分布式监控系统Zabbix3.2添加自动发现磁盘IO并注册监控(推荐)
服务器磁盘的运作情况在一定程度上反应系统的负载。
磁盘通常是服务器最慢的设备,极容易出现瓶颈,通过监控可以判断出整个系统的短板。
zabbix并没有给我们提供这么一个模板来完成在Linux中磁盘IO的监控,所以我们需要自己来创建一个,在此还是在Linux OS中添加。
由于一台服务器中磁盘众多,如果只一两台可以手动添加,但服务集群达到几十那就非常麻烦,因此需要利用自动发现 这个功能,自动发现后自动添加对服务器磁盘的监控,而且添加磁盘后也会自动添加到监控,实现自动化运维的效果,所以在这里也演示一次自动发现的配置。
打开Linux模板,添加自动发现规则

上面的key值是需要在 zabbix_agent.conf 中配置的
UserParameter=disk.discovery,/usr/local/share/zabbix/alertscripts/disk_discovery.sh
自动发面的规则用shell代码实现,返回一段磁盘的json list
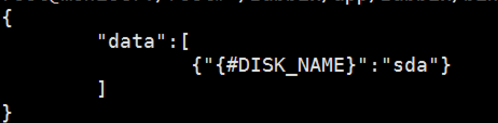
代码 disk_discovery.sh
#!/bin/bash
diskarray=(`cat /proc/diskstats |grep -E "\bsd[abcdefg]\b|\bxvd[abcdefg]\b"|grep -i "\b$1\b"|awk '{print $3}'|sort|uniq 2>/dev/null`)
length=${#diskarray[@]}
printf "{\n"
printf '\t'"\"data\":["
for ((i=0;i<$length;i++))
do
printf '\n\t\t{'
printf "\"{#DISK_NAME}\":\"${diskarray[$i]}\"}"
if [ $i -lt $[$length-1] ];then
printf ','
fi
done
printf "\n\t]\n"
printf "}\n"
到此自动发现磁盘已完,有点简单吧。
添加监控项
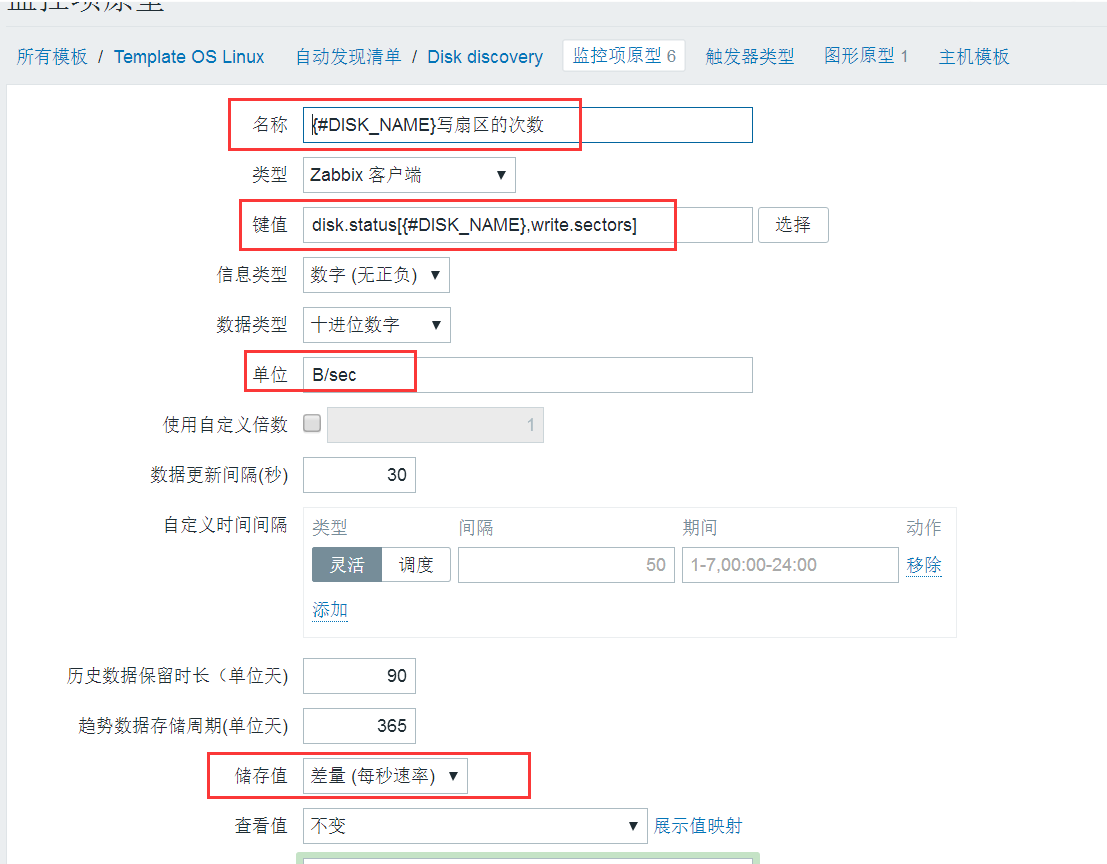
按照上面的内容添加第一个写扇区的次数监控,接下来按下面的内容添加共6个内容。
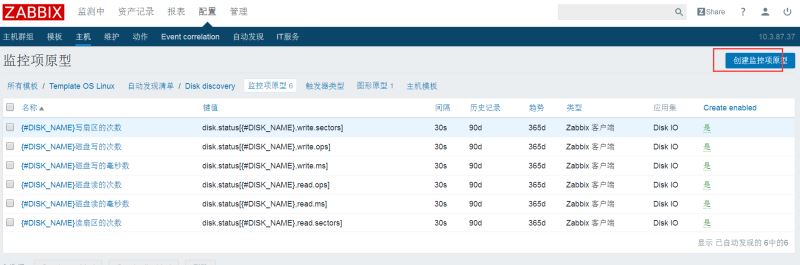
内容介绍
名称: {#DISK_NAME}磁盘读的次数
键值: disk.status[{#DISK_NAME},read.ops]
单位: ops/second
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘写的次数
键值: disk.status[{#DISK_NAME},write.ops]
单位: ops/second
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘读的毫秒数
键值: disk.status[{#DISK_NAME},read.ms]
单位: ms
储存值:差量(每秒速率)
名称: {#DISK_NAME}磁盘写的毫秒数
键值: disk.status[{#DISK_NAME},write.ms]
单位: ms
储存值:差量(每秒速率)
名称: {#DISK_NAME}读扇区的次数
键值: disk.status[{#DISK_NAME},read.sectors]
单位: B/sec
使用自定义倍数: 512
储存值:差量(每秒速率)
名称: {#DISK_NAME}写扇区的次数
键值: disk.status[{#DISK_NAME},write.sectors]
单位: B/sec
使用自定义倍数: 512
储存值:差量(每秒速率)
然后如果得到这些值是需要shell脚本的:
disk_status.sh
#/bin/sh
device=$1
DISK=$2
case $DISK in
read.ops)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $4}' #//磁盘读的次数
;;
read.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $7}' #//磁盘读的毫秒数
;;
write.ops)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $8}' #//磁盘写的次数
;;
write.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $11}' #//磁盘写的毫秒数
;;
io.active)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $12}' #//I/O的当前进度,
;;
read.sectors)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $6}' #//读扇区的次数(一个扇区的等于512B)
;;
write.sectors)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $10}' #//写扇区的次数(一个扇区的等于512B)
;;
io.ms)
/bin/cat /proc/diskstats | grep "\b$device\b" | head -1 | awk '{print $13}' #//花费在IO操作上的毫秒数
;;
esac
在客户端中的zabbix_agent.conf 中一起配置:
UserParameter=disk.discovery,/usr/local/share/zabbix/alertscripts/disk_discovery.sh UserParameter=disk.status[*],/usr/local/share/zabbix/alertscripts/disk_status.sh $1 $2
要注意的是以上两个文件需要给x 执行权限。
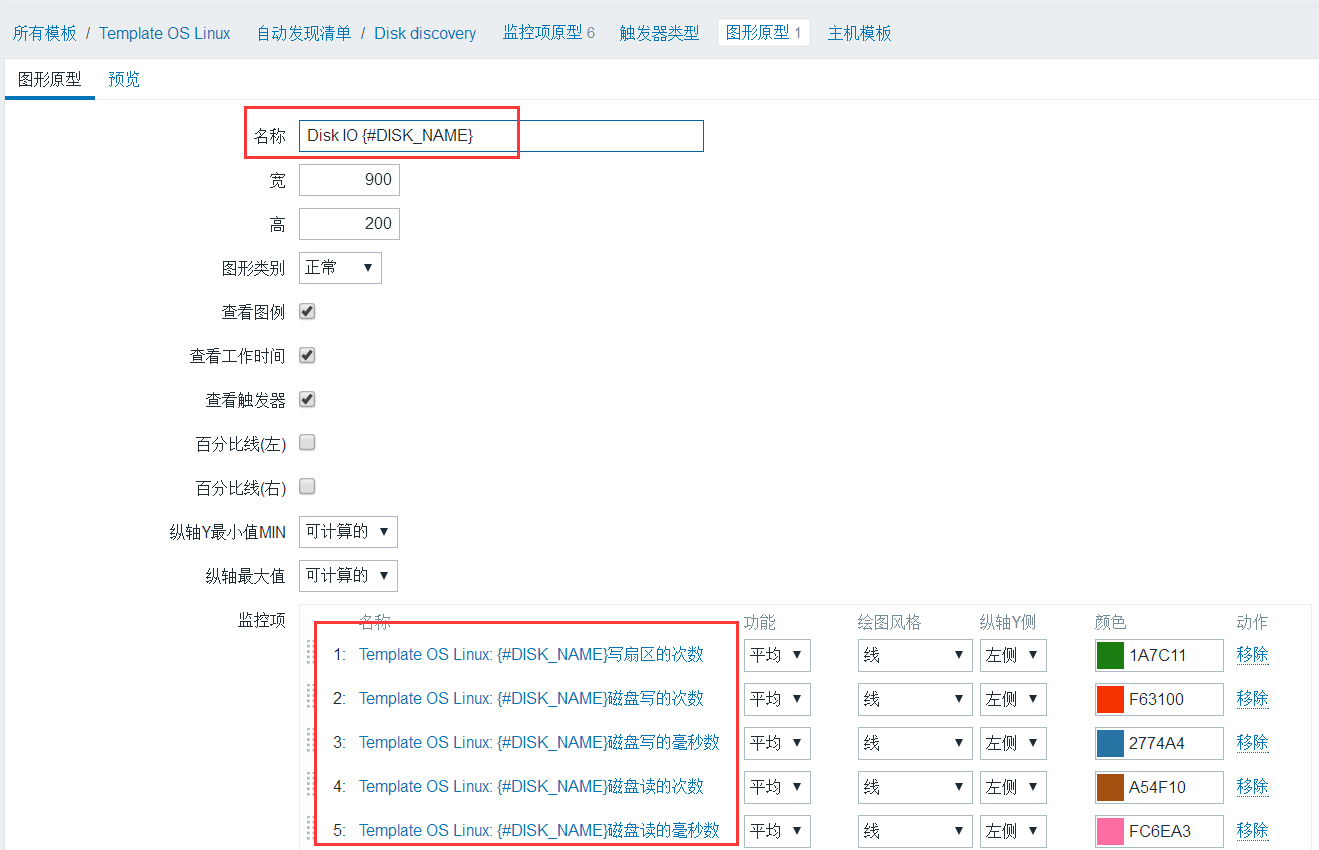
添加图形显示
在图形原型中添加,注意名称中要带哪个磁盘的动态名称,不然会出现Disk IO 已注册的错误信息。
zabbix3 Cannot create graph: graph with the same name "Disk IO" already exists
在监控项中选择上面添加的6个监控项。
测试效果
重启客户端的zabbix_agentd,然后在zabbix服务端对服务发现和写扇区次数进行测试。代码如下,有显示内容说明已经部署成功。


查看图形化,选择监控主机,图形中查看,若还没有项,需要等个几分钟再看。
问题:
网上有网友用的是python来实现自动发现功能,但测试发现老是报错:
python import: command not found

可能是依赖包有问题,考虑到集群服务器的python环境问题,因此就不考虑用python的实现。
总结
以上所述是小编给大家介绍的分布式监控系统Zabbix3.2添加自动发现磁盘IO并注册监控,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- 使用Java编写一个简单的Web的监控系统
- python使用wmi模块获取windows下的系统信息 监控系统
- Python写的一个简单监控系统
- shell脚本监控系统负载、CPU和内存使用情况
- 关于.NET/C#/WCF/WPF 打造IP网络智能视频监控系统的介绍
- 网上特工网络监控系统 5.63 企业超强版+补丁 下载
相关推荐
-
shell脚本监控系统负载、CPU和内存使用情况
在没有nagios监控软件的情况下,只要服务器能上互联网,就可通过发邮件的方式来提醒管理员系统负载与CPU占用的使用情况. 一.安装linux下面的一个邮件客户端msmtp软件(类似于一个foxmail的工具) 1.下载安装: http://downloads.sourceforge.net/msmtp/msmtp-1.4.16.tar.bz2?modtime=1217206451&big_mirror=0 复制代码 代码如下: # tar jxvf msmtp-1.4.16.tar.bz2
-

使用Java编写一个简单的Web的监控系统
公司的服务器需要实时监控,而且当用户空间已经满了,操作失败,或者出现程序Exception的时候就需要实时提醒,便于网管和程序员调式,这样就把这个实时监控系统分为了两部分, 第一部分:实时系统监控(cpu利用率,cpu温度,总内存大小,已使用内存大小) 第二部分:实时告警 由于无刷新实时性,所以只能使用Ajax,这里没有用到任何ajax框架,因为调用比较简单 大家知道,由于java的先天不足,对底层系统的调用和操作一般用jni来完成,特别是cpu温度,你在window下是打死用命令行是得不到
-
Python写的一个简单监控系统
市面上有很多开源的监控系统:Cacti.nagios.zabbix.感觉都不符合我的需求,为什么不自己做一个呢 用Python两个小时徒手撸了一个简易的监控系统,给大家分享一下,希望能对大家有所启发 首先数据库建表 建立一个数据库"falcon",建表语句如下: CREATE TABLE `stat` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `host` varchar(256) DEFAULT NULL, `mem_free`
-
关于.NET/C#/WCF/WPF 打造IP网络智能视频监控系统的介绍
OptimalVision网络视频监控系统 OptimalVision(OV)网络视频监控系统(Video Surveillance System),是一套基于.NET.C#.WCF.WPF等技术构建的IP网络视频监控系统.设计与实现该系统的初衷是希望在家用电脑中部署该系统,连接本地或局域网设备,通过浏览器或手机客户端浏览宝宝实时视频,也就是俗称的"宝宝在线"或"家庭看护". 但由于业余时间总是有限,完成系统中的服务.配置.采集.传输和桌面GUI部分后,继续完成后续
-
python使用wmi模块获取windows下的系统信息 监控系统
Python用WMI模块获取Windows系统的硬件信息:硬盘分区.使用情况,内存大小,CPU型号,当前运行的进程,自启动程序及位置,系统的版本等信息. 本文实例讲述了python使用wmi模块获取windows下的系统信息 监控系统 #!/usr/bin/env python # -*- coding: utf- -*- #http://www.cnblogs.com/liu-ke/ import wmi import os import sys import platform import
-
分布式监控系统Zabbix3.2添加自动发现磁盘IO并注册监控(推荐)
服务器磁盘的运作情况在一定程度上反应系统的负载. 磁盘通常是服务器最慢的设备,极容易出现瓶颈,通过监控可以判断出整个系统的短板. zabbix并没有给我们提供这么一个模板来完成在Linux中磁盘IO的监控,所以我们需要自己来创建一个,在此还是在Linux OS中添加. 由于一台服务器中磁盘众多,如果只一两台可以手动添加,但服务集群达到几十那就非常麻烦,因此需要利用自动发现 这个功能,自动发现后自动添加对服务器磁盘的监控,而且添加磁盘后也会自动添加到监控,实现自动化运维的效果,所以在这里也演示一次
-
解析Zabbix 5.0磁盘自动发现和读写监控的问题
自动发现磁盘 配置键值 注意:此键值仅支持Linux平台. 此发现键值返回两个宏 : {#DEVNAME} :设备名 {#DEVTYPE} :设备类型 例如: [ { "{#DEVNAME}":"loop1", "{#DEVTYPE}":"disk" }, { "{#DEVNAME}":"dm-0", "{#DEVTYPE}":"disk" },
-
分布式监控系统之Zabbix主动、被动及web监控的过程详解
前文我们了解了zabbix的网络发现功能,以及结合action实现自动发现主机并将主机添加到zabbix hosts中,链接指定模板进行监控:回顾请参考https://www.jb51.net/article/200678.htm:今天我们来了解下zabbix的主动监控.被动监控以及web监控相关话题: 1.什么是主动监控?什么是被动监控? 我们知道获取数据的方式有两种,一种是get,一种是push:在zabbix中描述主动监控和被动监控都是站在agent的一方来描述的:我们把agent主动将数
-
分布式监控系统之Zabbix 使用SNMP、JMX信道采集数据的原理解析
前文我们了解了zabbix的被动.主动以及web监控相关话题,回顾请参考https://www.jb51.net/article/200679.htm:今天我们来了解下zabbix使用SNMP和JMX信道采集数据的相关话题: 1.SNMP协议介绍 SNMP是英文"Simple Network Management Protocol"的缩写,中文意思是"简单网络管理协议,SNMP是一种简单网络管理协议,它属于TCP/IP五层协议中的应用层协议,用于网络管理的协议,SNMP主要用
-
Java 用Prometheus搭建实时监控系统过程详解
上帝之火 本系列讲述的是开源实时监控告警解决方案Prometheus,这个单词很牛逼.每次我都能联想到带来上帝之火的希腊之神,普罗米修斯.而这个开源的logo也是火,个人挺喜欢这个logo的设计. 本系列着重介绍Prometheus以及如何用它和其周边的生态来搭建一套属于自己的实时监控告警平台. 本系列受众对象为初次接触Prometheus的用户,大神勿喷,偏重于操作和实战,但是重要的概念也会精炼出提及下.系列主要分为以下几块 Prometheus各个概念介绍和搭建,如何抓取数据(本次分享内容)
-
eBay 打造基于 Apache Druid 的大数据实时监控系统
首先需要注意的是,本文即将提到的 Druid,并非阿里巴巴的 Druid 数据库连接池,而是另一个大数据场景下的解决方案:Apache Druid. Apache Druid 是一个用于大数据实时查询和分析的高容错.高性能开源分布式时序数据库系统,旨在快速处理大规模的数据,并能够实现快速查询和分析.尤其是当发生代码部署.机器故障以及其他产品系统遇到宕机等情况时,Druid 仍能够保持 100% 正常运行.创建 Druid 的最初意图主要是为了解决查询延迟问题,当时试图使用 Hadoop 来实现交
-
C# 实现视频监控系统(附源码)
去过工厂或者仓库的都知道,在工厂或仓库里面,会有很多不同的流水线,大部分的工厂或仓库,都会在不同流水线的不同工位旁边安装一台电脑,一方面便于工位上的师傅把产品的重要信息录入系统,便于公司系统数据采集分析.另一方面严谨的工厂或仓库也会在每个工位上安装摄像头,用于采集或监控流水线上工人的操(是)作(否)习(偷)惯(懒). 好了,闲话少说,咱们直入主题吧! 本系统监控系统,主要核心是使用AForge.NET提供的接口和插件(dll),感兴趣的朋友也可以去他们官网查看文档http://www.aforg
-
.NET程序性能监控系统Elastic AMP的使用方法
目录 什么是Elastic AMP 工作原理 代码演示 1.新增Web项目 2.新增Nuget包 3.配置HttpModule 4.配置Agent 5.启动网站 Elastic APM核心模块 1.Transaction:我们通过Transaction可以看其中Api的调用信息 2. Dependencies:通过Dependencies看到服务依赖关系 3. Error: 能通过Error看到程序中的错误信息 4. Matrics: 可以通过Matrics看到服务气的内存与CPU信息 Elas
-
JavaScript架构前端不能没有监控系统原因
目录 监控系统 前端监控具体能解决什么问题? 异常报错问题 性能检测问题 运营反馈工具 为什么要选择自研? 自研前端监控的技术栈 监控系统 提到监控系统,大部分同学首先想到的是后端监控.很明显,比如检测服务器性能,数据库性能,API 的访问流量,以及各种服务的运行情况等等,都与后端息息相关.而前端更多承担的是 UI 展现的角色,主要关注页面怎么排版设计,好像没什么需要监测的地方,因此一直以来都没有涉及到监控的概念. 于是呢大家就一致认为:只要后端稳定可控,应用就是稳定可控的,可实际情况真的是这样