spring集成mybatis实现mysql数据库读写分离
前言
在网站的用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈。幸运的是目前大部分的主流数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库的数据更新同步到另一台服务器上。网站利用数据库的这一功能,实现数据库读写分离,从而改善数据库负载压力。如下图所示:
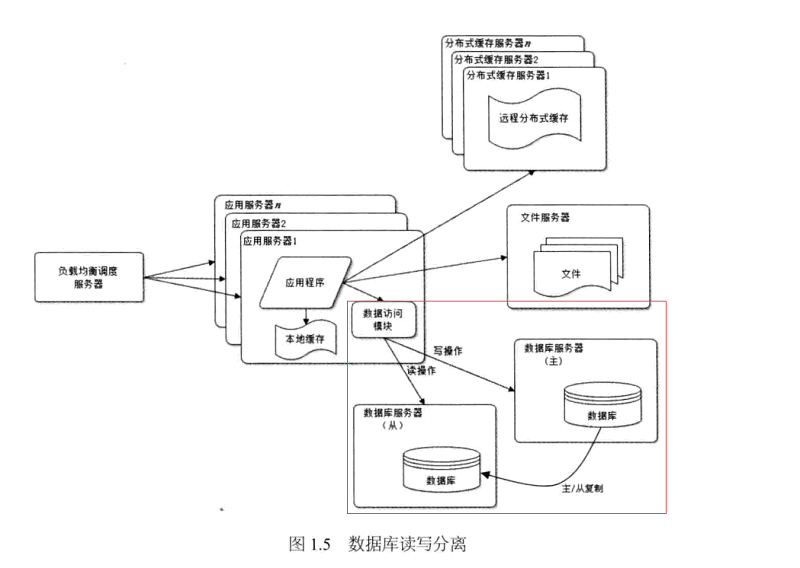
应用服务器在写数据的时候,访问主数据库,主数据库通过主从复制机制将数据更新同步到从数据库,这样当应用服务器读数据的时候,就可以通过从数据库获得数据。为了便于应用程序访问读写分离后的数据库,通常在应用服务器使用专门的数据库访问模块,使数据库读写分离对应用透明。
而本博客就是来实现“专门的数据库访问模块”,使数据库读写分离对应用透明。另外,mysql数据库的主从复制可以参考我的mysql5.7.18的安装与主从复制。注意,数据库实现了主从复制,才能做数据库的读写分离,所以,没有实现数据库主从复制的记得先去实现数据库的主从复制
配置读写数据源(主从数据库)
mysqldb.properties
#主数据库数据源 jdbc.driverClassName=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://192.168.0.4:3306/mybatis?useUnicode=true&characterEncoding=utf-8&useSSL=false jdbc.username=root jdbc.password=123456 jdbc.initialSize=1 jdbc.minIdle=1 jdbc.maxActive=20 jdbc.maxWait=60000 jdbc.removeAbandoned=true jdbc.removeAbandonedTimeout=180 jdbc.timeBetweenEvictionRunsMillis=60000 jdbc.minEvictableIdleTimeMillis=300000 jdbc.validationQuery=SELECT 1 jdbc.testWhileIdle=true jdbc.testOnBorrow=false jdbc.testOnReturn=false #从数据库数据源 slave.jdbc.driverClassName=com.mysql.jdbc.Driver slave.jdbc.url=jdbc:mysql://192.168.0.221:3306/mybatis?useUnicode=true&characterEncoding=utf-8&useSSL=false slave.jdbc.username=root slave.jdbc.password=123456 slave.jdbc.initialSize=1 slave.jdbc.minIdle=1 slave.jdbc.maxActive=20 slave.jdbc.maxWait=60000 slave.jdbc.removeAbandoned=true slave.jdbc.removeAbandonedTimeout=180 slave.jdbc.timeBetweenEvictionRunsMillis=60000 slave.jdbc.minEvictableIdleTimeMillis=300000 slave.jdbc.validationQuery=SELECT 1 slave.jdbc.testWhileIdle=true slave.jdbc.testOnBorrow=false slave.jdbc.testOnReturn=false
主、从数据库的地址记得改成自己的,账号和密码也需要改成自己的;其他配置项,大家可以酌情自行设置
mybatis-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd">
<!-- master数据源 -->
<bean id="masterDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<!-- 基本属性 url、user、password -->
<property name="driverClassName" value="${jdbc.driverClassName}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<property name="initialSize" value="${jdbc.initialSize}" />
<property name="minIdle" value="${jdbc.minIdle}" />
<property name="maxActive" value="${jdbc.maxActive}" />
<property name="maxWait" value="${jdbc.maxWait}" />
<!-- 超过时间限制是否回收 -->
<property name="removeAbandoned" value="${jdbc.removeAbandoned}" />
<!-- 超过时间限制多长; -->
<property name="removeAbandonedTimeout" value="${jdbc.removeAbandonedTimeout}" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="${jdbc.timeBetweenEvictionRunsMillis}" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="${jdbc.minEvictableIdleTimeMillis}" />
<!-- 用来检测连接是否有效的sql,要求是一个查询语句-->
<property name="validationQuery" value="${jdbc.validationQuery}" />
<!-- 申请连接的时候检测 -->
<property name="testWhileIdle" value="${jdbc.testWhileIdle}" />
<!-- 申请连接时执行validationQuery检测连接是否有效,配置为true会降低性能 -->
<property name="testOnBorrow" value="${jdbc.testOnBorrow}" />
<!-- 归还连接时执行validationQuery检测连接是否有效,配置为true会降低性能 -->
<property name="testOnReturn" value="${jdbc.testOnReturn}" />
</bean>
<!-- slave数据源 -->
<bean id="slaveDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${slave.jdbc.driverClassName}" />
<property name="url" value="${slave.jdbc.url}" />
<property name="username" value="${slave.jdbc.username}" />
<property name="password" value="${slave.jdbc.password}" />
<property name="initialSize" value="${slave.jdbc.initialSize}" />
<property name="minIdle" value="${slave.jdbc.minIdle}" />
<property name="maxActive" value="${slave.jdbc.maxActive}" />
<property name="maxWait" value="${slave.jdbc.maxWait}" />
<property name="removeAbandoned" value="${slave.jdbc.removeAbandoned}" />
<property name="removeAbandonedTimeout" value="${slave.jdbc.removeAbandonedTimeout}" />
<property name="timeBetweenEvictionRunsMillis" value="${slave.jdbc.timeBetweenEvictionRunsMillis}" />
<property name="minEvictableIdleTimeMillis" value="${slave.jdbc.minEvictableIdleTimeMillis}" />
<property name="validationQuery" value="${slave.jdbc.validationQuery}" />
<property name="testWhileIdle" value="${slave.jdbc.testWhileIdle}" />
<property name="testOnBorrow" value="${slave.jdbc.testOnBorrow}" />
<property name="testOnReturn" value="${slave.jdbc.testOnReturn}" />
</bean>
<!-- 动态数据源,根据service接口上的注解来决定取哪个数据源 -->
<bean id="dataSource" class="com.yzb.util.DynamicDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<!-- write or slave -->
<entry key="slave" value-ref="slaveDataSource"/>
<!-- read or master -->
<entry key="master" value-ref="masterDataSource"/>
</map>
</property>
<property name="defaultTargetDataSource" ref="masterDataSource"/>
</bean>
<!-- Mybatis文件 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="configLocation" value="classpath:mybatis-config.xml" />
<property name="dataSource" ref="dataSource" />
<!-- 映射文件路径 -->
<property name="mapperLocations" value="classpath*:dbmappers/*.xml" />
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.yzb.dao" />
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" />
</bean>
<!-- 事务管理器 -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 声明式开启 -->
<tx:annotation-driven transaction-manager="transactionManager" proxy-target-class="true" order="1"/>
<!-- 为业务逻辑层的方法解析@DataSource注解 为当前线程的HandleDataSource注入数据源 -->
<bean id="dataSourceAspect" class="com.yzb.util.DataSourceAspect" />
<aop:config proxy-target-class="true">
<aop:aspect id="dataSourceAspect" ref="dataSourceAspect" order="2">
<aop:pointcut id="tx" expression="execution(* com.yzb.service.impl..*.*(..)) "/>
<aop:before pointcut-ref="tx" method="before" />
</aop:aspect>
</aop:config>
</beans>
AOP实现数据源的动态切换
DataSource.java
package com.yzb.util;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* RUNTIME
* 编译器将把注释记录在类文件中,在运行时 VM 将保留注释,因此可以反射性地读取。
*
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface DataSource
{
String value();
}
DataSourceAspect.java
package com.yzb.util;
import java.lang.reflect.Method;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.reflect.MethodSignature;
public class DataSourceAspect
{
/**
* 在dao层方法获取datasource对象之前,在切面中指定当前线程数据源
*/
public void before(JoinPoint point)
{
Object target = point.getTarget();
String method = point.getSignature().getName();
Class<?>[] classz = target.getClass().getInterfaces(); // 获取目标类的接口, 所以@DataSource需要写在接口上
Class<?>[] parameterTypes = ((MethodSignature) point.getSignature())
.getMethod().getParameterTypes();
try
{
Method m = classz[0].getMethod(method, parameterTypes);
if (m != null && m.isAnnotationPresent(DataSource.class))
{
DataSource data = m.getAnnotation(DataSource.class);
System.out.println("用户选择数据库库类型:" + data.value());
HandleDataSource.putDataSource(data.value()); // 数据源放到当前线程中
}
} catch (Exception e)
{
e.printStackTrace();
}
}
}
DynamicDataSource.java
package com.yzb.util;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
public class DynamicDataSource extends AbstractRoutingDataSource
{
/**
* 获取与数据源相关的key 此key是Map<String,DataSource> resolvedDataSources 中与数据源绑定的key值
* 在通过determineTargetDataSource获取目标数据源时使用
*/
@Override
protected Object determineCurrentLookupKey()
{
return HandleDataSource.getDataSource();
}
}
HandleDataSource.java
package com.yzb.util;
public class HandleDataSource
{
public static final ThreadLocal<String> holder = new ThreadLocal<String>();
/**
* 绑定当前线程数据源
*
* @param key
*/
public static void putDataSource(String datasource)
{
holder.set(datasource);
}
/**
* 获取当前线程的数据源
*
* @return
*/
public static String getDataSource()
{
return holder.get();
}
}
service接口上应用@DataSource实现数据源的指定
package com.yzb.service;
import java.util.List;
import com.yzb.model.Person;
import com.yzb.util.DataSource;
public interface IPersonService {
/**
* 加载全部的person
* @return
*/
List<Person> listAllPerson();
/**
* 查询某个人的信息
* @param personId
* @return
*/
@DataSource("slave") // 指定使用从数据源
Person getPerson(int personId);
boolean updatePerson(Person person);
}
注意点
测试的时候,怎么样知道读取的是从数据库了? 我们可以修改从数据库中查询到的那条记录的某个字段的值,以区分主、从数据库;
事务需要注意,尽量保证在一个数据源上进行事务;
当某个service上有多个aop时,需要注意aop织入的顺序问题,利用order关键字控制好织入顺序;
项目完整工程github地址:https://github.com/youzhibing/maven-ssm-web,工程中实现了redis缓存,不去访问:http://localhost:8080/maven-ssm-web/personController/showPerson是没有问题的,当然你可以redis服务搭建起来并集成进来;
测试url:http://localhost:8080/maven-ssm-web/personController/person?personId=1
总结
以上所述是小编给大家介绍的spring集成mybatis实现mysql数据库读写分离,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

springboot配置内存数据库H2教程详解
业务背景:因soa系统要供外网访问,处于安全考虑用springboot做了个前置模块,用来转发外网调用的请求和soa返回的应答.其中外网的请求接口地址在DB2数据库中对应专门的一张表来维护,要是springboot直接访问数据库,还要专门申请权限等,比较麻烦,而一张表用内置的H2数据库维护也比较简单,就可以作为替代的办法. 环境:springboot+maven3.3+jdk1.7 1.springboot的Maven工程结构 说明一下,resource下的templates文件夹没啥用.我忘记
-
Spring+Mybatis 实现aop数据库读写分离与多数据库源配置操作
在数据库层面大都采用读写分离技术,就是一个Master数据库,多个Slave数据库.Master库负责数据更新和实时数据查询,Slave库当然负责非实时数据查询.因为在实际的应用中,数据库都是读多写少(读取数据的频率高,更新数据的频率相对较少),而读取数据通常耗时比较长,占用数据库服务器的CPU较多,从而影响用户体验.我们通常的做法就是把查询从主库中抽取出来,采用多个从库,使用负载均衡,减轻每个从库的查询压力. 废话不多说,多数据源配置和主从数据配置原理一样 1.首先配置 jdbc.prope
-
Spring Boot集成MyBatis访问数据库的方法
基于spring boot开发的微服务应用,与MyBatis如何集成? 集成方法 可行的方法有: 1.基于XML或者Java Config,构建必需的对象,配置MyBatis. 2.使用MyBatis官方提供的组件,实现MyBatis的集成. 方法一 建议参考如下文章,完成集成的验证. MyBatis学习 之 一.MyBatis简介与配置MyBatis+Spring+MySql 基于Spring + Spring MVC + Mybatis 高性能web构建 spring与mybatis三种整合
-
Spring MVC配置双数据源实现一个java项目同时连接两个数据库的方法
前言 本文主要介绍的是关于Spring MVC配置双数据源实现一个java项目同时连接两个数据库的方法,分享出来供大家参考学习,下面来看看详细的介绍: 实现方法: 数据源在配置文件中的配置 <pre name="code" class="java"><?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.spring
-
SpringMVC4+MyBatis+SQL Server2014实现数据库读写分离
前言 基于mybatis的AbstractRoutingDataSource和Interceptor用拦截器的方式实现读写分离,根据MappedStatement的boundsql,查询sql的select.insert.update.delete,根据起判断使用读写连接串. 开发环境 SpringMVC4.mybatis3 项目结构 读写分离实现 1.pom.xml <dependencies> <dependency> <groupId>junit</grou
-
详解spring整合shiro权限管理与数据库设计
之前的文章中我们完成了基础框架的搭建,现在基本上所有的后台系统都逃不过权限管理这一块,这算是一个刚需了.现在我们来集成shiro来达到颗粒化权限管理,也就是从连接菜单到页面功能按钮,都进行权限都验证,从前端按钮的显示隐藏,到后台具体功能方法的权限验证. 首先要先设计好我们的数据库,先来看一张比较粗糙的数据库设计图: 具体的数据库设计代码 /* Navicat MySQL Data Transfer Source Server : 本机 Source Server Version : 50537
-
Spring jdbc中数据库操作对象化模型的实例详解
Spring jdbc中数据库操作对象化模型的实例详解 Spring Jdbc数据库操作对象化 使用面向对象方式表示关系数据库的操作,实现一个线程安全可复用的对象模型,其顶级父类接口RdbmsOperation. SqlOperation继承该接口,实现数据库的select, update, call等操作. 1.查询接口:SqlQuery 1) GenericSqlQuery, UpdatableSqlQuery, MappingSqlQueryWithParameter 2) SqlUpda
-
spring集成mybatis实现mysql数据库读写分离
前言 在网站的用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈.幸运的是目前大部分的主流数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库的数据更新同步到另一台服务器上.网站利用数据库的这一功能,实现数据库读写分离,从而改善数据库负载压力.如下图所示: 应用服务器在写数据的时候,访问主数据库,主数据库通过主从复制机制将数据更新同步到从数据库,这样当应用服务器读数据的时候,就可以通过从数据库获得数据.为了便于应用程序访问读写分离后的数据库,通常在应用服务器使用专门的数
-
Python web框架(django,flask)实现mysql数据库读写分离的示例
读写分离,顾名思义,我们可以把读和写两个操作分开,减轻数据的访问压力,解决高并发的问题. 那么我们今天就Python两大框架来做这个读写分离的操作. 1.Django框架实现读写分离 Django做读写分离非常的简单,直接在settings.py中把从机加入到数据库的配置文件中就可以了. DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'HOST': '127.0.0.1', # 主服务器的运行ip 'PORT':
-
使用Spring AOP实现MySQL数据库读写分离案例分析(附demo)
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库的主从配置,最简单的是一台Master和一台Slave(大型网站系统的话,当然会很复杂,这里只是分析了最简单的情况).通过主从配置主从数据库保持了相同的数据,我们在进行读操作的时候访问从数据库Slave,在进行写操作的时候访问主数据库Master.这样的话就减轻了一台服务器的压力. 在进行读写分离
-
详解如何利用amoeba(变形虫)实现mysql数据库读写分离
关于mysql的读写分离架构有很多,百度的话几乎都是用mysql_proxy实现的.由于proxy是基于lua脚本语言实现的,所以网上不少网友表示proxy效率不高,也不稳定,不建议在生产环境使用: amoeba是阿里开发的一款数据库读写分离的项目(读写分离只是它的一个小功能),由于是基于java编写的,所以运行环境需要安装jdk: 前期准备工作: 1.两个数据库,一主一从,主从同步: master: 172.22.10.237:3306 :主库负责写入操作: slave: 10.4.66.58
-
thinkphp下MySQL数据库读写分离代码剖析
当采用原生态的sql语句进行写入操作的时候,要用execute,读操作要用query. MySQL数据主从同步还是要靠MySQL的机制来实现,所以这个时候MySQL主从同步的延迟问题是需要优化,延迟时间太长不仅影响业务,还影响用户体验. thinkphp核心类Thinkphp/library/Model.class.php 中,query 方法,调用Thinkphp/library/Think/Db/Driver/Mysql.class.php /** * SQL查询 * @access pub
-
利用mycat实现mysql数据库读写分离的示例
什么是MyCAT 一个彻底开源的,面向企业应用开发的大数据库集群 支持事务.ACID.可以替代MySQL的加强版数据库 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群 一个融合内存缓存技术.NoSQL技术.HDFS大数据的新型SQL Server 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品 一个新颖的数据库中间件产品 MyCAT关键特性 支持SQL92标准 支持MySQL.Oracle.DB2.SQL Server.PostgreSQL等DB的常见SQL
-
Spring+MyBatis实现数据库读写分离方案
推荐第四种 方案1 通过MyBatis配置文件创建读写分离两个DataSource,每个SqlSessionFactoryBean对象的mapperLocations属性制定两个读写数据源的配置文件.将所有读的操作配置在读文件中,所有写的操作配置在写文件中. 优点:实现简单 缺点:维护麻烦,需要对原有的xml文件进行重新修改,不支持多读,不易扩展 实现方式 <bean id="abstractDataSource" abstract="true" class=
-
springboot基于Mybatis mysql实现读写分离
近日工作任务较轻,有空学习学习技术,遂来研究如果实现读写分离.这里用博客记录下过程,一方面可备日后查看,同时也能分享给大家(网上的资料真的大都是抄来抄去,,还不带格式的,看的真心难受). 完整代码:https://github.com/FleyX/demo-project/tree/master/dxfl 1.背景 一个项目中数据库最基础同时也是最主流的是单机数据库,读写都在一个库中.当用户逐渐增多,单机数据库无法满足性能要求时,就会进行读写分离改造(适用于读多写少),写操作一个库,读操作多个库
-
Spring AOP切面解决数据库读写分离实例详解
Spring AOP切面解决数据库读写分离实例详解 为了减轻数据库的压力,一般会使用数据库主从(master/slave)的方式,但是这种方式会给应用程序带来一定的麻烦,比如说,应用程序如何做到把数据写到master库,而读取数据的时候,从slave库读取.如果应用程序判断失误,把数据写入到slave库,会给系统造成致命的打击. 解决读写分离的方案很多,常用的有SQL解析.动态设置数据源.SQL解析主要是通过分析sql语句是insert/select/update/delete中的哪一种,从而对