Python中elasticsearch插入和更新数据的实现方法
首先,我的索引结构是酱紫的。
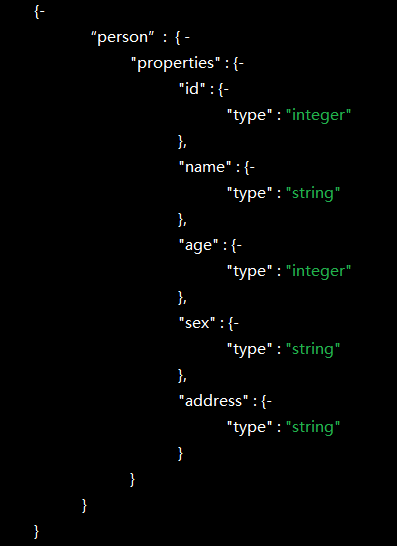
存储以name_id为主键的索引,待插入或更新数据为:
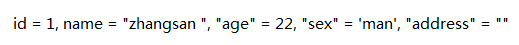
一般会有有两种操作:
以下图片为个人见解,我没试过能不能直接运行,但形式上没错。
数据不存在,我需要插入地址为空字符串。
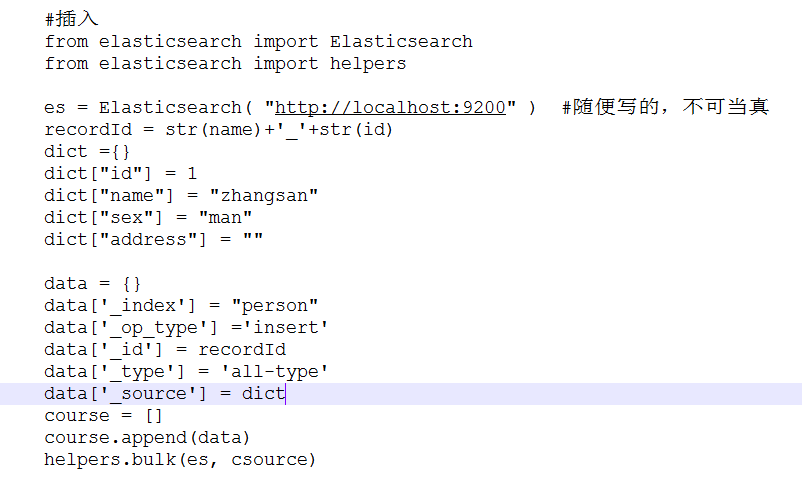
单条插入:

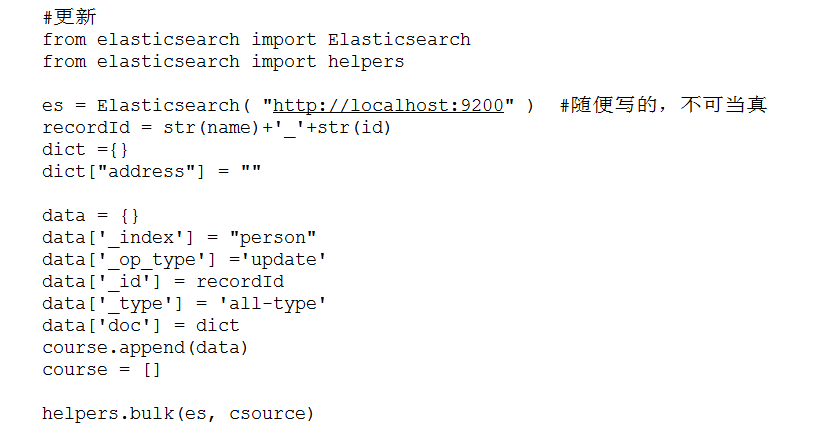
批量插入:
该数据存在,我需要更新地址字段为空字符串。
单条更新:
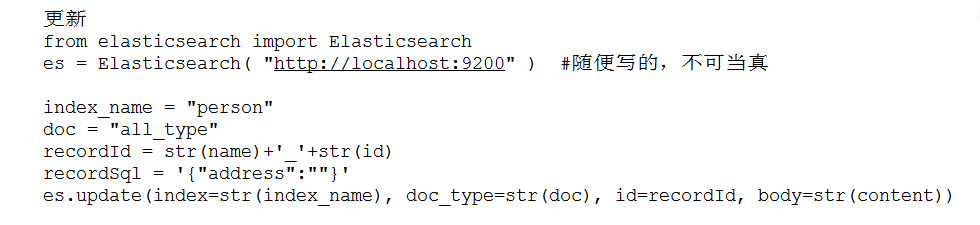
批量更新:
总结
以上所述是小编给大家介绍的Python中elasticsearch插入和更新数据的实现方法,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
您可能感兴趣的文章:
- 使用Python操作Elasticsearch数据索引的教程
- 安装ElasticSearch搜索工具并配置Python驱动的方法
相关推荐
-

使用Python操作Elasticsearch数据索引的教程
Elasticsearch是一个分布式.Restful的搜索及分析服务器,Apache Solr一样,它也是基于Lucence的索引服务器,但我认为Elasticsearch对比Solr的优点在于: 轻量级:安装启动方便,下载文件之后一条命令就可以启动: Schema free:可以向服务器提交任意结构的JSON对象,Solr中使用schema.xml指定了索引结构: 多索引文件支持:使用不同的index参数就能创建另一个索引文件,Solr中需要另行配置: 分布式:Solr Cloud的配置比较
-
安装ElasticSearch搜索工具并配置Python驱动的方法
ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便. 我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的.我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单
-
Python中elasticsearch插入和更新数据的实现方法
首先,我的索引结构是酱紫的. 存储以name_id为主键的索引,待插入或更新数据为: 一般会有有两种操作: 以下图片为个人见解,我没试过能不能直接运行,但形式上没错. 数据不存在,我需要插入地址为空字符串. 单条插入: 批量插入: 该数据存在,我需要更新地址字段为空字符串. 单条更新: 批量更新: 总结 以上所述是小编给大家介绍的Python中elasticsearch插入和更新数据的实现方法,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的! 您可能感兴趣的文章: 使用
-
Python中list循环遍历删除数据的正确方法
前言 初学Python,遇到过这样的问题,在遍历list的时候,删除符合条件的数据,可是总是报异常,代码如下: num_list = [1, 2, 3, 4, 5] print(num_list) for i in range(len(num_list)): if num_list[i] == 2: num_list.pop(i) else: print(num_list[i]) print(num_list) 会报异常:IndexError: list index out of range 原
-
python中sqllite插入numpy数组到数据库的实现方法
sqllite里面并没有与numpy的array类型对应的数据类型,通常我们都需要将数组转换为text之后再插入到数据库中,或者以blob类型来存储数组数据,除此之外我们还有另一种方法,能够让我们直接以array来插入和查询数据,实现代码如下 import sqlite3 import numpy as np import io def adapt_array(arr): out = io.BytesIO() np.save(out, arr) out.seek(0) return sqlite
-
Python中使用matplotlib绘制mqtt数据实时图像功能
目录 效果图 mqtt发布 mqtt订阅 matplotlib绘制动态图 matplotlib绘制mqtt数据实时图像 效果图 mqtt发布 本代码中publish是一个死循环,数据一直往外发送. import random import time from paho.mqtt import client as mqtt_client import json from datetime import datetime broker = 'broker.emqx.io' port = 1883 t
-
MybatisPlus 插入或更新数据时自动填充更新数据解决方案
目录 解决方案 1. 实体类 2.拦截器MetaObjectHandler 3.测试 参考文章 Maven <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.2.6.RELEASE</version> <relativePath/>
-
MySQL中实现插入或更新操作(类似Oracle的merge语句)
如果需要在MySQL中实现记录不存在则insert,不存在则update操作.可以使用以下语句: 更新一个字段: INSERT INTO tbl (columnA,columnB,columnC) VALUES (1,2,3) ON DUPLICATE KEY UPDATE columnA=IF(columnB>0,1,columnA) 更新多个字段: INSERT INTO tbl (columnA,columnB,columnC) VALUES (1,2,3) ON DUPLICATE KE
-
python中for语句简单遍历数据的方法
本文实例讲述了python中for语句简单遍历数据的方法.分享给大家供大家参考.具体如下: 复制代码 代码如下: for name in ["kak", "John", "Mani", "Matt"]: print(name) 运行结果如下: 复制代码 代码如下: kak John Mani Matt 希望本文所述对大家的Python程序设计有所帮助.
-
Python中的正则表达式与JSON数据交换格式
一.初识正则表达式 正则表达式 是一个特殊的字符序列,一个字符串是否与我们所设定的这样的字符序列,相匹配快速检索文本.实现替换文本的操作 json(xml) 轻量级 web 数据交换格式 import re a='C|C++|Java|C#||Python|Javascript' r= re.findall('Python',a) print(r) if len(r) > 0: print('字符串中包含Python') else: print('No') ['Python'] 字符串中包含Py
-
Python 中pandas索引切片读取数据缺失数据处理问题
引入 numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢? numpy能够帮我们处理处理数值型数据,但是这还不够 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等 比如:我们通过爬虫获取到了存储在数据库中的数据 比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等 所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我
-
在python中使用pyspark读写Hive数据操作
1.读Hive表数据 pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下: from pyspark.sql import HiveContext,SparkSession _SPARK_HOST = "spark://spark-master:7077" _APP_NAME = "test" spa