python在线编译器的简单原理及简单实现代码
我们先来看一下效果(简单的写了一个):
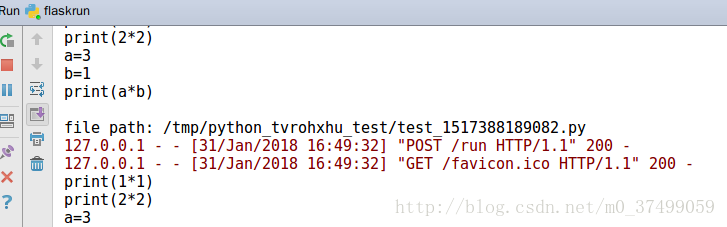


原理:将post请求的代码数据写入了服务器的一个文件,然后用服务器的python编译器执行返回结果
实现代码:
#flaskrun.py
# -*- coding: utf-8 -*-
# __author__="ZJL"
from flask import Flask
from flask import request
from flask import Response
import json
import zxby
app = Flask(__name__)
def Response_headers(content):
resp = Response(content)
resp.headers['Access-Control-Allow-Origin'] = '*'
return resp
@app.route('/')
def hello_world():
return Response_headers('hello world!!!')
@app.route('/run', methods=['POST'])
def run():
if request.method == 'POST' and request.form['code']:
code = request.form['code']
print(code)
jsondata = zxby.main(code)
return Response_headers(str(jsondata))
@app.errorhandler(403)
def page_not_found(error):
content = json.dumps({"error_code": "403"})
resp = Response_headers(content)
return resp
@app.errorhandler(404)
def page_not_found(error):
content = json.dumps({"error_code": "404"})
resp = Response_headers(content)
return resp
@app.errorhandler(400)
def page_not_found(error):
content = json.dumps({"error_code": "400"})
resp = Response_headers(content)
return resp
@app.errorhandler(405)
def page_not_found(error):
content = json.dumps({"error_code": "405"})
resp = Response_headers(content)
return resp
@app.errorhandler(410)
def page_not_found(error):
content = json.dumps({"error_code": "410"})
resp = Response_headers(content)
return resp
@app.errorhandler(500)
def page_not_found(error):
content = json.dumps({"error_code": "500"})
resp = Response_headers(content)
return resp
if __name__ == '__main__':
app.run(debug=True)
#zxby.py
# -*- coding: utf-8 -*-
# __author__="ZJL"
import os, sys, subprocess, tempfile, time
# 创建临时文件夹,返回临时文件夹路径
TempFile = tempfile.mkdtemp(suffix='_test', prefix='python_')
# 文件名
FileNum = int(time.time() * 1000)
# python编译器位置
EXEC = sys.executable
# 获取python版本
def get_version():
v = sys.version_info
version = "python %s.%s" % (v.major, v.minor)
return version
# 获得py文件名
def get_pyname():
global FileNum
return 'test_%d' % FileNum
# 接收代码写入文件
def write_file(pyname, code):
fpath = os.path.join(TempFile, '%s.py' % pyname)
with open(fpath, 'w', encoding='utf-8') as f:
f.write(code)
print('file path: %s' % fpath)
return fpath
# 编码
def decode(s):
try:
return s.decode('utf-8')
except UnicodeDecodeError:
return s.decode('gbk')
# 主执行函数
def main(code):
r = dict()
r["version"] = get_version()
pyname = get_pyname()
fpath = write_file(pyname, code)
try:
# subprocess.check_output 是 父进程等待子进程完成,返回子进程向标准输出的输出结果
# stderr是标准输出的类型
outdata = decode(subprocess.check_output([EXEC, fpath], stderr=subprocess.STDOUT, timeout=5))
except subprocess.CalledProcessError as e:
# e.output是错误信息标准输出
# 错误返回的数据
r["code"] = 'Error'
r["output"] = decode(e.output)
return r
else:
# 成功返回的数据
r['output'] = outdata
r["code"] = "Success"
return r
finally:
# 删除文件(其实不用删除临时文件会自动删除)
try:
os.remove(fpath)
except Exception as e:
exit(1)
if __name__ == '__main__':
code = "print(11);print(22)"
print(main(code))
运行app.run()方法,通过post提交代码,就ok了。我们可以对输出结过做进一步的处理,我这只是为了解一下原理,就没继续了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python在线编译器的简单原理及简单实现代码
我们先来看一下效果(简单的写了一个): 原理:将post请求的代码数据写入了服务器的一个文件,然后用服务器的python编译器执行返回结果 实现代码: #flaskrun.py # -*- coding: utf-8 -*- # __author__="ZJL" from flask import Flask from flask import request from flask import Response import json import zxby app = Flask(
-
python开发一个解析protobuf文件的简单编译器
引言 最近刚刚用python写完了一个解析protobuf文件的简单编译器,深感ply实现词法分析和语法分析的简洁方便.乘着余热未过,头脑清醒,记下一点总结和心得,方便各位pythoner参考使用. ply使用 简介 如果你不是从事编译器或者解析器的开发工作,你可能从未听说过ply.ply是基于python的lex和yacc,而它的作者就是大名鼎鼎Python Cookbook, 3rd Edition的作者.可能有些朋友就纳闷了,我一个业务开发怎么需要自己写编译器呢,各位编程大牛说过,中央决定
-
python实现决策树、随机森林的简单原理
本文申明:此文为学习记录过程,中间多处引用大师讲义和内容. 一.概念 决策树(Decision Tree)是一种简单但是广泛使用的分类器.通过训练数据构建决策树,可以高效的对未知的数据进行分类.决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析:2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度. 看了一遍概念后,我们先从一个简单的案例开始,如下图我们样本: 对于上面的样本数据,根据不同特征值我们最后是选择是否约会,我们先自定义的一个决策树
-
Python装饰器原理与简单用法实例分析
本文实例讲述了Python装饰器原理与简单用法.分享给大家供大家参考,具体如下: 今天整理装饰器,内嵌的装饰器.让装饰器带参数等多种形式,非常复杂,让人头疼不已.但是突然间发现了装饰器的奥秘,原来如此简单.... 第一步 :从最简单的例子开始 # -*- coding:gbk -*- '''示例1: 使用语法糖@来装饰函数,相当于"myfunc = deco(myfunc)" 但发现新函数只在第一次被调用,且原函数多调用了一次''' def deco(func): print(&quo
-
Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc
-
Python K-means实现简单图像聚类的示例代码
这里直接给出第一个版本的直接实现: import os import numpy as np from sklearn.cluster import KMeans import cv2 from imutils import build_montages import matplotlib.image as imgplt image_path = [] all_images = [] images = os.listdir('./images') for image_name in images
-
PHP观察者模式原理与简单实现方法示例
本文实例讲述了PHP观察者模式原理与简单实现方法.分享给大家供大家参考,具体如下: 当一个对象状态发生改变后,会影响到其他几个对象的改变,这时候可以用观察者模式.像wordpress这样的应用程序中,它容外部开发组开发插件,比如用户授权的博客统计插件.积分插件,这时候可以应用观察者模式,先注册这些插件,当用户发布一篇博文后,就回自动通知相应的插件更新. 观察者模式符合接口隔离原则,实现了对象之间的松散耦合. 观察者模式UML图: 在php SPL中已经提供SplSubject和SqlOberve
-
Python+MongoDB自增键值的简单实现
背景 最近在写一个测试工具箱,里面有一个bug记录系统,因为后台我是用Django和MongoDB来实现的,就遇到了一个问题,要如何实现一个自增的字段. 传统的关系型数据库要实现起来是非常容易,只要直接设置一个自增字段就行了,插入数据时不用管这个键值,只管自己处理的数据就行了,会自动实现自增的功能,但是非关系型数据库好像没有这个功能(或者我不知道).百度之后发现都是MongoDB的设置方法,并不是我想要的. 解决思路 百度没有找到好的思路,那就只能自己解决了,我的想法很简单,字段不会自增,那么就
-
Javascript 拖拽的一些简单的应用(逐行分析代码,让你轻松了拖拽的原理)
今天我们来看看如何让拖拽的物体不能拖出某个div之外和拖拽的吸附功能 上次讲到我们的拖拽是不可拖出可视区范围的,在这基础上我们加个父级的div,不让他拖出父级.原理和之前的一样,简单吧. html代码: <div id="div2"> <div id="div1"> </div> </div> css代码: <style type="text/css"> #div1 { width: 1
-
python中json格式数据输出的简单实现方法
主要使用json模块,直接导入import json即可. 小例子如下: #coding=UTF-8 import json info={} info["code"]=1 info["id"]=1900 info["name"]='张三' info["sex"]='男' list=[info,info,info] data={} data["code"]=1 data["id"]=190