python解释模型库Shap实现机器学习模型输出可视化
目录
- 安装所需的库
- 导入所需库
- 创建模型
- 创建可视化
- 1、Bar Plot
- 2、队列图
- 3、热图
- 4、瀑布图
- 5、力图
- 6、决策图
解释一个机器学习模型是一个困难的任务,因为我们不知道这个模型在那个黑匣子里是如何工作的。解释是必需的,这样我们可以选择最佳的模型,同时也使其健壮。
我们开始吧…
安装所需的库
使用pip安装Shap开始。下面给出的命令可以做到这一点。
pip install shap
导入所需库
在这一步中,我们将导入加载数据、创建模型和创建该模型的可视化所需的库。
df = pd.read_csv('/content/Diabetes.csv')
features = ['Pregnancies', 'Glucose','BloodPressure','SkinThickness','Insulin','BMI','DiabetesPedigreeFunction','Age']
Y = df['Outcome']
X = df[features]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 1234)
xgb_model = xgb.XGBRegressor(random_state=42)
xgb_model.fit(X_train, Y_train)
创建模型
在这一步中,我们将创建机器学习模型。在本文中,我将创建一个XGBoost模型,但是你可以选择任何模型。我们将用于此模型的数据集是著名的糖尿病数据集,可从Kaggle下载。
df = pd.read_csv('/content/Diabetes.csv')
features = ['Pregnancies', 'Glucose','BloodPressure','SkinThickness','Insulin','BMI','DiabetesPedigreeFunction','Age']
Y = df['Outcome']
X = df[features]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 1234)
xgb_model = xgb.XGBRegressor(random_state=42)
xgb_model.fit(X_train, Y_train)

创建可视化
现在我们将为shap创建解释程序,找出模型的shape值,并使用它们创建可视化效果。
explainer = shap.Explainer(xgb_model) shap_values = explainer(X_test)
1、Bar Plot
shap.plots.bar(shap_values, max_display=10)

2、队列图
shap.plots.bar(shap_values.cohorts(2).abs.mean(0))

3、热图
shap.plots.heatmap(shap_values[1:100])
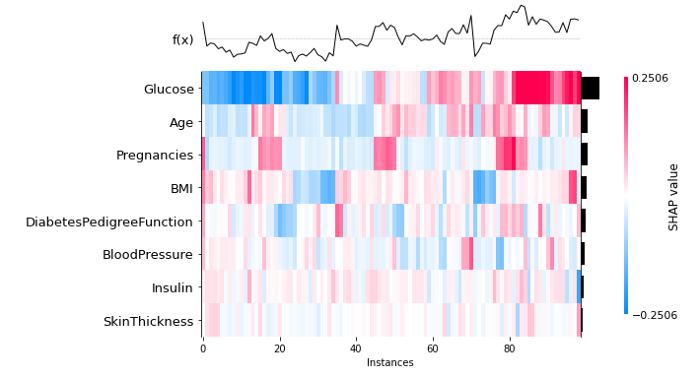
4、瀑布图
shap.plots.waterfall(shap_values[0]) # For the first observation
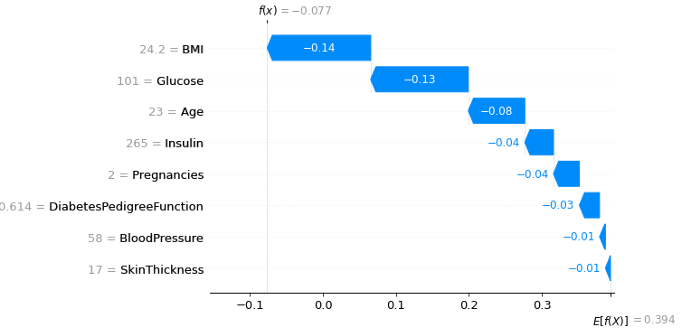
5、力图
shap.initjs()
explainer = shap.TreeExplainer(xgb_model)
shap_values = explainer.shap_values(X_test)
def p(j):
return(shap.force_plot(explainer.expected_value, shap_values[j,:], X_test.iloc[j,:]))
p(0)

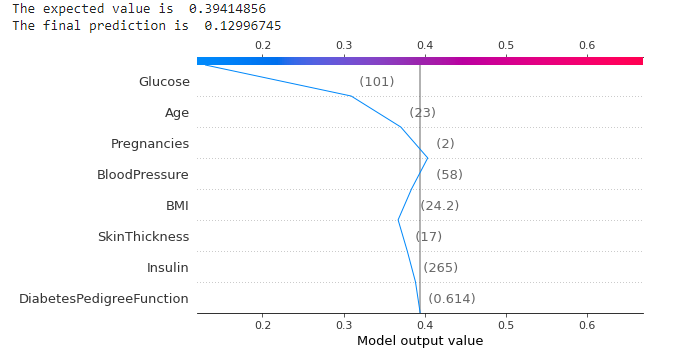
6、决策图
shap_values = explainer.shap_values(X_test)[1]
print("The expected value is ", expected_value)
print("The final prediction is ", xgb_model.predict(X_test)[1])
shap.decision_plot(expected_value, shap_values, X_test)
这就是如何使用 Shap 创建与机器学习模型相关的可视化并对其进行分析。
以上就是python解释模型库Shap实现机器学习模型输出可视化的详细内容,更多关于python解释模型库Shap模型输出可视化的资料请关注我们其它相关文章!
相关推荐
-

python机器学习使数据更鲜活的可视化工具Pandas_Alive
目录 安装方法 使用说明 支持示例展示 水平条形图 垂直条形图比赛 条形图 饼图 多边形地理空间图 多个图表 总结 数据动画可视化制作在日常工作中是非常实用的一项技能.目前支持动画可视化的库主要以Matplotlib-Animation为主,其特点为:配置复杂,保存动图容易报错. 安装方法 pip install pandas_alive # 或者 conda install pandas_alive -c conda-forge 使用说明 pandas_alive 的设计灵感来自 bar_ch
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
python数据挖掘使用Evidently创建机器学习模型仪表板
目录 1.安装包 2.导入所需的库 3.加载数据集 4.创建模型 5.创建仪表板 6.可用报告类型 1)数据漂移 2)数值目标漂移 3)分类目标漂移 4)回归模型性能 5)分类模型性能 6)概率分类模型性能 解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么.创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的. Evidently 是一个开源 Python 库,用于创建交互式可视化报告.仪表板和 JSON 配置文
-
提高python代码可读性利器pycodestyle使用详解
目录 关于PEP-8 目的 安装 基本用法 高级用法 结论 编程是数据科学中不可或缺的技能,虽然创建脚本来执行基本功能很容易,但编写大规模可读性良好的代码需要更多的思考. 关于PEP-8 pycodestyle 检查器提供基于 PEP-8 样式约定的代码建议.那么 PEP-8 到底是什么呢? PEP 代表 Python 增强建议,PEP-8 是一个概述编写 Python 代码最佳实践的指南.它的主要目标是通过标准化代码样式来提高代码的整体一致性和可读性. 目的 快速浏览一下PEP-8文档,就会发
-
python机器学习朴素贝叶斯算法及模型的选择和调优详解
目录 一.概率知识基础 1.概率 2.联合概率 3.条件概率 二.朴素贝叶斯 1.朴素贝叶斯计算方式 2.拉普拉斯平滑 3.朴素贝叶斯API 三.朴素贝叶斯算法案例 1.案例概述 2.数据获取 3.数据处理 4.算法流程 5.注意事项 四.分类模型的评估 1.混淆矩阵 2.评估模型API 3.模型选择与调优 ①交叉验证 ②网格搜索 五.以knn为例的模型调优使用方法 1.对超参数进行构造 2.进行网格搜索 3.结果查看 一.概率知识基础 1.概率 概率就是某件事情发生的可能性. 2.联合概率 包
-
python机器学习基础K近邻算法详解KNN
目录 一.k-近邻算法原理及API 1.k-近邻算法原理 2.k-近邻算法API 3.k-近邻算法特点 二.k-近邻算法案例分析案例信息概述 第一部分:处理数据 1.数据量缩小 2.处理时间 3.进一步处理时间 4.提取并构造时间特征 5.删除无用特征 6.签到数量少于3次的地点,删除 7.提取目标值y 8.数据分割 第二部分:特征工程 标准化 第三部分:进行算法流程 1.算法执行 2.预测结果 3.检验效果 一.k-近邻算法原理及API 1.k-近邻算法原理 如果一个样本在特征空间中的k个最相
-
pyCaret效率倍增开源低代码的python机器学习工具
目录 PyCaret 时间序列模块 加载数据 初始化设置 统计测试 探索性数据分析 模型训练和选择 保存模型 PyCaret 是一个开源.低代码的 Python 机器学习库,可自动执行机器学习工作流.它是一种端到端的机器学习和模型管理工具,可以以指数方式加快实验周期并提高您的工作效率.欢迎收藏学习,喜欢点赞支持,文末提供技术交流群. 与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,可用于仅用几行代码替换数百行代码. 这使得实验速度和效率呈指数级增长. PyCaret 本质上是围绕
-
python解释模型库Shap实现机器学习模型输出可视化
目录 安装所需的库 导入所需库 创建模型 创建可视化 1.Bar Plot 2.队列图 3.热图 4.瀑布图 5.力图 6.决策图 解释一个机器学习模型是一个困难的任务,因为我们不知道这个模型在那个黑匣子里是如何工作的.解释是必需的,这样我们可以选择最佳的模型,同时也使其健壮. 我们开始吧- 安装所需的库 使用pip安装Shap开始.下面给出的命令可以做到这一点. pip install shap 导入所需库 在这一步中,我们将导入加载数据.创建模型和创建该模型的可视化所需的库. df = pd
-
python人工智能human learn绘图可创建机器学习模型
目录 什么是 human-learn 安装 human-learn 互动绘图 创建模型并进行预测 预测新数据 解释结果 预测和评估测试数据 结论 如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则. 这些规则可用于预测新数据的标签. 这很方便,但是在此过程中可能会丢失一些信息.也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测. 除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则? 是的,这可以通过 human-l
-
python人工智能human learn绘图创建机器学习模型
目录 什么是 human-learn 安装 human-learn 互动绘图 创建模型并进行预测 预测新数据 解释结果 预测和评估测试数据 结论 如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则. 这些规则可用于预测新数据的标签. 这很方便,但是在此过程中可能会丢失一些信息.也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测. 除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则? 是的,这可以通过 human-l
-
Python OpenCV实战之与机器学习的碰撞
目录 0. 前言 1. 机器学习简介 1.1 监督学习 1.2 无监督学习 1.3 半监督学习 2. K均值 (K-Means) 聚类 2.1 K-Means 聚类示例 3. K最近邻 3.1 K最近邻示例 4. 支持向量机 4.1 支持向量机示例 小结 0. 前言 机器学习是人工智能的子集,它为计算机以及其它具有计算能力的系统提供自动预测或决策的能力,诸如虚拟助理.车牌识别系统.智能推荐系统等机器学习应用程序给我们的日常生活带来了便捷的体验.机器学习的蓬勃发展,得益于以下三个关键因素:1) 海
-
小白入门篇使用Python搭建点击率预估模型
点击率预估模型 0.前言 本篇是一个基础机器学习入门篇文章,帮助我们熟悉机器学习中的神经网络结构与使用. 日常中习惯于使用Python各种成熟的机器学习工具包,例如sklearn.TensorFlow等等,来快速搭建各种各样的机器学习模型来解决各种业务问题. 本文将从零开始,仅仅利用基础的numpy库,使用Python实现一个最简单的神经网络(或者说是简易的LR,因为LR就是一个单层的神经网络),解决一个点击率预估的问题. 1.假设一个业务场景 声明:为了简单起见,下面的一切设定从简-. 定义需
-
Python数据分析之使用scikit-learn构建模型
一.使用sklearn转换器处理 sklearn提供了model_selection模型选择模块.preprocessing数据预处理模块.decompisition特征分解模块,通过这三个模块能够实现数据的预处理和模型构建前的数据标准化.二值化.数据集的分割.交叉验证和PCA降维处理等工作. 1.加载datasets中的数据集 sklearn库的datasets模块集成了部分数据分析的经典数据集,可以选用进行数据预处理.建模的操作. 常见的数据集加载函数(器): 数据集加载函数(器) 数据集任
-
Python解释执行原理分析
本文较为详细的分析了Python解释执行的原理,对于深入理解Python可以起到一定的帮助作用.具体分析如下: 首先,这里的解释执行是相对于编译执行而言的.我们都知道,使用C/C++之类的编译性语言编写的程序,是需要从源文件转换成计算机使用的机器语言,经过链接器链接之后形成了二进制的可执行文件.运行该程序的时候,就可以把二进制程序从硬盘载入到内存中并运行. 但是对于Python而言,python源码不需要编译成二进制代码,它可以直接从源代码运行程序.当我们运行python文件程序的时候,pyth
-
Python数学建模StatsModels统计回归模型数据的准备
目录 1.读取数据文件 (1)读取 .csv 文件: (2)读取 .xls 文件: (3)读取 .txt 文件: 2.数据文件的拆分与合并 (1)将 Excel 文件分割为多个文件 (2)将 多个 Excel 文件合并为一个文件 3.数据的预处理 (1)缺失数据的处理 (2)重复数据的处理 (3)异常值处理 4.Python 例程(Statsmodels) 4.1 问题描述 4.2 Python 程序 4.3 程序运行结果: 版权说明: 1.读取数据文件 回归分析问题所用的数据都是保存在数据文件
-
Python源码加密与Pytorch模型加密分别介绍
目录 前言 一.python源代码的保护 二.pytorch模型.pth的加密 前言 深度学习领域,常常用python写代码,而且是建立在一些开源框架之上,如pytorch.在实际的项目部署中,也有用conda环境和python代码去部署服务器,在这个时候,又分为两种情况. 部署方式可分为两种,一种是在线部署,算法服务器归公司所有,只开放API给客户,客户通过POST请求访问算法服务器,上传数据并得到返回结果.这种情况客户当然看不到代码.还有一种是离线部署,就是给客户私有化部署,把公司的代码放到