python实现感知器算法详解
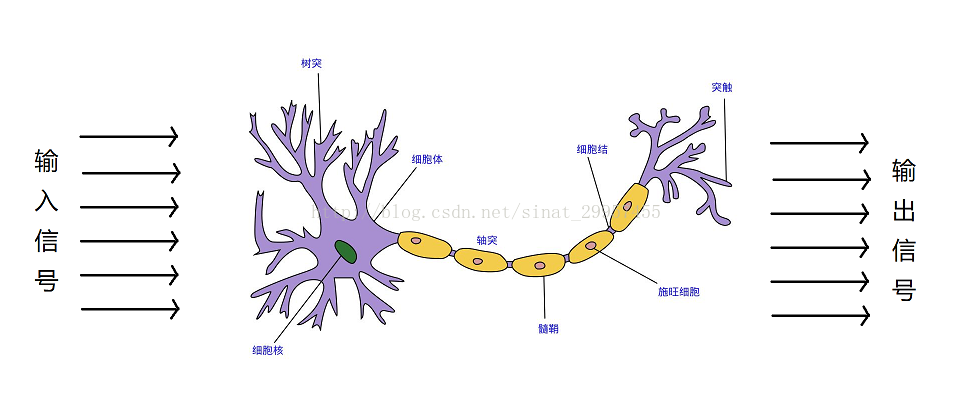
在1943年,沃伦麦卡洛可与沃尔特皮茨提出了第一个脑神经元的抽象模型,简称麦卡洛可-皮茨神经元(McCullock-Pitts neuron)简称MCP,大脑神经元的结构如下图。麦卡洛可和皮茨将神经细胞描述为一个具备二进制输出的逻辑门。树突接收多个输入信号,当输入信号累加超过一定的值(阈值),就会产生一个输出信号。弗兰克罗森布拉特基于MCP神经元提出了第一个感知器学习算法,同时它还提出了一个自学习算法,此算法可以通过对输入信号和输出信号的学习,自动的获取到权重系数,通过输入信号与权重系数的乘积来判断神经元是否被激活(产生输出信号)。
一、感知器算法
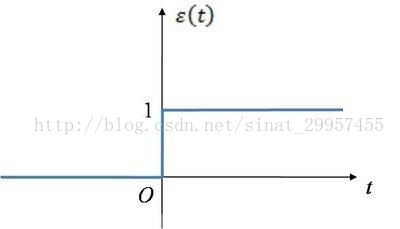
我们将输入信号定义为一个x向量,x=(x1,x2,x3..),将权重定义为ω=(ω1,ω2,ω3...)其中ω0的值为,将z定义为为两个向量之间的乘积,所以输出z=x1*ω1 + x2*ω2+....,然后将z通过激励(激活)函数,作为真正的输出。其中激活函数是一个分段函数,下图是一个阶跃函数,当输入信号大于0的时候输出为1,小于0的时候输出为0,这里的阶跃函数阈值设置为0了。定义激活函数为Φ(z),给激活函数Φ(z)设定一个阈值θ,当激活函数的输出大于阈值θ的时候,将输出划分为正类(1),小于阈值θ的时候将输出划分为负类(-1)。如果,将阈值θ移到等式的左边z=x1*ω1+x2*ω2+....+θ,我们可以将θ看作为θ=x0*ω0,其中输出x0为1,ω0为-θ。将阈值θ移到等式的左边之后,就相当于激活函数的阈值由原来的θ变成了0。
感知器算法的工作过程:
1、将权重ω初始化为零或一个极小的随机数。
2、迭代所有的训练样本(已知输入和输出),执行如下操作:
a、通过权重和已知的输入计算输出
b、通过a中的输出与已知输入的输出来更新权重

权重的更新过程,如上图的公式,其中ω与x都是相对应的(当ω为ω0的时候,x为1),η为学习率介于0到1之间的常数,其中y为输入所对应的输出,后面的y(打不出来)为a中所计算出来的输出。通过迭代对权重的更新,当遇到类标预测错误的情况下,权重的值会趋于正类别和负类别的方向。
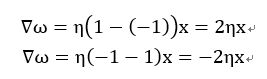
第一个公式表示的是,当真实的输出为1的情况下,而预测值为-1,所以我们就需要增加权重来使得预测值往1靠近。
第二个公式表示的是,当真实的输出为-1的情况下,而预测值为1,所以我们就需要减少权重来使得预测值往-1靠近。
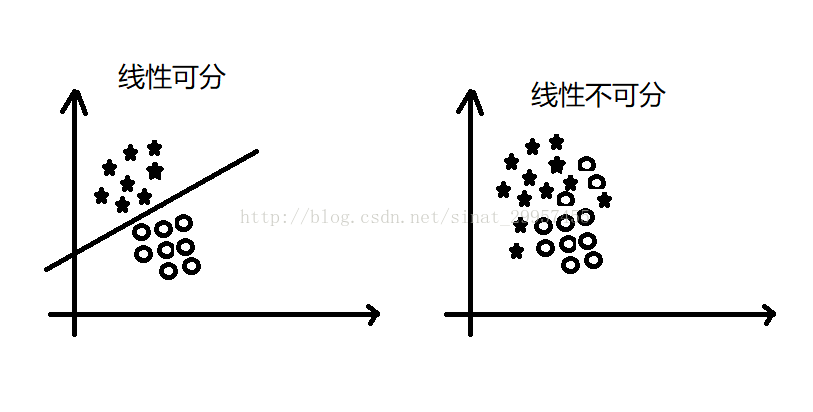
注意:感知器收敛的前提是两个类别必须是线性可分的,且学习率足够小。如果两个类别无法通过一个线性决策边界进行划分,我们可以设置一个迭代次数或者一个判断错误样本的阈值,否则感知器算法会一直运行下去。
最后,用一张图来表示感知器算法的工作过程
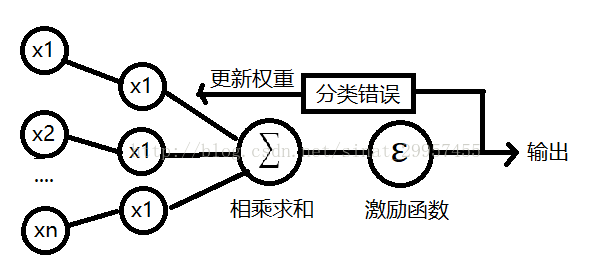
二、python实现感知器算法
import numpy as np
class Perceptron(object):
'''''
输入参数:
eta:学习率,在0~1之间,默认为0.01
n_iter:设置迭代的次数,默认为10
属性:
w_:一维数组,模型的权重
errors_:列表,被错误分类的数据
'''
#初始化对象
def __init__(self,eta=0.01,n_iter=10):
self.eta = eta
self.n_iter = n_iter
#根据输入的x和y训练模型
def fit(self,x,y):
#初始化权重
self.w_ = np.zeros(1 + x.shape[1])
#初始化错误列表
self.errors_=[]
#迭代输入数据,训练模型
for _ in range(self.n_iter):
errors = 0
for xi,target in zip(x,y):
#计算预测与实际值之间的误差在乘以学习率
update = self.eta * (target - self.predict(xi))
#更新权重
self.w_[1:] += update * xi
#更新W0
self.w_[0] += update * 1
#当预测值与实际值之间误差为0的时候,errors=0否则errors=1
errors += int(update != 0)
#将错误数据的下标加入到列表中
self.errors_.append(errors)
return self
#定义感知器的传播过程
def net_input(self,x):
#等价于sum(i*j for i,j in zip(x,self.w_[1:])),这种方式效率要低于下面
return np.dot(x,self.w_[1:]) + self.w_[0]
#定义预测函数
def predict(self,x):
#类似于三元运算符,当self.net_input(x) >= 0.0 成立时返回1,否则返回-1
return np.where(self.net_input(x) >= 0.0 , 1 , -1)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python实现感知器模型、两层神经网络
本文实例为大家分享了Python实现感知器模型.两层神经网络,供大家参考,具体内容如下 python 3.4 因为使用了 numpy 这里我们首先实现一个感知器模型来实现下面的对应关系 [[0,0,1], --- 0 [0,1,1], --- 1 [1,0,1], --- 0 [1,1,1]] --- 1 从上面的数据可以看出:输入是三通道,输出是单通道. 这里的激活函数我们使用 sigmoid 函数 f(x)=1/(1+exp(-x)) 其导数推导如下所示: L0=W*X; z=f(L0);
-
python实现感知器
上篇博客转载了关于感知器的用法,遂这篇做个大概总结,并实现一个简单的感知器,也为了加深自己的理解. 感知器是最简单的神经网络,只有一层.感知器是模拟生物神经元行为的机器.感知器的模型如下: 给定一个n维的输入 ,其中w和b是参数,w为权重,每一个输入对应一个权值,b为偏置项,需要从数据中训练得到. 激活函数 感知器的激活函数可以有很多选择,比如我们可以选择下面这个阶跃函数f来作为激活函数: 输出为: 事实上感知器可以拟合任何线性函数,任何线性分类或线性回归的问题都可以用感知器来解决.但是感知器不
-
JAVA实现感知器算法
简述 随着互联网的高速发展,A(AI)B(BigData)C(Cloud)已经成为当下的核心发展方向,假如三者深度结合的话,AI是其中最核心的部分.所以如果说在未来社会,每个人都必须要学会编程的话,那么对于程序员来说,人工智能则是他们所必须掌握的技术(科技发展真tm快). 这篇文章介绍并用JAVA实现了一种最简单的感知器网络,不纠结于公式的推导,旨在给大家提供一下学习神经网络的思路,对神经网络有一个大概的认识. 感知器网络模型分析 首先看一张图 如果稍微对神经网络感兴趣的一定对这张图不陌生,这张
-
python实现感知器算法详解
在1943年,沃伦麦卡洛可与沃尔特皮茨提出了第一个脑神经元的抽象模型,简称麦卡洛可-皮茨神经元(McCullock-Pitts neuron)简称MCP,大脑神经元的结构如下图.麦卡洛可和皮茨将神经细胞描述为一个具备二进制输出的逻辑门.树突接收多个输入信号,当输入信号累加超过一定的值(阈值),就会产生一个输出信号.弗兰克罗森布拉特基于MCP神经元提出了第一个感知器学习算法,同时它还提出了一个自学习算法,此算法可以通过对输入信号和输出信号的学习,自动的获取到权重系数,通过输入信号与权重系数的乘积来
-
详解如何用Python实现感知器算法
目录 一.题目 二.数学求解过程 三.感知器算法原理及步骤 四.python代码实现及结果 一.题目 二.数学求解过程 该轮迭代分类结果全部正确,判别函数为g(x)=-2x1+1 三.感知器算法原理及步骤 四.python代码实现及结果 (1)由数学求解过程可知: (2)程序运行结果 (3)绘图结果 ''' 20210610 Julyer 感知器 ''' import numpy as np import matplotlib.pyplot as plt def get_zgxl(xn, a):
-
python里反向传播算法详解
反向传播的目的是计算成本函数C对网络中任意w或b的偏导数.一旦我们有了这些偏导数,我们将通过一些常数 α的乘积和该数量相对于成本函数的偏导数来更新网络中的权重和偏差.这是流行的梯度下降算法.而偏导数给出了最大上升的方向.因此,关于反向传播算法,我们继续查看下文. 我们向相反的方向迈出了一小步--最大下降的方向,也就是将我们带到成本函数的局部最小值的方向. 图示演示: 反向传播算法中Sigmoid函数代码演示: # 实现 sigmoid 函数 return 1 / (1 + np.exp(-x))
-
Python实现聚类K-means算法详解
目录 手动实现 sklearn库中的KMeans K-means(K均值)算法是最简单的一种聚类算法,它期望最小化平方误差 注:为避免运行时间过长,通常设置一个最大运行轮数或最小调整幅度阈值,若到达最大轮数或调整幅度小于阈值,则停止运行. 下面我们用python来实现一下K-means算法:我们先尝试手动实现这个算法,再用sklearn库中的KMeans类来实现.数据我们采用<机器学习>的西瓜数据(P202表9.1): # 下面的内容保存在 melons.txt 中 # 第一列为西瓜的密度:第
-
python查找与排序算法详解(示图+代码)
目录 查找 二分查找 线性查找 排序 插入排序 快速排序 选择排序 冒泡排序 归并排序 堆排序 计数排序 希尔排序 拓扑排序 总结 查找 二分查找 二分搜索是一种在有序数组中查找某一特定元素的搜索算法.搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束:如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较.如果在某一步骤数组为空,则代表找不到.这种搜索算法每一次比较都使搜索范围缩小一半. # 返回 x 在 ar
-
python实现感知器算法(批处理)
本文实例为大家分享了Python感知器算法实现的具体代码,供大家参考,具体内容如下 先创建感知器类:用于二分类 # -*- coding: utf-8 -*- import numpy as np class Perceptron(object): """ 感知器:用于二分类 参照改写 https://blog.csdn.net/simple_the_best/article/details/54619495 属性: w0:偏差 w:权向量 learning_rate:学习率
-
python 自定义装饰器实例详解
本文实例讲述了python 自定义装饰器.分享给大家供大家参考,具体如下: 先看一个例子 def deco(func): print("before myfunc() called.") func() print("after myfunc() called.") return func @deco def myfunc(): print("myfunc() called.") # myfunc = deco(myfunc) # 与上面的@dec
-
Python实现的快速排序算法详解
本文实例讲述了Python实现的快速排序算法.分享给大家供大家参考,具体如下: 快速排序基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 如序列[6,8,1,4,3,9],选择6作为基准数.从右向左扫描,寻找比基准数小的数字为3,交换6和3的位置,[3,8,1,4,6,9],接着从左向右扫描,寻找比基准数大的数字为8,交换6和8的位置
-
Python的装饰器使用详解
Python有大量强大又贴心的特性,如果要列个最受欢迎排行榜,那么装饰器绝对会在其中. 初识装饰器,会感觉到优雅且神奇,想亲手实现时却总有距离感,就像深闺的冰美人一般.这往往是因为理解装饰器时把其他的一些概念混杂在一起了.待我抚去层层面纱,你会看到纯粹的装饰器其实蛮简单直率的. 装饰器的原理 在解释器下跑个装饰器的例子,直观地感受一下. # make_bold就是装饰器,实现方式这里略去 >>> @make_bold ... def get_content(): ... return '
-
python列表与列表算法详解
目录 1. 序列类型定义 2. 列表的基础知识 2.1 列表定义 2.2 列表基本操作 总结 1. 序列类型定义 序列是具有先后关系的一组元素 序列是一维元素向量,元素类型可以不同 类似数学运算序列:S0,S1,-,S(n-1) 元素间由序号引导,通过下表访问序列的特定元素 序列是一个基类类型 序列处理函数及方法 序列类型通用函数和方法 2. 列表的基础知识 2.1 列表定义 列表(list):是可变的序列型数据,也是一种可以存储各种数据类型的集合,用中括号([ ])表示列表的开始和结束,列表中