Tensorflow中使用tfrecord方式读取数据的方法
前言
本博客默认读者对神经网络与Tensorflow有一定了解,对其中的一些术语不再做具体解释。并且本博客主要以图片数据为例进行介绍,如有错误,敬请斧正。
使用Tensorflow训练神经网络时,我们可以用多种方式来读取自己的数据。如果数据集比较小,而且内存足够大,可以选择直接将所有数据读进内存,然后每次取一个batch的数据出来。如果数据较多,可以每次直接从硬盘中进行读取,不过这种方式的读取效率就比较低了。此篇博客就主要讲一下Tensorflow官方推荐的一种较为高效的数据读取方式——tfrecord。
从宏观来讲,tfrecord其实是一种数据存储形式。使用tfrecord时,实际上是先读取原生数据,然后转换成tfrecord格式,再存储在硬盘上。而使用时,再把数据从相应的tfrecord文件中解码读取出来。那么使用tfrecord和直接从硬盘读取原生数据相比到底有什么优势呢?其实,Tensorflow有和tfrecord配套的一些函数,可以加快数据的处理。实际读取tfrecord数据时,先以相应的tfrecord文件为参数,创建一个输入队列,这个队列有一定的容量(视具体硬件限制,用户可以设置不同的值),在一部分数据出队列时,tfrecord中的其他数据就可以通过预取进入队列,并且这个过程和网络的计算是独立进行的。也就是说,网络每一个iteration的训练不必等待数据队列准备好再开始,队列中的数据始终是充足的,而往队列中填充数据时,也可以使用多线程加速。
下面,本文将从以下4个方面对tfrecord进行介绍:
- tfrecord格式简介
- 利用自己的数据生成tfrecord文件
- 从tfrecord文件读取数据
- 实例测试
1. tfrecord格式简介
这部分主要参考了另一篇博文,Tensorflow 训练自己的数据集(二)(TFRecord)
tfecord文件中的数据是通过tf.train.Example Protocol Buffer的格式存储的,下面是tf.train.Example的定义
message Example {
Features features = 1;
};
message Features{
map<string,Feature> featrue = 1;
};
message Feature{
oneof kind{
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
从上述代码可以看出,tf.train.Example 的数据结构很简单。tf.train.Example中包含了一个从属性名称到取值的字典,其中属性名称为一个字符串,属性的取值可以为字符串(BytesList ),浮点数列表(FloatList )或整数列表(Int64List )。例如我们可以将图片转换为字符串进行存储,图像对应的类别标号作为整数存储,而用于回归任务的ground-truth可以作为浮点数存储。通过后面的代码我们会对tfrecord的这种字典形式有更直观的认识。
2. 利用自己的数据生成tfrecord文件
先上一段代码,然后我再针对代码进行相关介绍。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from scipy import misc
import scipy.io as sio
def _bytes_feature(value):
return tf.train.Feature(bytes_list = tf.train.BytesList(value=[value]))
def _int64_feature(value):
return tf.train.Feature(int64_list = tf.train.Int64List(value=[value]))
root_path = '/mount/temp/WZG/Multitask/Data/'
tfrecords_filename = root_path + 'tfrecords/train.tfrecords'
writer = tf.python_io.TFRecordWriter(tfrecords_filename)
height = 300
width = 300
meanfile = sio.loadmat(root_path + 'mats/mean300.mat')
meanvalue = meanfile['mean']
txtfile = root_path + 'txt/train.txt'
fr = open(txtfile)
for i in fr.readlines():
item = i.split()
img = np.float64(misc.imread(root_path + '/images/train_images/' + item[0]))
img = img - meanvalue
maskmat = sio.loadmat(root_path + '/mats/train_mats/' + item[1])
mask = np.float64(maskmat['seg_mask'])
label = int(item[2])
img_raw = img.tostring()
mask_raw = mask.tostring()
example = tf.train.Example(features=tf.train.Features(feature={
'height': _int64_feature(height),
'width': _int64_feature(width),
'name': _bytes_feature(item[0]),
'image_raw': _bytes_feature(img_raw),
'mask_raw': _bytes_feature(mask_raw),
'label': _int64_feature(label)}))
writer.write(example.SerializeToString())
writer.close()
fr.close()
代码中前两个函数(_bytes_feature和_int64_feature)是将我们的原生数据进行转换用的,尤其是图片要转换成字符串再进行存储。这两个函数的定义来自官方的示例。
接下来,我定义了数据的(路径-label文件)txtfile,它大概长这个样子:
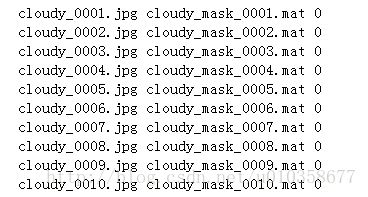
这里稍微啰嗦下,介绍一下我的实验内容。我做的是一个multi-task的实验,一支task做分割,一支task做分类。所以txtfile中每一行是一个样本,每个样本又包含3项,第一项为图片名称,第二项为相应的ground-truth segmentation mask的名称,第三项是图片的标签。(txtfile中内容形式无所谓,只要能读到想读的数据就可以)
接着回到主题继续讲代码,之后我又定义了即将生成的tfrecord的文件路径和名称,即tfrecord_filename,还有一个writer,这个writer是进行写操作用的。
接下来是图片的高度、宽度以及我事先在整个数据集上计算好的图像均值文件。高度、宽度其实完全没必要引入,这里只是为了说明tfrecord的生成而写的。而均值文件是为了对图像进行事先的去均值化操作而引入的,在大多数机器学习任务中,图像去均值化对提高算法的性能还是很有帮助的。
最后就是根据txtfile中的每一行进行相关数据的读取、转换以及tfrecord的生成了。首先是根据图片路径读取图片内容,然后图像减去之前读入的均值,接着根据segmentation mask的路径读取mask(如果只是图像分类任务,那么就不会有这些额外的mask),txtfile中的label读出来是string格式,这里要转换成int。然后图像和mask数据也要用相应的tosring函数转换成string。
真正的核心是下面这一小段代码:
example = tf.train.Example(features=tf.train.Features(feature={
'height': _int64_feature(height),
'width': _int64_feature(width),
'name': _bytes_feature(item[0]),
'image_raw': _bytes_feature(img_raw),
'mask_raw': _bytes_feature(mask_raw),
'label': _int64_feature(label)}))
writer.write(example.SerializeToString())
这里很好地体现了tfrecord的字典特性,tfrecord中每一个样本都是一个小字典,这个字典可以包含任意多个键值对。比如我这里就存储了图片的高度、宽度、图片名称、图片内容、mask内容以及图片的label。对于我的任务来说,其实height、width、name都不是必需的,这里仅仅是为了展示。键值对的键全都是字符串,键起什么名字都可以,只要能方便以后使用就可以。
定义好一个example后就可以用之前的writer来把它真正写入tfrecord文件了,这其实就跟把一行内容写入一个txt文件一样。代码的最后就是writer和txt文件对象的关闭了。
最后在指定文件夹下,就得到了指定名字的tfrecord文件,如下所示:
需要注意的是,生成的tfrecord文件比原生数据的大小还要大,这是正常现象。这种现象可能是因为图片一般都存储为jpg等压缩格式,而tfrecord文件存储的是解压后的数据。
3. 从tfrecord文件读取数据
还是代码先行。
from scipy import misc
import tensorflow as tf
import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt
root_path = '/mount/temp/WZG/Multitask/Data/'
tfrecord_filename = root_path + 'tfrecords/test.tfrecords'
def read_and_decode(filename_queue, random_crop=False, random_clip=False, shuffle_batch=True):
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'height': tf.FixedLenFeature([], tf.int64),
'width': tf.FixedLenFeature([], tf.int64),
'name': tf.FixedLenFeature([], tf.string),
'image_raw': tf.FixedLenFeature([], tf.string),
'mask_raw': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64)
})
image = tf.decode_raw(features['image_raw'], tf.float64)
image = tf.reshape(image, [300,300,3])
mask = tf.decode_raw(features['mask_raw'], tf.float64)
mask = tf.reshape(mask, [300,300])
name = features['name']
label = features['label']
width = features['width']
height = features['height']
# if random_crop:
# image = tf.random_crop(image, [227, 227, 3])
# else:
# image = tf.image.resize_image_with_crop_or_pad(image, 227, 227)
# if random_clip:
# image = tf.image.random_flip_left_right(image)
if shuffle_batch:
images, masks, names, labels, widths, heights = tf.train.shuffle_batch([image, mask, name, label, width, height],
batch_size=4,
capacity=8000,
num_threads=4,
min_after_dequeue=2000)
else:
images, masks, names, labels, widths, heights = tf.train.batch([image, mask, name, label, width, height],
batch_size=4,
capacity=8000,
num_threads=4)
return images, masks, names, labels, widths, heights
读取tfrecord文件中的数据主要是应用read_and_decode()这个函数,可以看到其中有个参数是filename_queue,其实我们并不是直接从tfrecord文件进行读取,而是要先利用tfrecord文件创建一个输入队列,如本文开头所述那样。关于这点,到后面真正的测试代码我再介绍。
在read_and_decode()中,一上来我们先定义一个reader对象,然后使用reader得到serialized_example,这是一个序列化的对象,接着使用tf.parse_single_example()函数对此对象进行初步解析。从代码中可以看到,解析时,我们要用到之前定义的那些键。对于图像、mask这种转换成字符串的数据,要进一步使用tf.decode_raw()函数进行解析,这里要特别注意函数里的第二个参数,也就是解析后的类型。之前图片在转成字符串之前是什么类型的数据,那么这里的参数就要填成对应的类型,否则会报错。对于name、label、width、height这样的数据就不用再解析了,我们得到的features对象就是个字典,利用键就可以拿到对应的值,如代码所示。
我注释掉的部分是用来做数据增强的,比如随机的裁剪与翻转,除了这两种,其他形式的数据增强也可以写在这里,读者可以根据自己的需要,决定是否使用各种数据增强方式。
函数最后就是使用解析出来的数据生成batch了。Tensorflow提供了两种方式,一种是shuffle_batch,这种主要是用在训练中,随机选取样本组成batch。另外一种就是按照数据在tfrecord中的先后顺序生成batch。对于生成batch的函数,建议读者去官网查看API文档进行细致了解。这里稍微做一下介绍,batch的大小,即batch_size就需要在生成batch的函数里指定。另外,capacity参数指定数据队列一次性能放多少个样本,此参数设置什么值需要视硬件环境而定。num_threads参数指定可以开启几个线程来向数据队列中填充数据,如果硬件性能不够强,最好设小一点,否则容易崩。
4. 实例测试
实际使用时先指定好我们需要使用的tfrecord文件:
root_path = '/mount/temp/WZG/Multitask/Data/' tfrecord_filename = root_path + 'tfrecords/test.tfrecords'
然后用该tfrecord文件创建一个输入队列:
filename_queue = tf.train.string_input_producer([tfrecord_filename],
num_epochs=3)
这里有个参数是num_epochs,指定好之后,Tensorflow自然知道如何读取数据,保证在遍历数据集的一个epoch中样本不会重复,也知道数据读取何时应该停止。
下面我将完整的测试代码贴出:
def test_run(tfrecord_filename):
filename_queue = tf.train.string_input_producer([tfrecord_filename],
num_epochs=3)
images, masks, names, labels, widths, heights = read_and_decode(filename_queue)
init_op = tf.group(tf.global_variables_initializer(),
tf.local_variables_initializer())
meanfile = sio.loadmat(root_path + 'mats/mean300.mat')
meanvalue = meanfile['mean']
with tf.Session() as sess:
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(1):
imgs, msks, nms, labs, wids, heis = sess.run([images, masks, names, labels, widths, heights])
print 'batch' + str(i) + ': '
#print type(imgs[0])
for j in range(4):
print nms[j] + ': ' + str(labs[j]) + ' ' + str(wids[j]) + ' ' + str(heis[j])
img = np.uint8(imgs[j] + meanvalue)
msk = np.uint8(msks[j])
plt.subplot(4,2,j*2+1)
plt.imshow(img)
plt.subplot(4,2,j*2+2)
plt.imshow(msk, vmin=0, vmax=5)
plt.show()
coord.request_stop()
coord.join(threads)
函数中接下来就是利用之前定义的read_and_decode()来得到一个batch的数据,此后我又读入了均值文件,这是因为之前做了去均值处理,如果要正常显示图片需要再把均值加回来。
再之后就是建立一个Tensorflow session,然后初始化对象。这些是Tensorflow基本操作,不再赘述。下面的这两句代码非常重要,是读取数据必不可少的。
coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord)
然后是运行sess.run()拿到实际数据,之前只是相当于定义好了,并没有得到真实数值。为了简单起见,我在之后的循环里只测试了一个batch的数据,关于tfrecord的标准使用我也建议读者去官网的数据读取部分看看示例。循环里对数据的各种信息进行了展示,结果如下:
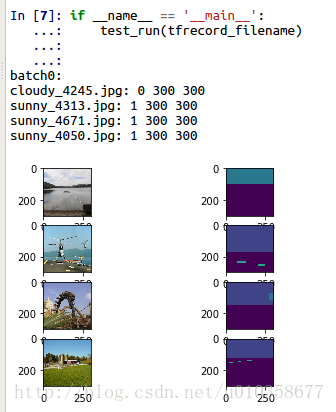
从图片的名字可以看出,数据的确是进行了shuffle的,标签、宽度、高度、图片本身以及对应的mask图像也全部展示出来了。
测试函数的最后,要使用以下两句代码进行停止,就如同文件需要close()一样:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Tensorflow使用tfrecord输入数据格式
Tensorflow 提供了一种统一的格式来存储数据,这个格式就是TFRecord,上一篇文章中所提到的方法当数据的来源更复杂,每个样例中的信息更丰富的时候就很难有效的记录输入数据中的信息了,于是Tensorflow提供了TFRecord来统一存储数据,接下来我们就来介绍如何使用TFRecord来同意输入数据的格式. 1. TFRecord格式介绍 TFRecord文件中的数据是通过tf.train.Example Protocol Buffer的格式存储的,下面是tf.train.Exampl
-
Tensorflow之构建自己的图片数据集TFrecords的方法
学习谷歌的深度学习终于有点眉目了,给大家分享我的Tensorflow学习历程. tensorflow的官方中文文档比较生涩,数据集一直采用的MNIST二进制数据集.并没有过多讲述怎么构建自己的图片数据集tfrecords. 流程是:制作数据集-读取数据集--加入队列 先贴完整的代码: #encoding=utf-8 import os import tensorflow as tf from PIL import Image cwd = os.getcwd() classes = {'test'
-
tensorflow TFRecords文件的生成和读取的方法
TensorFlow提供了TFRecords的格式来统一存储数据,理论上,TFRecords可以存储任何形式的数据. TFRecords文件中的数据都是通过tf.train.Example Protocol Buffer的格式存储的.以下的代码给出了tf.train.Example的定义. message Example { Features features = 1; }; message Features { map<string, Feature> feature = 1; }; mes
-
Tensorflow中使用tfrecord方式读取数据的方法
前言 本博客默认读者对神经网络与Tensorflow有一定了解,对其中的一些术语不再做具体解释.并且本博客主要以图片数据为例进行介绍,如有错误,敬请斧正. 使用Tensorflow训练神经网络时,我们可以用多种方式来读取自己的数据.如果数据集比较小,而且内存足够大,可以选择直接将所有数据读进内存,然后每次取一个batch的数据出来.如果数据较多,可以每次直接从硬盘中进行读取,不过这种方式的读取效率就比较低了.此篇博客就主要讲一下Tensorflow官方推荐的一种较为高效的数据读取方式--tfre
-
Python 中pandas索引切片读取数据缺失数据处理问题
引入 numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢? numpy能够帮我们处理处理数值型数据,但是这还不够 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等 比如:我们通过爬虫获取到了存储在数据库中的数据 比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等 所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我
-
TensorFlow实现从txt文件读取数据
TensorFlow从txt文件中读取数据的方法很多有种,我比较常用的是下面两种: [1]np.loadtxt import numpy as np data=np.loadtxt('ex1data1.txt',dtype='float',delimiter=',') X_train=data[:,0] y_train=data[:,1] [2]pd.read_csv import pandas as pd data=pd.read_csv("ex2data2.txt",names=[
-
Python3实现将文件归档到zip文件及从zip文件中读取数据的方法
本文实例讲述了Python3实现将文件归档到zip文件及从zip文件中读取数据的方法.分享给大家供大家参考.具体实现方法如下: ''''' Created on Dec 24, 2012 将文件归档到zip文件,并从zip文件中读取数据 @author: liury_lab ''' # 压缩成zip文件 from zipfile import * #@UnusedWildImport import os my_dir = 'd:/中华十大名帖/' myzip = ZipFile('d:/中华十大
-
从Java的jar文件中读取数据的方法
本文实例讲述了从Java的jar文件中读取数据的方法.分享给大家供大家参考.具体如下: Java 档案 (Java Archive, JAR) 文件是基于 Java 技术的打包方案.它们允许开发人员把所有相关的内容 (.class.图片.声音和支持文件等) 打包到一个单一的文件中.JAR 文件格式支持压缩.身份验证和版本,以及许多其它特性. 从 JAR 文件中得到它所包含的文件内容是件棘手的事情,但也不是不可以做到.这篇技巧就将告诉你如何从 JAR 文件中取得一个文件.我们会先取得这个 JAR
-

Python从文件中读取数据的方法步骤
一.读取整个文件内容 在读取文件之前,我们先创建一个文本文件resource.txt作为源文件. resource.txt my name is joker, I am 18 years old, How about you? 如何读取文件全部内容,我们编写到reader.py文件中. reader.py with open('resource.txt') as file_obj: content = file_obj.read() print(content) 需要注意的是需要将resourc
-
Java中I/O流读取数据不完整的问题解决
目录 一·问题描述: 二·问题原因: 三·解决办法: 四·测试结果:成功 一·问题描述: 1.利用Java的转换流去读取一个json文件数据,获取的数据无法被解析为json格式数据(格式总是报错),且获取的数据末尾缺少一部分数据. (1)Java源代码如图 (2)原json文件如图 (3)解析获取的数据如图:转换为json格式数据报错 二·问题原因: 1.最后一次缓存数组里面的数据,没有拼接到最终字符串数据里面 2.stringBuffer.append(buffer)拼接数据的方法,内部可能会
-
Android采用File形式保存与读取数据的方法
本文实例讲述了Android采用File形式保存与读取数据的方法.分享给大家供大家参考,具体如下: 将数据直接以文件的形式保存在设备中,通过Context.openFileInput()方法获得标准的JAVA文件输入流(FileInputStream),通过Context.openFileOutput()方法获得标准的JAVA文件输出流(FileOutputStream) 写数据到file文件中 findViewById(R.id.file).setOnClickListener(new But
-
Android开发中Listview动态加载数据的方法示例
本文实例讲述了Android开发中Listview动态加载数据的方法.分享给大家供大家参考,具体如下: 最近在研究网络数据加载的问题,比如我有几百,甚至上千条数据,这些数据如果一次性全部加载到arraylist,然后再加载到Listview中.我们必然会去单独开线程来做,这样造成的结果就是会出现等待时间很长,用户体验非常不好.我的想法是动态加载数据,第一次加载十条,然后往下面滑动的时候再追加十条,再往下面滑动的时候再去追加,这样大大减少了用户等待的时间,同时给处理数据留下了时间.网上看到了这样一
-
pandas进行数据的交集与并集方式的数据合并方法
数据合并有多种方式,其中最常见的应该就是交集和并集的求取.之前通过分析总结过pandas数据merge功能默认的行为,其实默认下求取的就是两个数据的"交集". 有如下数据定义: In [26]: df1 Out[26]: data1 key 0 0 b 1 1 b 2 2 a 3 3 c 4 4 a 5 5 a 6 6 b In [27]: df2 Out[27]: data2 key 0 0 a 1 1 b 2 2 d 3 3 b 进行merge的结果: In [28]: pd.me