python中Apriori算法实现讲解
本文主要给大家讲解了Apriori算法的基础知识以及Apriori算法python中的实现过程,以下是所有内容:
1. Apriori算法简介
Apriori算法是挖掘布尔关联规则频繁项集的算法。Apriori算法利用频繁项集性质的先验知识,通过逐层搜索的迭代方法,即将K-项集用于探察(k+1)项集,来穷尽数据集中的所有频繁项集。先找到频繁项集1-项集集合L1, 然后用L1找到频繁2-项集集合L2,接着用L2找L3,知道找不到频繁K-项集,找到每个Lk需要一次数据库扫描。注意:频繁项集的所有非空子集也必须是频繁的。Apriori性质通过减少搜索空间,来提高频繁项集逐层产生的效率。Apriori算法由连接和剪枝两个步骤组成。
2. Apriori算法步骤
根据一个实例来解释:下图是一个交易单,I1至I5可看作5种商品。下面通过频繁项集合来找出关联规则。
假设我们的最小支持度阈值为2,即支持度计数小于2的都要删除。

上表第一行(第一项交易)表示:I1和I2和I5一起被购买。

C1至L1的过程: 只需查看支持度是否高于阈值,然后取舍。上图C1中所有阈值都大于2,故L1中都保留。
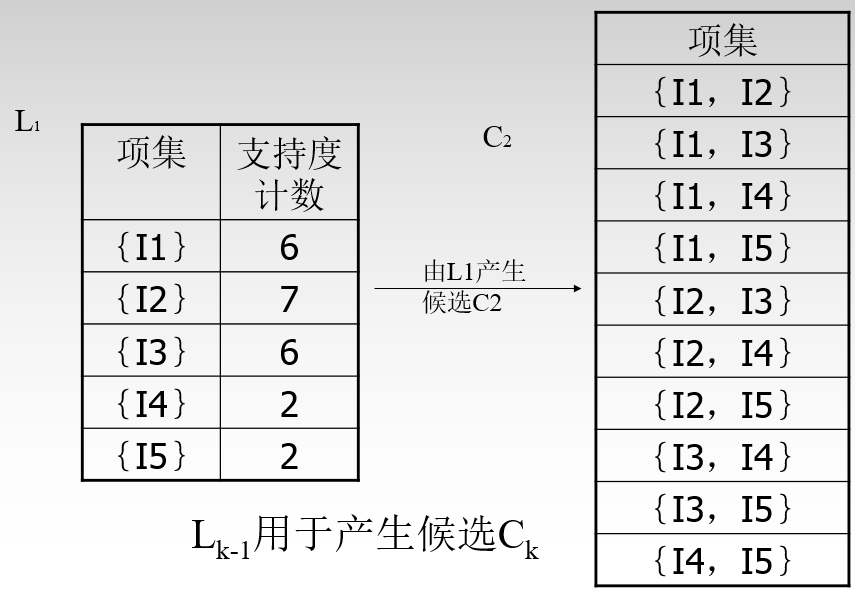
L1至C2的过程分三步:
遍历产生L1中所有可能性组合,即(I1,I2)...(I4,I5 ) 对便利产生的每个组合进行拆分,以保证频繁项集的所有非空子集也必须是频繁的。即对于(I1,I2)来说进行拆分为I1,I2.由于I1和I2在L1中都为频繁项,所以这一组合保留。对于剩下的C2根据原数据集中进行支持度计数

C2至L2的过程: 只需查看支持度是否高于阈值,然后取舍。

L2至C3的过程:
还是上面的步骤。首先生成(1,2,3)、(1,2,4)、(1,2,5)....为什么最后只剩(1,2,3)和(1,2,5)呢?因为剪枝过程:(1,2,4)拆分为(1,2)和(1,4)和(2,4).然而(1,4)在L2中不存在,即非频繁项。所有剪枝删除。然后对C3中剩下的组合进行计数。发现(1,2,3)和(1,2,5)的支持度2。迭代结束。
所以算法过程就是 Ck - Lk - Ck+1 的过程:
3.Apriori算法实现
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 9 15:33:45 2017
@author: LPS
"""
import numpy as np
from itertools import combinations # 迭代工具
data = [[1,2,5], [2,4], [2,3], [1,2,4], [1,3], [2,3], [1,3], [1,2,3,5], [1,2,3]]
minsp = 2
d = []
for i in range(len(data)):
d.extend(data[i])
new_d = list(set(d))
def satisfy(s, s_new, k): # 更新确实存在的L
e =[]
ss_new =[]
for i in range(len(s_new)):
for j in combinations(s_new[i], k): # 迭代产生所有元素可能性组合
e.append(list(j))
if ([l for l in e if l not in s]) ==[] :
ss_new.append(s_new[i])
e = []
return ss_new # 筛选满足条件的结果
def count(s_new): # 返回narray格式的C
num = 0
C = np.copy(s_new)
C = np.column_stack((C, np.zeros(C.shape[0])))
for i in range(len(s_new)):
for j in range(len(data)):
if ([l for l in s_new[i] if l not in data[j]]) ==[] :
num = num+1
C[i,-1] = num
num = 0
return C
def limit(L): # 删掉不满足阈值的C
row = []
for i in range(L.shape[0]):
if L[i,-1] < minsp :
row.append(i)
L = np.delete(L, row, 0)
return L
def generate(L, k): # 实现由L至C的转换
s = []
for i in range(L.shape[0]):
s.append(list(L[i,:-1]))
s_new = []
# L = L.delete(L, -1, 1)
# l = L.shape[1]
for i in range(L.shape[0]-1):
for j in range(i+1, L.shape[0]):
if (L[j,-2]>L[i,-2]):
t = list(np.copy(s[i]))
t.append(L[j,-2])
s_new.append(t) # s_new为列表
s_new = satisfy(s, s_new, k)
C = count(s_new)
return C
# 初始的C与L
C = np.zeros([len(new_d), 2])
for i in range(len(new_d)):
C[i:] = np.array([new_d[i], d.count(new_d[i])])
L = np.copy(C)
L = limit(L)
# 开始迭代
k = 1
while (np.max(L[:,-1]) > minsp):
C = generate(L, k) # 由L产生C
L = limit(C) # 由C产生L
k = k+1
# 对最终结果去重复
print((list(set([tuple(t) for t in L])))
# 结果为 [(1.0, 2.0, 3.0, 2.0), (1.0, 2.0, 5.0, 2.0)]
相关推荐
-

Python排序搜索基本算法之插入排序实例分析
本文实例讲述了Python排序搜索基本算法之插入排序.分享给大家供大家参考,具体如下: 插入排序生活中非常常见,打扑克的时候人的本能就在用插入排序:把抽到的一张插入到手上牌的正确位置上.有两种插入排序方法,一种基于比较,另一种基于交换.代码如下: 1.基于比较的插入排序: # coding:utf-8 def insertionSort(seq): length=len(seq) for i in range(1,length): tmp=seq[i] for j in range(i,0,-1
-
K-近邻算法的python实现代码分享
k-近邻算法概述: 所谓k-近邻算法KNN就是K-Nearest neighbors Algorithms的简称,它采用测量不同特征值之间的距离方法进行分类 用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中. k-近邻算法分析 优点:精度高.对异常值不敏感.无数据输入假定. 缺点:计算复杂度高.空间复杂度高. 适用数据范围:数值型和标称型 k-
-
Python数据结构与算法之图的基本实现及迭代器实例详解
本文实例讲述了Python数据结构与算法之图的基本实现及迭代器.分享给大家供大家参考,具体如下: 这篇文章参考自<复杂性思考>一书的第二章,并给出这一章节里我的习题解答. (这书不到120页纸,要卖50块!!,一开始以为很厚的样子,拿回来一看,尼玛.....代码很少,给点提示,然后让读者自己思考怎么实现) 先定义顶点和边 class Vertex(object): def __init__(self, label=''): self.label = label def __repr__(sel
-
Python数据结构与算法之二叉树结构定义与遍历方法详解
本文实例讲述了Python数据结构与算法之二叉树结构定义与遍历方法.分享给大家供大家参考,具体如下: 先序遍历,中序遍历,后序遍历 ,区别在于三条核心语句的位置 层序遍历 采用队列的遍历操作第一次访问根,在访问根的左孩子,接着访问根的有孩子,然后下一层 自左向右一一访问同层的结点 # 先序遍历 # 访问结点,遍历左子树,如果左子树为空,则遍历右子树, # 如果右子树为空,则向上走到一个可以向右走的结点,继续该过程 preorder(t): if t: print t.value preorde
-
Python语言描述KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知样本的类别,以全部训练样本作为代表点,计算未知样本与所有训练样本的距离,并以最近邻者的类别作为决策未知样本类别的唯一依据.但是,最近邻算法明显是存在缺陷的,比如下面的例子:有一个未知形状(图中绿色的圆点),如何判断它是什么形状? 显然,最近邻算法的缺陷--对噪声数据过于敏感,为了解决这个问题,我们可
-
Python使用三种方法实现PCA算法
主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域.它的主要作用是对高维数据进行降维.PCA把原先的n个特征用数目更少的k个特征取代,新特征是旧特征的线性组合,这些线性组合最大化样本方差,尽量使新的k个特征互不相关.关于PCA的更多介绍,请参考:https://en.wikipedia.org/wiki/Principal_component_analysis. 主成分分析(PCA) vs 多元判别式分析(MD
-
Python排序搜索基本算法之选择排序实例分析
本文实例讲述了Python排序搜索基本算法之选择排序.分享给大家供大家参考,具体如下: 选择排序就是第n次把序列中最小的元素排在第n的位置上,一旦排好就是该元素的绝对位置.代码如下: # coding:utf-8 def selectionSort(seq): length=len(seq) for i in range(length): mini=min(seq[i:]) if seq[i]>mini: j=seq.index(mini,i) seq[i],seq[j]=seq[j],seq[
-
Python数据结构与算法之图的最短路径(Dijkstra算法)完整实例
本文实例讲述了Python数据结构与算法之图的最短路径(Dijkstra算法).分享给大家供大家参考,具体如下: # coding:utf-8 # Dijkstra算法--通过边实现松弛 # 指定一个点到其他各顶点的路径--单源最短路径 # 初始化图参数 G = {1:{1:0, 2:1, 3:12}, 2:{2:0, 3:9, 4:3}, 3:{3:0, 5:5}, 4:{3:4, 4:0, 5:13, 6:15}, 5:{5:0, 6:4}, 6:{6:0}} # 每次找到离源点最近的一个顶
-
python中Apriori算法实现讲解
本文主要给大家讲解了Apriori算法的基础知识以及Apriori算法python中的实现过程,以下是所有内容: 1. Apriori算法简介 Apriori算法是挖掘布尔关联规则频繁项集的算法.Apriori算法利用频繁项集性质的先验知识,通过逐层搜索的迭代方法,即将K-项集用于探察(k+1)项集,来穷尽数据集中的所有频繁项集.先找到频繁项集1-项集集合L1, 然后用L1找到频繁2-项集集合L2,接着用L2找L3,知道找不到频繁K-项集,找到每个Lk需要一次数据库扫描.注意:频繁项集的所有非空
-
python数据挖掘Apriori算法实现关联分析
目录 摘要: 关联分析 Apriori原理 算法实现 挖掘关联规则 利用Apriori算法解决实际问题 发现毒蘑菇的相似特征 总结: 摘要: 主要是讲解一些数据挖掘中频繁模式挖掘的Apriori算法原理应用实践 当我们买东西的时候,我们会发现物品展示方式是不同,购物以后优惠券以及用户忠诚度也是不同的,但是这些来源都是大量数据的分析,为了从顾客身上获得尽可能多的利润,所以需要用各种技术来达到目的. 通过查看哪些商品一起购物可以帮助商店了解客户的购买行为.这种从大规模数据集中寻找物品间的隐含关系被称
-
python中append函数用法讲解
如果在做一个地区的统计工作,可以使用列表来帮助我们.输入汉字或者其他字符,比如"01代表汉族",那么在写民族的时候有下拉列表,就可以打01,就会自动识别为汉族.列表是用来大规模数据填报的时候使用,在python中,也有很多使用到列表的时候,那你知道如何在列表的末尾添加新的对象?今天,我们就来认识一下python中可以在列表末尾添加元素的append函数. 1.append()函数 用于在列表末尾添加新的对象. 2. 语法 list.append(obj) 3.参数 list:列表对象:
-
python中K-means算法基础知识点
能够学习和掌握编程,最好的学习方式,就是去掌握基本的使用技巧,再多的概念意义,总归都是为了使用服务的,K-means算法又叫K-均值算法,是非监督学习中的聚类算法.主要有三个元素,其中N是元素个数,x表示元素,c(j)表示第j簇的质心,下面就使用方式给大家简单介绍实例使用. K-Means算法进行聚类分析 km = KMeans(n_clusters = 3) km.fit(X) centers = km.cluster_centers_ print(centers) 三个簇的中心点坐标为: [
-
Python中生成ndarray实例讲解
生成ndarray最简单的方法就是array函数,array函数接受任意的序列型对象,生成一个新的包含传递数据的NumPy数组.例子如下: import numpy as np data1 = [1, 2, 3, 4] data2 = [[1, 2, 3, 4], [5, 6, 7, 8]] arr1 = np.array(data1) arr2 = np.array(data2) arr1 = arr1 * 10 arr2 = arr2 + arr1 print(arr1) print(arr
-
python中waitKey实例用法讲解
1.说明 用于等待按钮.当用户按下按钮时,句子将被执行并获得返回值. 2.语法 retval=cv2.waitKey([delay]) Retval:表示返回值: Delay:键触发的时间,单位为ms. 3.实例 import cv2 lena=cv2.imread("D:\pmjcv\lena.bmp") cv2.namedWindow("lesson") cv2.imshow("lesson",lena) key=cv2.waitKey()
-
通过Python中的CGI接口讲解什么是WSGI
目录 前言 为什么是 WSGI? WSGI 实施概略 1)Application 端 2)Server 端 3) 作为 middleware 其他资源: 前言 今天在 git.oschina 的首页上看到他们推出演示平台,其中,Python 的演示平台支持 WSGI 接口的应用.虽然,这个演示平台连它自己提供的示例都跑不起来,但是,它还是成功的勾起了我对 WSGI 的好奇心.一番了解,对该机制的认识,总结如下.如有不妥,还望斧正. 为什么是 WSGI? 写过网页应用的各位亲,应该对 CGI 有了
-
Python中选择结构实例讲解
1.选择结构通过判断条件是否成立来决定分支的执行. 2.选择结构形式:单分支.双分支.多分支. 3.多分支结构,几个分支之间有逻辑关系,不能随意颠倒顺序. 实例 ''' 单分支选择结构 if 条件表达式: 语句/语句块 ''' if 3+2==5: print("单分支选择结构") #true ''' 双分支选择结构 if 条件表达式: 语句/语句块 else 语句/语句块 ''' a = 3 if a<2: print('t'+str(a)) #true else: print
-
浅谈Python实现Apriori算法介绍
导读: 随着大数据概念的火热,啤酒与尿布的故事广为人知.我们如何发现买啤酒的人往往也会买尿布这一规律?数据挖掘中的用于挖掘频繁项集和关联规则的Apriori算法可以告诉我们.本文首先对Apriori算法进行简介,而后进一步介绍相关的基本概念,之后详细的介绍Apriori算法的具体策略和步骤,最后给出Python实现代码. 1.Apriori算法简介 Apriori算法是经典的挖掘频繁项集和关联规则的数据挖掘算法.A priori在拉丁语中指"来自以前".当定义问题时,通常会使用先验知识
-
python使用Apriori算法进行关联性解析
从大规模数据集中寻找物品间的隐含关系被称作关联分析或关联规则学习.过程分为两步:1.提取频繁项集.2.从频繁项集中抽取出关联规则. 频繁项集是指经常出现在一块的物品的集合. 关联规则是暗示两种物品之间可能存在很强的关系. 一个项集的支持度被定义为数据集中包含该项集的记录所占的比例,用来表示项集的频繁程度.支持度定义在项集上. 可信度或置信度是针对一条诸如{尿布}->{葡萄酒}的关联规则来定义的.这条规则的可信度被定义为"支持度({尿布,葡萄酒})/支持度({尿布})". 寻找频繁