
int size = sizep - sizeq;
// 弹出元素直至两栈中元素个数相等
while(size > 0) {
stackp.pop();
size--;
}
}else {
int size = sizeq - sizep;
// 弹出元素直至两栈中元素个数相等
while(size > 0) {
stackq.pop();
size--;
}
}
// 一起弹出,直到找到第一个相同的元素
while(!stackp.isEmpty() && !stackq.isEmpty()) {
if(stackp.peek() == stackq.peek()) {
// 找到了,就返回该节点
return stackq.pop();
}else {
stackp.pop();
stackq.pop();
}
}
// 没找到,返回 null
return null;
}
到此这篇关于Java 图文并茂讲解两种找二叉树的最近公共祖先的方法的文章就介绍到这了,更多相关Java 二叉树最近公共祖先内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java求解二叉树的最近公共祖先实例代码
一.题目 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先. 百度百科中最近公共祖先的定义为:"对于有根树 T 的两个结点 p.q,最近公共祖先表示为一个结点 x,满足 x 是 p.q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)." 例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4] 二.分析 本题需要找公共祖先,如果可以从下往上查找,就可以很方便的找到公共祖先 所以需要先访问叶子节点,然后在往上访问,对应着二叉树的
-
Java 讲解两种找二叉树的最近公共祖先的方法
目录 思路一:先假设这棵树是二叉搜索树 思路二:假设该树是用孩子双亲表示法 思路一:先假设这棵树是二叉搜索树 首先我们补充说明一下什么是二叉搜索树: 在二叉搜索树中,对于每一个节点来说,他的左子树中的值都比他小,右子树的中的值都比他大.所以二叉搜索树的中序遍历是一组有序的数据. 对于上述这棵树,假设要求 p q 的最近公共祖先. 那么它有以下情况: 对于普通的二叉树来说,也无非就这几种情况:pq都在左,pq都在右,pq一左一右,pq有一个是根节点. 所以分别递归的去左子树和右子树中找 p q 节
-
Java 图文并茂讲解两种找二叉树的最近公共祖先的方法
目录 思路一:先假设这棵树是二叉搜索树 思路二:假设该树是用孩子双亲表示法 思路一:先假设这棵树是二叉搜索树 首先我们补充说明一下什么是二叉搜索树: 在二叉搜索树中,对于每一个节点来说,他的左子树中的值都比他小,右子树的中的值都比他大.所以二叉搜索树的中序遍历是一组有序的数据. 对于上述这棵树,假设要求 p q 的最近公共祖先. 那么它有以下情况: 对于普通的二叉树来说,也无非就这几种情况:pq都在左,pq都在右,pq一左一右,pq有一个是根节点. 所以分别递归的去左子树和右子树中找 p q 节
-
java jvm两种存储区的类型知识点讲解
我们知道在jvm中存放了不少数据,那么存放数据的地方叫做存储区.想必大家还不知道存储区是分为两种类型的,常量缓冲池和方法区.相信很多人还没有接触到这个概念,本篇对java中jvm的存储区进行的内容的整理,下面一起来看看这两种存储取的概念和区别吧. 1.分类 JVM有两种类型的存储区:常量缓冲池和方法区.常量缓冲池用于存储类名.方法名和字段名以及字符串常量.方法区用于存储Java方法的字节码.JVM规范中没有规定这两个存储区域的具体实现.因此,Java应用程序的存储布局必须在运行过程中确定,这取决
-
java编程两种树形菜单结构的转换代码
首先看看两种树形菜单结构的代码示例. SingleTreeNode: package com.zzj.tree; public class SingleTreeNode { private int id; private int pId; private String name; public SingleTreeNode() { } public SingleTreeNode(int id, int pId, String name) { this.id = id; this.pId = pI
-
浅谈Java的两种多线程实现方式
本文介绍了浅谈Java的两种多线程实现方式,分享给大家.具有如下: 一.创建多线程的两种方式 Java中,有两种方式可以创建多线程: 1 通过继承Thread类,重写Thread的run()方法,将线程运行的逻辑放在其中 2 通过实现Runnable接口,实例化Thread类 在实际应用中,我们经常用到多线程,如车站的售票系统,车站的各个售票口相当于各个线程.当我们做这个系统的时候可能会想到两种方式来实现,继承Thread类或实现Runnable接口,现在看一下这两种方式实现的两种结果. 程序1
-
Java HashMap两种简便排序方法解析
这篇文章主要介绍了Java HashMap两种简便排序方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 HashMap的储存是没有顺序的,而是按照key的HashCode实现. key=手机品牌,value=价格,这里以这个例子实现按名称排序和按价格排序. Map phone=new HashMap(); phone.put("Apple",8899); phone.put("SAMSUNG",7000);
-
详解Java中两种分页遍历的使用姿势
在日常开发中,分页遍历迭代的场景可以说非常普遍了,比如扫表,每次捞100条数据,然后遍历这100条数据,依次执行某个业务逻辑:这100条执行完毕之后,再加载下一百条数据,直到扫描完毕 那么要实现上面这种分页迭代遍历的场景,我们可以怎么做呢 本文将介绍两种使用姿势 常规的使用方法 借助Iterator的使用姿势 1. 数据查询模拟 首先mock一个分页获取数据的逻辑,直接随机生成数据,并且控制最多返回三页 public static int cnt = 0; private static List
-
RocketMq深入分析讲解两种削峰方式
目录 何时需要削峰 通过消息队列的削峰方法有两种 消费延时控流 总结 何时需要削峰 当上游调用下游服务速率高于下游服务接口QPS时,那么如果不对调用速率进行控制,那么会发生很多失败请求 通过消息队列的削峰方法有两种 控制消费者消费速率和生产者投放延时消息,本质都是控制消费速度 通过消费者参数控制消费速度 先分析那些参数对控制消费速度有作用 1.PullInterval: 设置消费端,拉取mq消息的间隔时间. 注意:该时间算起时间是rocketMq消费者从broker消息后算起.经过PullInt
-
jQuery autoComplete插件两种使用方式及动态改变参数值的方法详解
本文实例讲述了jQuery autoComplete插件两种使用方式及动态改变参数值的方法.分享给大家供大家参考,具体如下: 一.一次加载.多次使用: 前端JS代码: /*客户名称自动匹配*/ function customerAutoComplete(){ $.ajax({ type:"GET", url:encodeURI("/approvalajax/salesOrderApproval_findCustomerList"), dataType:"j