python pandas 组内排序、单组排序、标号的实例
摘要:本文主要是讲解一下,如何进行排序。分为两种情况,不分组进行排序和组内进行排序。什么意思呢?具体来说,我举个栗子。
****注意****
如果只是单纯想对某一列进行排序,而不进行打序号的话直接使用.sort_values就可以了。下文是关于如何把序号也打上的
————————————————————————————
我们有一个数据集如下:

我们下面想进行两种排序。先说第一种比较简单的也是很常用的,简单的对某一列进行排序然后添加一列序号。
例如,我们队comment_num这一列进行从大到小的排序,然后给出序号。如下图:
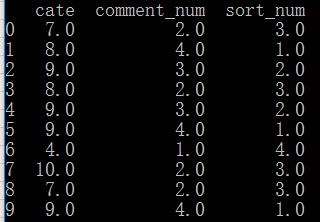
可以看到,sort_num这一列就是我们队comment_num的排序。
如何实现呢?很简单,代码如下(数据集为data):
data['sort_num']=data['comment_num'].rank(ascending=0,method='dense')
这里,我们用到了两个参数,第一个很好理解 ascending,就是选择是升序还是降序排列。
另外一个参数method,这个参数很重要。我下面详细讲一下。
有时候,我们排序的时候会遇到相同大小,这个时候怎么处理呢?method其实就是让我们选择如何处理。
有以下几种处理方案:
第一种情况,如果出现相等,则序号一样,之后序号照常递增。这种情况就是上图的,我们看到comment_num等于4的有2个,序号为1。comment_num等于3的时候,序号为2,这个叫做正常按1依次递增。这和时候method='dense'
第二种情况,如果出现相等,则取最先出现的值序号为“最小”,其他相同值依次按1递增,如果把上面代码method='first',就是实现这种效果,效果如下图:
data['sort_num']=data['comment_num'].rank(ascending=0,method='first')

comment_num中,4最大,并且第1行中的4最先出现,故序号为1。
第三种情况和第四种情况比较复杂。文字不好说明,下面直接放代码和效果。
当method='min'时
data['sort_num']=data['comment_num'].rank(ascending=0,method='min')

当method='max'时
data['sort_num']=data['comment_num'].rank(ascending=0,method='max')

--------------------------------分割线--------------------------------------
上面只是某一列的排序,下面是组内排序。什么是意思?同样看下面的例子
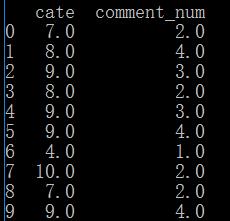
假如,我想对cate为7的comment_num进行排序,同样也对,cate为8的comment_num进行排序。也就是说,对comment_num排序的时候,只考虑相同的cate,这个就是对组内进行排序。
实现的效果应该如下图:

实现代码也很简单。
data['group_sort']=data['comment_num'].groupby(data['cate']).rank(ascending=0,method='dense')
以上这篇python pandas 组内排序、单组排序、标号的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python科学计算之Pandas详解
- Python pandas常用函数详解
- Python数据分析库pandas基本操作方法
- pandas数值计算与排序方法
相关推荐
-
Python pandas常用函数详解
本文研究的主要是pandas常用函数,具体介绍如下. 1 import语句 import pandas as pd import numpy as np import matplotlib.pyplot as plt import datetime import re 2 文件读取 df = pd.read_csv(path='file.csv') 参数:header=None 用默认列名,0,1,2,3... names=['A', 'B', 'C'...] 自定义列名 index_col='
-
pandas数值计算与排序方法
以下代码是基于python3.5.0编写的 import pandas food_info = pandas.read_csv("food_info.csv") # ---------------------特定列加减乘除------------------------- print(food_info["Iron_(mg)"]) div_1000 = food_info["Iron_(mg)"] / 1000 add_100 = food_in
-

Python科学计算之Pandas详解
起步 Pandas最初被作为金融数据分析工具而开发出来,因此 pandas 为时间序列分析提供了很好的支持. Pandas 的名称来自于面板数据(panel data)和python数据分析 (data analysis) .panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型. 在我看来,对于 Numpy 以及 Matplotlib ,Pandas可以帮助创建一个非常牢固的用于数据挖掘与分析的基础.而Scipy当然是另一个主要的也十分出色的科学计
-
Python数据分析库pandas基本操作方法
pandas是什么? 是它吗? ....很显然pandas没有这个家伙那么可爱.... 我们来看看pandas的官网是怎么来定义自己的: pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language. 很显然,pandas是python的一个非常强大的数据分析库! 让我们来学习一下它吧! 1.pandas序列 import nump
-
python pandas 组内排序、单组排序、标号的实例
摘要:本文主要是讲解一下,如何进行排序.分为两种情况,不分组进行排序和组内进行排序.什么意思呢?具体来说,我举个栗子. ****注意**** 如果只是单纯想对某一列进行排序,而不进行打序号的话直接使用.sort_values就可以了.下文是关于如何把序号也打上的 ---------------------------- 我们有一个数据集如下: 我们下面想进行两种排序.先说第一种比较简单的也是很常用的,简单的对某一列进行排序然后添加一列序号. 例如,我们队comment_num这一列进行从大到小的
-
pandas组内排序,并在每个分组内按序打上序号的操作
问题: pandas组内排序,并在每个分组内按序打上序号 描述: pandas dataframe 对dep_id组内的salary排序.希望给下面原本只有前三列的dataframe,添加上第四列. 等价于sql里的排序函数 row_number() over() 功能 假设我已经建好了仅有前三列的dataframe,数据集命名为 MyData, 解决方案如下: MyData['sort_id'] = MyData['salary'].groupby(MyData['dep_id']).rank
-
Python+Pandas 获取数据库并加入DataFrame的实例
实例如下所示: import pandas as pd import sys import imp imp.reload(sys) from sqlalchemy import create_engine import cx_Oracle db=cx_Oracle.connect('userid','password','10.10.1.10:1521/dbinstance') print db.version cr=db.cursor() sql='select * from sys_user
-
Python pandas求方差和标准差的方法实例
目录 准备 1.求方差 1.1对全表进行操作 1.1.1求取每列的方差 1.1.2 求取每行的方差 1.2 对单独的一行或者一列进行操作 1.2.1 求取单独某一列的方差 1.2.2 求取单独某一行的方差 1.3 对多行或者多列进行操作 1.3.1 求取多列的方差 1.3.2 求取多行的方差 2 求标准差 2.1对全表进行操作 2.1.1对每一列求标准差 2.1.2 对每一行求标准差 2.2 对单独的一行或者一列进行操作 2.2.1 对某一列求标准差 2.2.2 对某一行求标准差 2.3 对多行
-
pandas多级分组实现排序的方法
pandas有groupby分组函数和sort_values排序函数,但是如何对dataframe分组之后排序呢? In [70]: df = pd.DataFrame(((random.randint(2012, 2016), random.choice(['tech', 'art', 'office']), '%dk-%dk'%(random.randint(2,10), random.randint(10, 20)), '') for _ in xrange(10000)), column
-
Pandas 对Dataframe结构排序的实现方法
Dataframe结构放在numpy来看应该是二维矩阵的形式,每一列是一个特征,上面会有个列标题,每一行是一个样本. 对Dataframe结构的某一列进行排序方法如下: # 对df表中的user_id这一列进行排序,默认是从小到大排 df = df.sort_index(by='user_id') 对多列进行排序方法如下: # 对user_id,sku_id这两列进行排序 df = df.sort_index(by=['user_id', 'sku_id']) 以上这篇Pandas 对Dataf
-
python pandas 数据排序的几种常用方法
前言: pandas中排序的几种常用方法,主要包括sort_index和sort_values. 基础数据: import pandas as pd import numpy as np data = { 'brand':['Python', 'C', 'C++', 'C#', 'Java'], 'B':[4,6,8,12,10], 'A':[10,2,5,20,16], 'D':[6,18,14,6,12], 'years':[4,1,1,30,30], 'C':[8,12,18,8,2] }
-
Python Pandas数据处理高频操作详解
目录 引入依赖 算法相关依赖 获取数据 生成df 重命名列 增加列 缺失值处理 独热编码 替换值 删除列 数据筛选 差值计算 数据修改 时间格式转换 设置索引列 折线图 散点图 柱状图 热力图 66个最常用的pandas数据分析函数 从各种不同的来源和格式导入数据 导出数据 创建测试对象 查看.检查数据 数据选取 数据清理 筛选,排序和分组依据 数据合并 数据统计 16个函数,用于数据清洗 1.cat函数 2.contains 3.startswith/endswith 4.count 5.ge
-
基于python的七种经典排序算法(推荐)
一.排序的基本概念和分类 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法. 排序的稳定性: 经过某种排序后,如果两个记录序号同等,且两者在原无序记录中的先后秩序依然保持不变,则称所使用的排序方法是稳定的,反之是不稳定的. 内排序和外排序 内排序:排序过程中,待排序的所有记录全部放在内存中 外排序:排序过程中,使用到了外部存储. 通常讨论的都是内排序. 影响内排序算法性能的三个因素: 时间复杂度:即时间性能,高效
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几