javascript正则表达式学习之位置匹配
一、前言
正则表达式是匹配模式,要么是匹配字符,要么匹配位置。
其实在开发中很少用到匹配位置,本篇文章主要包含:
二、什么是位置
位置:相邻字符之间的位置。
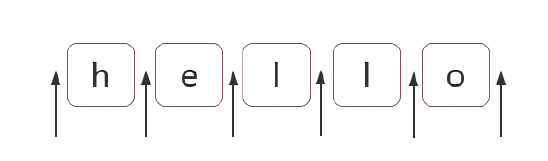
三、如何匹配位置
在ES5中,共有6个锚:^, $, \b, \B, (?=p), (?!p)
可视化形式:
RegExp:/^$\b\B(?=a)(?!b)/g

3.1 ^和$
^(脱字符)匹配开头,在多行匹配中匹配行开头。
$(美元符)匹配结尾,在多行匹配中匹配行结尾。
比如:我们把字符串的开头和结尾用#替换(位置可以替换成字符的):
var result = "hello".replace(/^|$/g, '#'); console.log(result); // "#hello#"
多行匹配模式(有修饰符m)时,二者是行的概念,我们需要注意:
var result = "I\nlove\njavascript".replace(/^|$/gm, '#'); console.log(result); // #I#// #love#// #javascript#
3.2 \b和\B
\b是单词边界,具体就是\w和\W之间的位置,也包括\w与^之间的位置,和\w和$之间的位置。
比如考察文件名"[JS] Lesson_01.mp4"中的\b,如下:
var result = "[JS] Lesson_01.mp4".replace(/\b/g, '#'); console.log(result); // "[#JS#] #Lesson_01#.#mp4#"
首先,我们知道\w是字符组[0-9a-zA-Z]的简写,即使字母数字或者下划线中任何一个字符。而\W是字符组[^0-9a-zA-Z]的简写,即\W是\w以外的任何一个字符。
我们再来看#是怎么来的:
第 1 个,两边字符是 "[" 与 "J",是 \W 与 \w 之间的位置。
第 2 个,两边字符是 "S" 与 "]",也就是 \w 与 \W 之间的位置。
第 3 个,两边字符是空格与 "L",也就是 \W 与 \w 之间的位置。
第 4 个,两边字符是 "1" 与 ".",也就是 \w 与 \W 之间的位置。
第 5 个,两边字符是 "." 与 "m",也就是 \W 与 \w之间的位置。
第 6 个,位于结尾,前面的字符 "4" 是 \w,即 \w 与 $ 之间的位置。
知道了\b概念后,那\B就好理解了,\b是单词边界,\B是非单词边界
var result = "[JS] Lesson_01.mp4".replace(/\B/g, '#'); console.log(result); // "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4"
3.3 (?=p) 和 (?!p)
(?=p)其中p是一个子模式,即 p前面的位置 (该位置后面的字符要匹配p)
比如:(?=e),表示的是e字符前面的位置;
var result = "hello".replace(/(?=l)/g, '#'); console.log(result); // "he#l#lo"
而(?!p)就是(?=p)的反面意思
var result = "hello".replace(/(?!l)/g, '#'); console.log(result); // "#h#ell#o#"
二者的学名分别是 positive lookahead 和 negative lookahead。
中文翻译分别是 正向先行断言 和 负向先行断言 。
ES5 之后的版本,会支持 positive lookbehind 和 negative lookbehind。
具体是 (?<=p) 和 (?<!p)。
四、位置特性
对于位置的理解,我们可以累计额成空字符""。
比如"hello"字符串等价于如下形式:
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "" + "o" + "";
也等价于
"hello" == "" + "" + "hello"
因此,把 /^hello$/ 写成 /^^hello$$$/,是没有任何问题的:
var result = /^^hello$$$/.test("hello");
console.log(result);
// true
也就是说,字符之间的位置,可以写成多个。
注:把 位置 理解 空字符 ,是对位置非常有效的理解方式
五、相关案例
5.1不匹配任何东西的正则
/.^/
正则要求 只有一个字符,但是该字符后面是开头 ,而这样的字符串是不存在的。
5.2数字的千分位分隔符表示法
比如吧12345678,变成12,345,678。
分析:那就是需要把相应的位置替换成","
5.2.1弄出来最后一个逗号
正则:/(?=\d{3}$)/
var result = "12345678".replace(/(?=\d{3}$)/g, ',')console.log(result);
// 12345,678
其中(?=\d{3}$)匹配\d{3}$前面的位置。而\d{3}$匹配的是目标字符串最后那3为数字。
5.2.2弄出来多有逗号
因为逗号的出现的位置,要求后边3个数字一组,也就是\d{3}至少出现1次。
可以使用量词 + :
var result = "12345678".replace(/(?=(\d{3})+$)/g, ',')console.log(result);
// 12,345,678
5.2.3匹配其余案例
写完正则后,是需要举个别案例来验证的,就会发现问题:
var result = "123456789".replace(/(?=(\d{3})+$)/g, ',')console.log(result);
// ,123,456,789
上面的正则,仅仅是表示把从结尾向前数,一旦是3的倍数买酒吧前面的位置替换为逗号。
还需要要求:匹配的这个位置不能是开头。
我们知道开头的匹配是使用^,但是不是开头怎么整?
使用(?!^)
var regex = /(?!^)(?=(\d{3})+$)/g;var result = "12345678".replace(regex, ',')console.log(result);
// "12,345,678"result = "123456789".replace(regex, ',');
console.log(result);// "123,456,789"
5.2.4支持其他形式
如果要把 "12345678 123456789" 替换成 "12,345,678 123,456,789"。
此时我们需要修改正则,把里面的开头 ^ 和结尾 $,修改成 \b:
var string = "12345678 123456789",regex = /(?!\b)(?=(\d{3})+\b)/g;
var result = string.replace(regex, ',')console.log(result);
// "12,345,678 123,456,789"
其中(?!\b)怎么理解?
要求是当前的一个位置,但不是\b前面的位置,其实(?!\b)说的是\B。
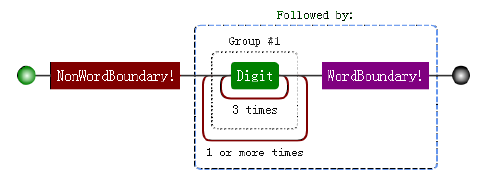
因此最终正则变成了:/\B(?=(\d{3})+\b)/g。
可视化形式:
RegExp:/\B(?=(\d{3})+\b)/g
5.2.5货币格式化
千分符表示法一个常见的应用就是货币格式化。
把这个字符串:
格式化:
$ 1888.00
实现:
function format (num) {return num.toFixed(2).replace(/\B(?=(\d{3})+\b)/g, ",").replace(/^/, "$ ");
};
console.log( format(1888) );
// "$ 1,888.00"
5.3验证密码的问题
密码长度6-12,由数字,小写字母,大写字母组成,但必须至少包括2种字符。
写成多个正则来判断,比较容易,但是要写成一个正则就比较困难。
来看看我们对于位置的理解是否深刻。
5.3.1简化
暂时不考虑"必须至少包含2种字符"这个条件,可以容易写出:
var regex = /^[0-9A-Za-z]{6,12}$/;
5.3.2判断是否包含有某一种字符
假设,要求我们必须包含数字,怎么整?此时我们可以使用(?=.*[0-9])来实现。
正则变成:
var regex = /(?=.*[0-9])^[0-9A-Za-z]{6,12}$/;
5.3.3同时包含具体两种字符
比如同时包含数字和小写字母,可以使用(?=.*[0-9])(?=.*[a-z])来实现。
正则变成:
var regex = /(?=.*[0-9])(?=.*[a-z])^[0-9A-Za-z]{6,12}$/;
5.3.3具体实现
把原题变成下列几种情况:
1、同时包含数字和小写字母;
2、同时包含数字和大写字母;
3、同时包含小写字母和大写字母;
4、同时包含数字,小写字母和大写字母。
以上的4中情况是 或 的关系(实际上,第四条可以不用)。
最终答案:
var regex = /((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[AZ]))^[0-9A-Za-z]{6,12}$/;console.log( regex.test("1234567") );
// false 全是数字console.log( regex.test("abcdef") );
// false 全是小写字母console.log( regex.test("ABCDEFGH") );
// false 全是大写字母console.log( regex.test("ab23C") );
// false 不足6位console.log( regex.test("ABCDEF234") );
// true 大写字母和数字console.log( regex.test("abcdEF234") );
// true 三者都有
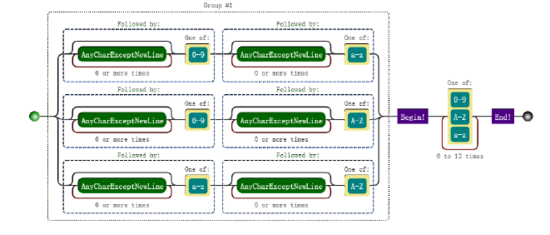
可视化形式:
RegExp:/((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[AZ]))^[ 0-9A-Za-z]{6,12}$/
分析:
上面正则看起来好复杂,只需要理解第二步,/(?=.*[0-9])^[0-9A-Za-z]{6,12}$/;
对于这个正则,我们需要明白(?=.*[0-9])^这个;
分开来看就是(?=.*[0-9]) 和 ^。
表示开头前面还有个位置(当然也是开头,即同一个位置,想想之前的空字符类比)。
(?=.*[0-9]) 表示该位置后面的字符匹配。
.*[0-9],即,有任何多个任意字符,后面再跟个数字。
翻译成大白话,就是接下来的字符,必须包含个数字。
5.3.4另外一种解法
“至少包含两种字符”的意思就是说,不能全部都是数字,也不能全部都是小写字母,也不能全部都是大写字母。
那么要求“不能全部都是数字”,怎么做呢? (?!p) 出马!
对应的正则:
var regex = /(?!^[0-9]{6,12}$)^[0-9A-Za-z]{6,12}$/;
三种“都不能”呢?
最终答案是:
var regex = /(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/;
console.log( regex.test("1234567") );
// false 全是数字console.log( regex.test("abcdef") );
// false 全是小写字母console.log( regex.test("ABCDEFGH") );
// false 全是大写字母console.log( regex.test("ab23C") );
// false 不足6位console.log( regex.test("ABCDEF234") );
// true 大写字母和数字console.log( regex.test("abcdEF234") );
// true 三者都有
可视化形式:
RegExp:/(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/;

总结
以上所述是小编给大家介绍的javascript正则表达式学习之位置匹配,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

js匹配网址url的正则表达式集合
DNS规定,域名中的标号都由英文字母和数字组成,每一个标号不超过63个字符,也不区分大小写字母.标号中除连字符(-)外不能使用其他的标点符号.级别最低的域名写在最左边,而级别最高的域名写在最右边.由多个标号组成的完整域名总共不超过255个字符.所以验证则网址url的正则可以如下几种 方法一: function checkUrl(urlString){ if(urlString!=""){ var reg=/(http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+
-
JS正则表达式匹配检测各种数值类型(数字验证)
验证数字的正则表达式集 验证数字:^[0-9]*$ 验证n位的数字:^\d{n}$ 验证至少n位数字:^\d{n,}$ 验证m-n位的数字:^\d{m,n}$ 验证零和非零开头的数字:^(0|[1-9][0-9]*)$ 验证有两位小数的正实数:^[0-9]+(.[0-9]{2})?$ 验证有1-3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$ 验证非零的正整数:^\+?[1-9][0-9]*$ 验证非零的负整数:^\-[1-9][0-9]*$ 验证非负整数(正整数 + 0) ^\d
-
js正则表达式惰性匹配和贪婪匹配用法分析
本文实例讲述了js正则表达式惰性匹配和贪婪匹配用法.分享给大家供大家参考,具体如下: 在讲贪婪模式和惰性模式之前,先回顾一下JS正则基础: 写法基础: ①不需要双引号,直接用//包含 => /wehfwue123123/.test(); ②反斜杠\表示转义 =>/\.jpg$/ ③用法基础:.test(str); 语法: ①锚点类 /^a/=>以"a"开头 /\.jpg$/=>以".jpg"结尾 ②字符类 [abc]:a或b或c [0-9]:
-
JS 正则表达式的位置匹配
http://regexpal.com/ 上面这个网站可以用于在线检测JS的正则表达式语法 除了熟知的几个固定字符表示位置: ^ : Match the beginning of the string and, in multiline searches, the beginning of a line. $ : Match the end of the string and, in multiline searches, the end of a line. \b: Match a word
-
js正则表达式最长匹配(贪婪匹配)和最短匹配(懒惰匹配)用法分析
本文实例分析了js正则表达式最长匹配(贪婪匹配)和最短匹配(懒惰匹配)用法.分享给大家供大家参考,具体如下: 最近在阅读RequireJS 2.1.15源码,源码开始处定义了一系列的变量,有4个正则表达式: var commentRegExp = /(\/\*([\s\S]*?)\*\/|([^:]|^)\/\/(.*)$)/mg, cjsRequireRegExp = /[^.]\s*require\s*\(\s*["']([^'"\s]+)["']\s*\)/g, jsS
-
详解JavaScript正则表达式之分组匹配及反向引用
语法 元字符:(pattern) 作用:用于反复匹配的分组 属性$1~$9 如果它(们)存在,用于得到对应分组中匹配到的子串 \1或$1 用于匹配第一个分组中的内容 \2或$2 用于匹配第一个分组中的内容 ... \9或$9 用于匹配第一个分组中的内容 用法示例 var reg = /(A+)((B|C|D)+)(E+)/gi;//该正则表达式有4个分组 //对应关系 //RegExp.$1 <-> (A+) //RegExp.$2 <-> ((B|C|D)+) //RegExp.
-
JavaScript正则表达式匹配 div style标签
测试字符串: <style>v\:* { BEHAVIOR: url(#default#VML) } o\:* { BEHAVIOR: url(#default#VML) } w\:* { BEHAVIOR: url(#default#VML) } .shape { BEHAVIOR: url(#default#VML) } </style> abcdefg <style> @font-face { font-family: Wingdings; } @font-fac
-
String字符串匹配javascript 正则表达式
在JavaScript代码中使用正则表达式进行模式匹配经常会用到String对象和RegExp对象的一些方法,例如replace.match.search等方法,下面所述是对相关方法使用的总结,需要的朋友参考下. String对象中支持正则表达式有4种方法,分别是:search.replace.match.split str.search(regexp) 定义:search()方法将在字符串str中检索与表达式regexp相匹配的字串,并且返回第一个匹配字串的第一个字符的位置.如果没有找到任何匹
-
javascript正则表达式学习之位置匹配
一.前言 正则表达式是匹配模式,要么是匹配字符,要么匹配位置. 其实在开发中很少用到匹配位置,本篇文章主要包含: 二.什么是位置 位置:相邻字符之间的位置. 三.如何匹配位置 在ES5中,共有6个锚:^, $, \b, \B, (?=p), (?!p) 可视化形式: RegExp:/^$\b\B(?=a)(?!b)/g 3.1 ^和$ ^(脱字符)匹配开头,在多行匹配中匹配行开头. $(美元符)匹配结尾,在多行匹配中匹配行结尾. 比如:我们把字符串的开头和结尾用#替换(位置可以替换成字符的):
-
正则表达式教程之位置匹配详解
本文实例讲述了正则表达式教程之位置匹配.分享给大家供大家参考,具体如下: 注:在所有例子中正则表达式匹配结果包含在源文本中的[和]之间,有的例子会使用Java来实现,如果是java本身正则表达式的用法,会在相应的地方说明.所有java例子都在JDK1.6.0_13下测试通过. 一.问题引入 如果想匹配一段文本中的某个单词(暂不考虑多行模式,将在后面介绍),我们可能会像下面这样: 文本:Yesterday is history, tomorrow is a mystery, but today i
-
js 正则表达式学习笔记之匹配字符串
今天看了第5章几个例子,有点收获,记录下来当作回顾也当作分享. 关于匹配字符串问题,有很多种类型,今天讨论 js 代码里的字符串匹配.(因为我想学完之后写个语法高亮练手,所以用js代码当作例子) 复制代码 代码如下: var str1 = "我是字符串1哦,快把我取走", str2 = "我是字符串2哦,快把我取走"; 比如这样一个字符串,匹配起来很简单 /"[^"]*"/g 即可. PS: 白色截图是 chrome 34 控制台中
-
学习JavaScript正则表达式
JavaScript正则表达式学习: 有个在线调试正则的工具.下面的所有示例代码,都可以在codepen上查看到. 1.创建正则表达式 var re = /ab+c/; //方式一 正则表达式字面量 var re = new RegExp("ab+c"); //方式二 RegExp对象的构造函 1)正则表达式字面量在脚本加载后编译.若你的正则表达式是常量,使用这种方式可以获得更好的性能. 2)使用构造函数,提供了对正则表达式运行时的编译.当你知道正则表达式的模式会发生改变, 或者你事先
-
JavaScript正则表达式的贪婪匹配和非贪婪匹配
所谓贪婪匹配就是匹配重复字符是尽可能多的匹配,比如: "aaaaa".match(/a+/); //["aaaaa", index: 0, input: "aaaaa"] 非贪婪匹配就是尽可能少的匹配,用法就是在量词后面加上一个"?",比如: "aaaaa".match(/a+?/); //["a", index: 0, input: "aaaaa"] 但是非贪婪匹配
-
JavaScript正则表达式迷你书之贪婪模式-学习笔记
贪婪模式: 在使用修饰匹配次数的特殊符号时,有几种表示方法可以使同一个表达式能够匹配不同的次数,比如:"{m,n}", "{m,}", "?", "*", "+",具体匹配的次数随被匹配的字符串而定.这种重复匹配不定次数的表达式在匹配过程中,总是尽可能多的匹配 非贪婪模式: 在修饰匹配次数的特殊符号后再加上一个 "?" 号,则可以使匹配次数不定的表达式尽可能少的匹配,使可匹配可不匹配的表
-
javascript的正则表达式学习资料复习
关于反向引用 复制代码 代码如下: // 测试函数 function matchReg(reg, str) { var result = str.match(reg); if(result) { console.dir(result); } else { console.log('match failed'); } } var reg = /([A-Za-z]{0,6})\1/; var str = 'AndrewAndrew'; // 测试通过 matchReg(reg, str); //通过
-
javascript正则表达式模糊匹配IP地址功能示例
本文实例讲述了javascript正则表达式模糊匹配IP地址功能.分享给大家供大家参考,具体如下: function checkip() { var strIP = document.getElementById("accessip").value; var re = /^(\d{1,3}|\*)\.(\d{1,3}|\*)\.(\d{1,3}|\*)\.(\d{1,3}|\*)$/g //模糊匹配IP地址的正则表达式 if(re.test(strIP)){ if(RegExp.$1