Python爬虫练习汇总
目录
- 一、 软件配置
- 二、爬取南阳理工OJ题目
- (一)页面分析
- (二)代码编写
- 三、爬取学校信息通知
- (一)页面分析
- (二)代码编写
一、 软件配置
安装必备爬虫环境软件:
- python 3.8
- pip install requests
- pip install beautifulsoup4
二、爬取南阳理工OJ题目
网站地址:http://www.51mxd.cn/
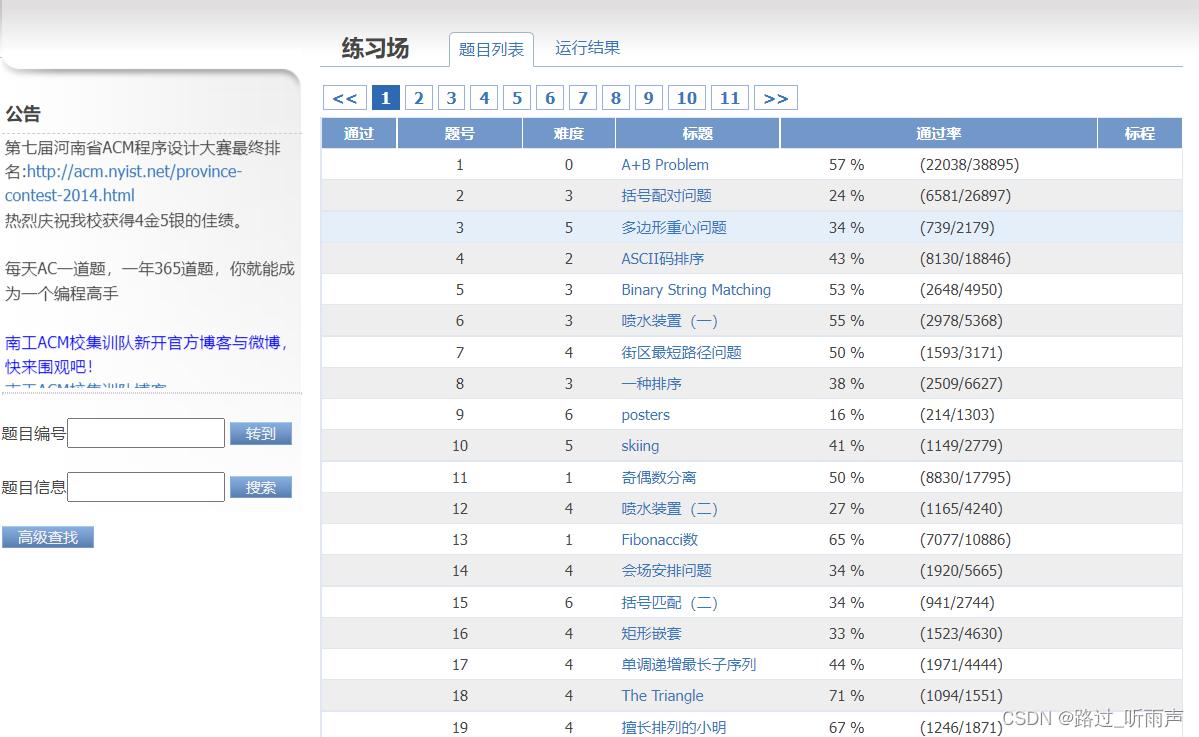
(一)页面分析
切换页面的时候url网址发生变动,因此切换页面时切换第n页则为n.html

根据页面数据显示可以查看到只有题号、难度、标题、通过率、存有数据,因此只需要对此四项数据进行爬取
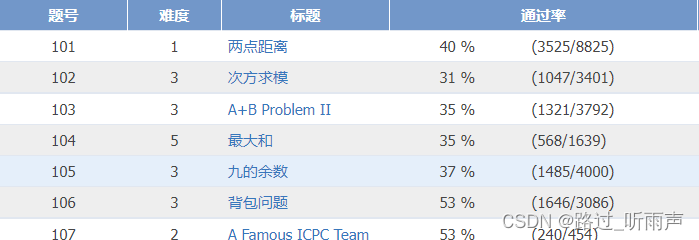
查看html代码:
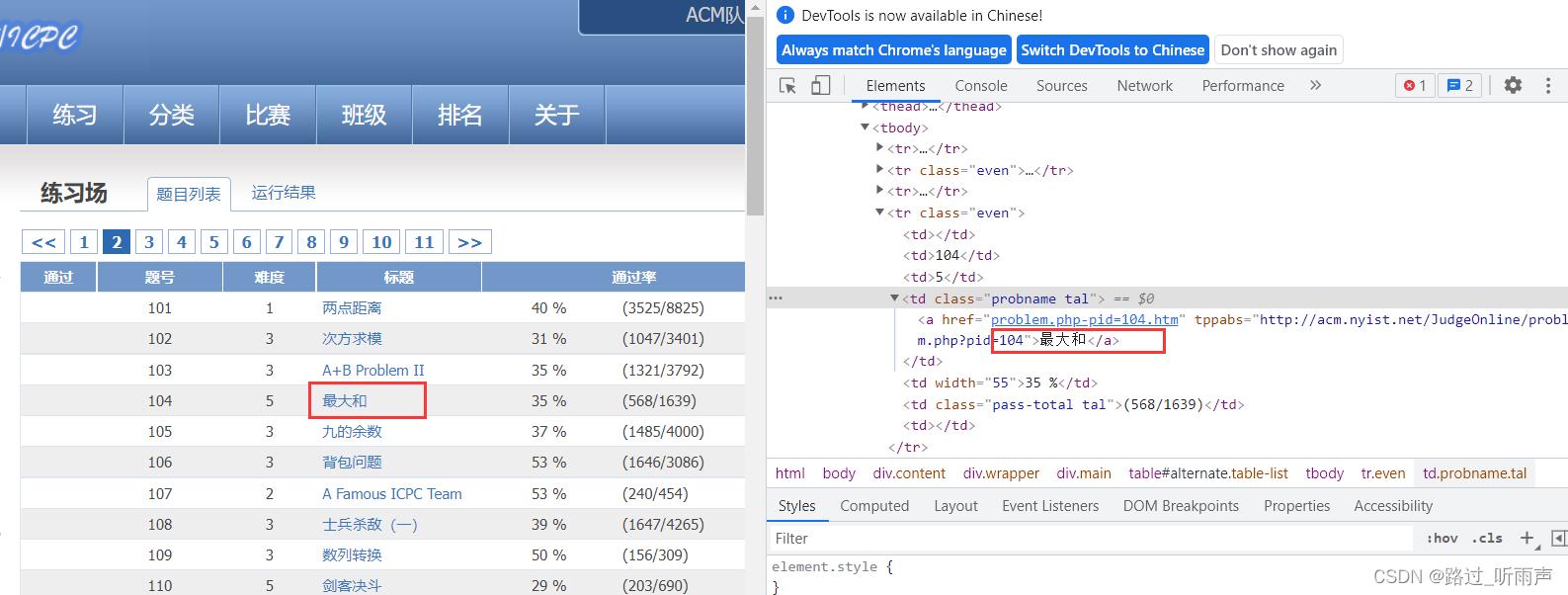
在每一个标签内都是<tr><td></td></tr>使用嵌套模式,因此可以使用爬虫进行爬取
(二)代码编写
导入相应的包
#导入包 import requests from bs4 import BeautifulSoup import csv from tqdm import tqdm#在电脑终端上显示进度,使代码可视化进度加快
定义访问浏览器所需的请求头和写入csv文件需要的表头及存储列表
# 模拟浏览器访问 Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400' # 题目数据 subjects = [] # 表头 csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
定义爬取函数,并删选信息
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')#讲所有含TD的项提取出来
subject = []
for t in td:
if t.string is not None:
#利用string方法获取其中的内容
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
写入文件
with open('D:/NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
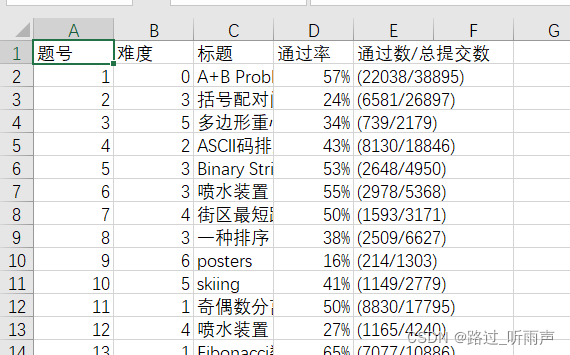
print('\n题目信息爬取完成!!!')
结果
三、爬取学校信息通知
网站地址:http://news.cqjtu.edu.cn/xxtz.htm

(一)页面分析
可以看到在html跳转采用 n-方式 因为为n-.html
爬取数据,日期+新闻题目

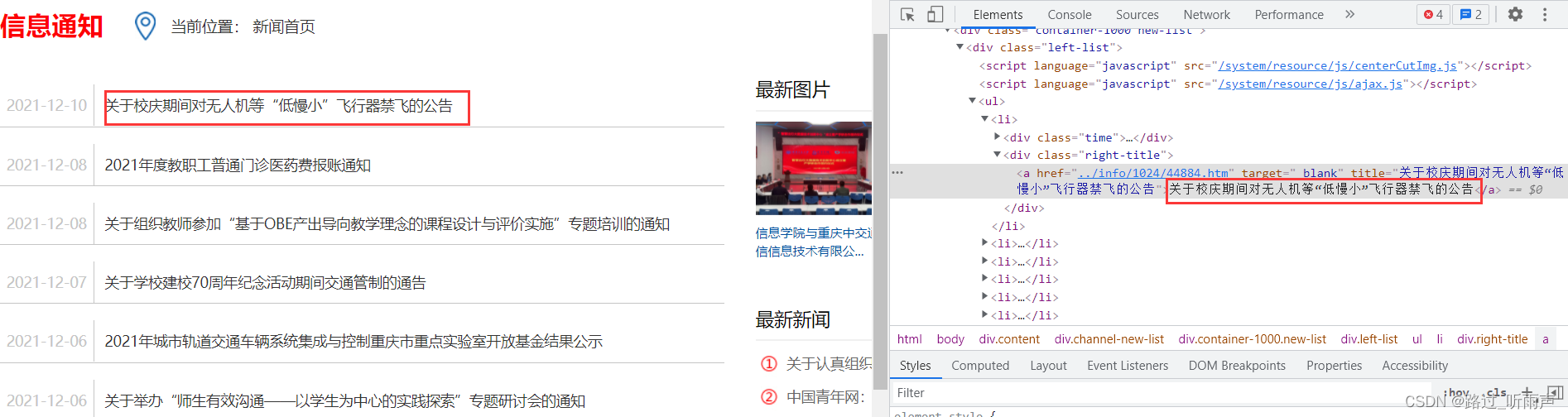
查看网页代码,标签信息<ul><li></li></ul>
数据条数

(二)代码编写
import requests
from bs4 import BeautifulSoup
import csv
# 获取每页内容
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
try:
info_list_page = [] # 一页的所有信息
resp = requests.get(url, headers=headers)
resp.encoding = resp.status_code
page_text = resp.text
soup = BeautifulSoup(page_text, 'lxml')
li_list = soup.select('.left-list > ul > li') # 找到所有li标签
for li in li_list:
divs = li.select('div')
date = divs[0].string.strip()
title = divs[1].a.string
info = [date, title]
info_list_page.append(info)
except Exception as e:
print('爬取' + url + '错误')
print(e)
return None
else:
resp.close()
print('爬取' + url + '成功')
return info_list_page
# main
def main():
# 爬取所有数据
info_list_all = []
base_url = 'http://news.cqjtu.edu.cn/xxtz/'
for i in range(1, 67):
if i == 1:
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url = base_url + str(67 - i) + '.htm'
info_list_page = get_one_page(url)
info_list_all += info_list_page
# 存入数据
with open('D:/教务新闻.csv', 'w', newline='', encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(['日期', '标题']) # 写入表头
fileWriter.writerows(info_list_all) # 写入数据
if __name__ == '__main__':
main()
结果:

总结:
本次实验对利用Python 进行爬虫进行了学习,并实现了对网站信息的爬取。
到此这篇关于Python爬虫练习汇总的文章就介绍到这了,更多相关Python爬虫练习内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫小练习之爬取并分析腾讯视频m3u8格式
目录 普通爬虫正常流程: 环境介绍 分析网站 开始代码 导入模块 数据请求 提取数据 遍历 保存数据 运行代码 普通爬虫正常流程: 数据来源分析 发送请求 获取数据 解析数据 保存数据 环境介绍 python 3.8 pycharm 2021专业版 [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看 分析网站 先打开开发者工具,然后搜索m3u8,会返回给你很多的ts的文件,像这种ts文件,就是视频的片段 我们可以复制url地址,在新的浏览页打开
-
Python爬虫分析汇总
目录 Python爬虫分析 一.程序说明 二.数据爬取 1.获取 CSDN 作者总榜数据 2.获取收藏夹列表 3.获取收藏数据 4.爬虫程序完整代码 5.爬取数据结果 三.数据分析及可视化 Python爬虫分析 前言: 计算机行业的发展太快了,有时候几天不学习,就被时代所抛弃了,因此对于我们程序员而言,最重要的就是要时刻紧跟业界动态变化,学习新的技术,但是很多时候我们又不知道学什么好,万一学的新技术并不会被广泛使用,太小众了对学习工作也帮助不大,这时候我们就想要知道大佬们都在学什么了,跟着大佬学
-
Python爬虫练习汇总
目录 一. 软件配置 二.爬取南阳理工OJ题目 (一)页面分析 (二)代码编写 三.爬取学校信息通知 (一)页面分析 (二)代码编写 一. 软件配置 安装必备爬虫环境软件: python 3.8 pip install requests pip install beautifulsoup4 二.爬取南阳理工OJ题目 网站地址:http://www.51mxd.cn/ (一)页面分析 切换页面的时候url网址发生变动,因此切换页面时切换第n页则为n.html 根据页面数据显示可以查看到只有题号.难
-
一些常用的Python爬虫技巧汇总
Python爬虫:一些常用的爬虫技巧总结 爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情. 1.基本抓取网页 get方法 import urllib2 url "http://www.baidu.com" respons = urllib2.urlopen(url) print response.read() post方法 import urllib import urllib2 url = "http://abcde.com" form = {
-
python编写简单爬虫资料汇总
爬虫真是一件有意思的事儿啊,之前写过爬虫,用的是urllib2.BeautifulSoup实现简单爬虫,scrapy也有实现过.最近想更好的学习爬虫,那么就尽可能的做记录吧.这篇博客就我今天的一个学习过程写写吧. 一 正则表达式 正则表达式是一个很强大的工具了,众多的语法规则,我在爬虫中常用的有: . 匹配任意字符(换行符除外) * 匹配前一个字符0或无限次 ? 匹配前一个字符0或1次 .* 贪心算法 .*? 非贪心算法 (.*?) 将匹配到的括号中的结果输出 \d 匹配数字 re.S 使得.可
-
Python爬虫实现网页信息抓取功能示例【URL与正则模块】
本文实例讲述了Python爬虫实现网页信息抓取功能.分享给大家供大家参考,具体如下: 首先实现关于网页解析.读取等操作我们要用到以下几个模块 import urllib import urllib2 import re 我们可以尝试一下用readline方法读某个网站,比如说百度 def test(): f=urllib.urlopen('http://www.baidu.com') while True: firstLine=f.readline() print firstLine 下面我们说
-
Python爬虫DNS解析缓存方法实例分析
本文实例讲述了Python爬虫DNS解析缓存方法.分享给大家供大家参考,具体如下: 前言: 这是Python爬虫中DNS解析缓存模块中的核心代码,是去年的代码了,现在放出来 有兴趣的可以看一下. 一般一个域名的DNS解析时间在10~60毫秒之间,这看起来是微不足道,但是对于大型一点的爬虫而言这就不容忽视了.例如我们要爬新浪微博,同个域名下的请求有1千万(这已经不算多的了),那么耗时在10~60万秒之间,一天才86400秒.也就是说单DNS解析这一项就用了好几天时间,此时加上DNS解析缓存,效果就
-
Python爬虫实现全国失信被执行人名单查询功能示例
本文实例讲述了Python爬虫实现全国失信被执行人名单查询功能.分享给大家供大家参考,具体如下: 一.需求说明 利用百度的接口,实现一个全国失信被执行人名单查询功能.输入姓名,查询是否在全国失信被执行人名单中. 二.python实现 版本1: # -*- coding:utf-8*- import sys reload(sys) sys.setdefaultencoding('utf-8') import time import requests time1=time.time() import
-
Python爬虫之正则表达式基本用法实例分析
本文实例讲述了Python爬虫之正则表达式基本用法.分享给大家供大家参考,具体如下: 一.简介 正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学的一个概念.正则表达式使用单个字符串来描述.匹配一系列匹配某个句法规则的字符串.在很多文本编辑器里,正则表达式通常被用来检索.替换那些匹配某个模式的文本. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表
-
Python爬虫框架Scrapy常用命令总结
本文实例讲述了Python爬虫框架Scrapy常用命令.分享给大家供大家参考,具体如下: 在Scrapy中,工具命令分为两种,一种为全局命令,一种为项目命令. 全局命令不需要依靠Scrapy项目就可以在全局中直接运行,而项目命令必须要在Scrapy项目中才可以运行 全局命令 全局命令有哪些呢,要想了解在Scrapy中有哪些全局命令,可以在不进入Scrapy项目所在目录的情况下,运行scrapy-h,如图所示: 可以看到,此时在可用命令在终端下展示出了常见的全局命令,分别为fetch.runspi
-
Python爬虫之pandas基本安装与使用方法示例
本文实例讲述了Python爬虫之pandas基本安装与使用方法.分享给大家供大家参考,具体如下: 一.简介: Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.pandas提供了大量能使我们快速便捷地处理数据的函数和方法.你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一. 官网: http: