python-xpath获取html文档的部分内容
有些时候我在们需要的用正则提取出html中某一个部分的文字内容,如图:
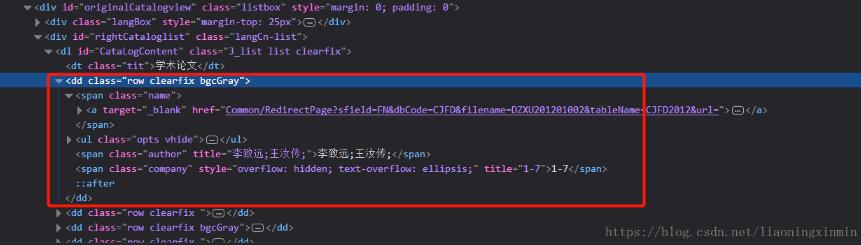
获取dd部分的html文档,我们要通过它的一个属性去确定他的位置才可以拿到他这个部分我们可以看到他的这个属性class='row clearfix ',然后用xpath去获取到这部分:
name = tree.xpath("//dd[@class='row clearfix ']")
from lxml import html
import requests
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
print(name)
如果直接打印他是不能够出来的,

我们需要对Element进行处理,用到name1 = html.tostring(name[0]),代码如下:
from lxml import html
import requests
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
name1 = html.tostring(name[0])
print(name1)
打印截图:

但是大家可以看到里面的等内容并不是中文,原因是我们使用tostring方法输出的是修正后的HTML代码,但是结果是bytes类型,在python中bytes类型是不可以进行编码的,需要转换成字符串,使用代码name1.decode(),此时我们将bytes类型转换为str(字符串)类型。
那么此时我们关键是如何将$#26080;此类的符号转换成汉字!!!那么首先要搞清楚这是什么编码?这类符号是HTML、XML 等 SGML 类语言的转义序列。它们不是”编码“,也就是说我们不能使用utf-8、gbk等编码进行处理,需要使用HTMLParse进行处理,完整代码如下:
from lxml import html
import requests
from html.parser import HTMLParser #导入html解析库
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
name1 = html.tostring(name[0])
name2 = HTMLParser().unescape(name1.decode())
print(name2)
此时运行结果如下:

那么此时就已经大功告成了!!!
以上这篇python-xpath获取html文档的部分内容就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python 中xpath爬虫实例详解
案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面. 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1.首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构.每一组"li"对应一组套图.属性href后面即为套图的内页地址(即广告盘链接页).所以,我们先得获取列表页内所有的内页地址(即广告盘链接页) 代码如下: import requests 倒入requests库 from lxml
-
用python3教你任意Html主内容提取功能
本文将和大家分享一些从互联网上爬取语料的经验. 0x1 工具准备 工欲善其事必先利其器,爬取语料的根基便是基于python. 我们基于python3进行开发,主要使用以下几个模块:requests.lxml.json. 简单介绍一个各模块的功能 01|requests requests是一个Python第三方库,处理URL资源特别方便.它的官方文档上写着大大口号:HTTP for Humans(为人类使用HTTP而生).相比python自带的urllib使用体验,笔者认为requests的使用体
-
python-xpath获取html文档的部分内容
有些时候我在们需要的用正则提取出html中某一个部分的文字内容,如图: 获取dd部分的html文档,我们要通过它的一个属性去确定他的位置才可以拿到他这个部分我们可以看到他的这个属性class='row clearfix ',然后用xpath去获取到这部分: name = tree.xpath("//dd[@class='row clearfix ']") from lxml import html import requests url = 'http://navi.cnki.net/
-
如何使用XPath提取xml文档数据
本文实例为大家分享了XPath提取xml文档数据具体代码,供大家参考,具体内容如下 import java.util.List; import org.dom4j.Document; import org.dom4j.Node; import org.dom4j.io.SAXReader; import org.junit.Test; /* * 使用XPath查找xml文档数据 * */ public class DemoXPath { @Test //输出book.xml中所有price元素节
-
使用python批量读取word文档并整理关键信息到excel表格的实例
目标 最近实验室里成立了一个计算机兴趣小组 倡议大家多把自己解决问题的经验记录并分享 就像在CSDN写博客一样 虽然刚刚起步 但考虑到后面此类经验记录的资料会越来越多 所以一开始就要做好模板设计(如下所示) 方便后面建立电子数据库 从而使得其他人可以迅速地搜索到相关记录 据说"人生苦短,我用python" 所以决定用python从docx文档中提取文件头的信息 然后把信息更新到一个xls电子表格中,像下面这样(直接po结果好了) 而且点击文件路径可以直接打开对应的文件(含超链接) 代码
-
python将txt文档每行内容循环插入数据库的方法
如下所示: import pymysql import time import re def get_raw_label(rece): re1 = r'"([\s\S]*?)": "' #-------------正则表达式 reg1 = re.compile(re1) # ------------编译一下 str1 = reg1.findall(rece) return str1 def get_detail(rece): re2 = r'": "([\
-
使用Python 自动生成 Word 文档的教程
当然要用第三方库啦 :) 使用以下命令安装: pip install python-docx 使用该库的基本步骤为: 1.建立一个文档对象(可自动使用默认模板建立,也可以使用已有文件). 2.设置文档的格式(默认字体.页面边距等). 3.在文档对象中加入段落文本.表格.图像等,并指定其样式. 4.保存文档. 注:本库仅支持生成Word2007以后版本的文档类型,即扩展名为.docx 的. 下面分步介绍其基本使用方法: 步骤一: from docx import Document doc = Do
-
Python数据库格式化输出文档的思路与方法
问题 如果文案格式是统一的,是否可以通过Python格式化输出doc/md的文档? 能用代码搞定的,尽力不手工 思路 首先,数据已经录入库,需要python能读取数据库,可使用mysql-connector 其次,格式化输出的文档,肯定需要文件读写操作,需使用os 接着,考虑到各大平台多数支持markdown格式,优先输出md格式文档.若输出doc,需使用docx 补充,python一键执行,分页数据操作,接收外部参数,需使用sys 编码 分页获取数据库内容 import mysql.conne
-

python读取pdf格式文档的实现代码
python读取pdf文档 一. 准备工作 安装对应的库 pip install pdfminer3k pip install pdfminer.six 二.部分变量的含义 PDFDocument(pdf文档对象) PDFPageInterpreter(解释器) PDFParser(pdf文档分析器) PDFResourceManager(资源管理器) PDFPageAggregator(聚合器) LAParams(参数分析器) 三.PDFMiner类之间的关系 PDFMiner的相关文档(点击
-
用Python实现给Word文档盖章
目录 模块分解 设置加粗 功能块练习 知识归纳与总结 总结 目标文件夹内有多份 Word 文件 ——[xxx涨薪通告.docx],我们需要在这些文档的末尾处添加公司的电子章与公司名称. 这次的任务困难吗?手动操作起来其实很简单,无非就是先打开一个文档,接着在结尾处添加文字盖章:并且插入电子章图片,然后另起一行,添加公司名称闪光科技金融公司(Shining Fintech Company),将公司名称的字号设置为四号,字体加粗,右对齐:完成这些操作后,复制这些文字和图片,最后保存文档. 实现代码:
-
Python批量对word文档进行操作步骤
目录 导读 应用 细节介绍 导读 前面几章我们以经介绍了怎么批量对excel和ppt操作今天我们说说对word文档的批量操作 应用 python-docx允许您创建新文档以及对现有文档进行更改.实际上,它只允许您对现有文档进行更改:只是如果您从一个没有任何内容的文档开始,一开始可能会觉得您是从头开始创建一个文档. 这个特性是一个强大的特性.文档的外观很大程度上取决于删除所有内容时留下的部分.样式.页眉和页脚等内容与主要内容分开包含,允许您在起始文档中进行大量自定义,然后出现在您生成的文档中. 让
-
Python中PyAutoGUI帮助文档(推荐!)
目录 1.简介 1.1 目的 1.2 例子 1.4 保护措施(Fail-Safes) 2 安装与依赖 3.速查表(小抄,Cheat Sheet) 3.1 常用函数 3.2 保护措施 3.3 鼠标函数 3.4 键盘函数 3.5 消息弹窗函数 3.6 截屏函数 4 常用函数 5 鼠标控制函数 5.1 屏幕与鼠标位置 5.2 鼠标行为 5.3 鼠标拖拽 5.4 缓动/渐变(Tween / Easing)函数 5.5 鼠标单击 5.6 鼠标按下和松开函数 5.7 滚轮滚动函数 6 键盘控制函数 6.1