浅谈python str.format与制表符\t关于中文对齐的细节问题
写了一个练手的爬虫...在输出的时候出现了让人很不愉♂悦的问题
像这样:
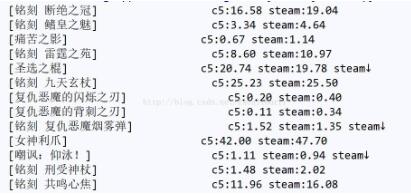
令人十分难受啊!
#------------------------------------------
在此之前先说一下python中的.format格式化输出

python2.6开始,可以使用str.format进行轻松的格式化,
如上可以看到,对变量的处理简洁灵活,此外对数字的各种位数处理也很到位
{:<x}的语法表示左对齐(>为右对齐,^为居中),少于x位自动补齐(默认为空格补齐)
这里值得注意的是,x也可以作为变量代入:

#------------------------------------------
着手解决问题,
第一反应使用\t制表符,带来的问题便是字符串长度差距超过一个制表位时,会跳到下一个制表位,如图:

不能接受,使用str.format补齐name属性的长度为25
结果却是这样的:
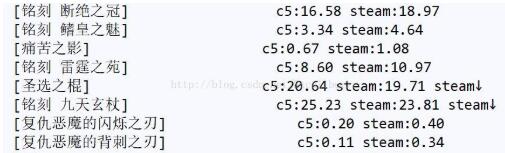
py虽好,有些细节还是没有照顾到中文
这里补齐长度时中文字符也按1字节计算了,
然而我们知道,utf-8中中文占用3个字节,GBK中占用了2个字节,只算作1字节显然不能对齐
这时求助于prettytable包输出表格,然而输出也不理想,可以想象也没有考虑中文编码的问题(或是需要设置编码为utf-8或gbk?)
分析一下理想的name所占的长度,应为固定的x字节(这里按目前的爬取结果暂时取22)
那么他的补齐长度应为
len = 22 - gbk编码下name的字节数 + name的字符数
幸运的是str.format支持使用变量代替补齐长度的值
尝试以下代码:
print('[{name:<{len}}x'.format(name=name+']',len=22-len(name.encode('GBK'))+len(name)))
结果十分接近理想了:
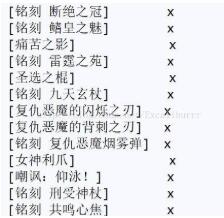
还是有一些迷之问题导致1-0.5字节长度的偏差,猜测是由于中文字体不是等宽字体的缘故?
然而不用多虑,这里就可以使用一记粗暴的制表符\t解决问题了
print('[{name:<{len}}\tx'.format(name=name+']',len=22-len(name.encode('GBK'))+len(name)))
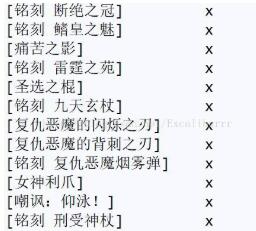
大功告成!锵锵!
#------------------------------------------
后话
这次写的主要是一个爬取几个主要交易网站以及steam上dota2饰品价格的爬虫,里面遇到的问题其实也挺多的比如登录动态加载等等
等写的比较完善了大概也会一起发上来啦~
以上这篇浅谈python str.format与制表符\t关于中文对齐的细节问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
解决Python 中英文混输格式对齐的问题
Python中使用str.format进行格式化输出 format使用方法较多,这里只说明其在填充与对齐上的使用方法: 填充与对齐 填充常跟对齐一起使用 ^.<.>分别是居中.左对齐.右对齐,后面带宽度 :号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充 例如: ulist.append([1,"清华大学","10" ]) ulist.append([2,"中国科学技术大学","10"]) ulist
-
Python中str.format()详解
1. str.format 的引入 在 Python 中,我们可以使用 + 来连接字符串,在简单情况下这种方式能够很好的工作.但是当我们需要进行复杂的字符串连接时,如果依然使用 + 来完成,不仅会使代码变得晦涩难懂,还会让代码变得难以维护,此时这种方式就显得力不从心了. 例如,我们想打印这样一条记录: User:John has completed Action:payment at Time:13:30:00 如果使用加号实现,会是下面这种形式: print "User:" + us
-
Python中字符串格式化str.format的详细介绍
前言 Python 在 2.6 版本中新加了一个字符串格式化方法: str.format() .它的基本语法是通过 {} 和 : 来代替以前的 %.. 格式化时的占位符语法: replacement_field ::= "{" [field_name] ["!" conversion] [":" format_spec] "}" "映射"规则 通过位置 str.format() 可以接受不限个参数,位置可以
-
python的格式化输出(format,%)实例详解
皇城PK Python中格式化字符串目前有两种阵营:%和format,我们应该选择哪种呢? 自从Python2.6引入了format这个格式化字符串的方法之后,我认为%还是format这根本就不算个问题.不信你往下看. # 定义一个坐标值 c = (250, 250) # 使用%来格式化 s1 = "敌人坐标:%s" % c 上面的代码很明显会抛出一个如下的TypeError: TypeError: not all arguments converted during string f
-
浅谈python str.format与制表符\t关于中文对齐的细节问题
写了一个练手的爬虫...在输出的时候出现了让人很不愉♂悦的问题 像这样: 令人十分难受啊! #------------------------------------------ 在此之前先说一下python中的.format格式化输出 python2.6开始,可以使用str.format进行轻松的格式化, 如上可以看到,对变量的处理简洁灵活,此外对数字的各种位数处理也很到位 {:<x}的语法表示左对齐(>为右对齐,^为居中),少于x位自动补齐(默认为空格补齐) 这里值得注意的是,x也可以作为
-
浅谈Python 字符串格式化输出(format/printf)
Python 字符串格式化使用 "字符 %格式1 %格式2 字符"%(变量1,变量2),%格式表示接受变量的类型.简单的使用例子如下: # 例:字符串格式化 Name = '17jo' print 'www.%s.com'%Name >> www.17jo.com Name = '17jo' Zone = 'com' print 'www.%s.%s'%(Name,Zone) >> www.17jo.com 字符串格式化时百分号后面有不同的格式符号,代表
-
浅谈python中str字符串和unicode对象字符串的拼接问题
str字符串 s = '中文' # s: <type 'str'> s是个str对象,中文字符串.存储方式是字节码.字节码是怎么存的: 如果这行代码在python解释器中输入&运行,那么s的格式就是解释器的编码格式: 如果这行代码是在源码文件中写入.保存然后执行,那么解释器载入代码时就将s初始化为文件指定编码(比如py文件开头那行的utf-8): unicode对象字符串 unicode是一种编码标准,具体的实现可能是utf-8,utf-16,gbk等等,这就是中文字符串和unicod
-
浅谈Python数学建模之数据导入
目录 一.数据导入是所有数模编程的第一步 二.在程序中直接向变量赋值 2.1.为什么直接赋值? 2.2.直接赋值的问题与注意事项 三.Pandas 导入数据 3.1.Pandas 读取 Excel 文件 3.2.Pandas 读取 csv 文件 3.3.Pandas 读取文本文件 3.4.Pandas 读取其它文件格式 四.数据导入例程 一.数据导入是所有数模编程的第一步 编程求解一个数模问题,问题总会涉及一些数据. 有些数据是在题目的文字描述中给出的,有些数据是通过题目的附件文件下载或指定网址
-

浅谈python中的数字类型与处理工具
python中的数字类型工具 python中为更高级的工作提供很多高级数字编程支持和对象,其中数字类型的完整工具包括: 1.整数与浮点型, 2.复数, 3.固定精度十进制数, 4.有理分数, 5.集合, 6.布尔类型 7.无穷的整数精度 8.各种数字内置函数及模块. 基本数字类型 python中提供了两种基本类型:整数(正整数金额负整数)和浮点数(注:带有小数部分的数字),其中python中我们可以使用多种进制的整数.并且整数可以用有无穷精度. 整数的表现形式以十进制数字字符串写法出现,浮点数带
-
浅谈python数据类型及其操作
一. Number 数字 1.内置函数:需要导入math 2.随机数函数:需要导入random 模块 3.三角函数:需要导入math模块 4.数学常量:需要导入math模块 #1.数据函数的使用 #========================== #内置函数 print(abs(-10)) #10绝对值 print(round(4.56789,2)) #4.57 使用四舍五入的方式保留小数点后两位 a = [10,30,20,80,50] print(max(a)) #80 最大值 prin
-
浅谈python中列表、字符串、字典的常用操作
列表操作如此下: a = ["haha","xixi","baba"] 增:a.append[gg] a.insert[1,gg] 在下标为1的地方,新增 gg 删:a.remove(haha) 删除列表中从左往右,第一个匹配到的 haha del a.[0] 删除下标为0 对应的值 a.pop(0) 括号里不写内容,默认删除最后一个,写了,就删除对应下标的内容 改:a.[0] = "gg" 查:a[0] a.index(&q
-
浅谈Python数据类型之间的转换
Python数据类型之间的转换 函数 描述 int(x [,base]) 将x转换为一个整数 long(x [,base] ) 将x转换为一个长整数 float(x) 将x转换到一个浮点数 complex(real [,imag]) 创建一个复数 str(x) 将对象 x 转换为字符串 repr(x) 将对象 x 转换为表达式字符串 eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象 tuple(s) 将序列 s 转换为一个元组 list(s) 将序列 s 转换为一个
-
浅谈Python基础之I/O模型
一.I/O模型 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口. 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别? 这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blockin
-
浅谈python for循环的巧妙运用(迭代、列表生成式)
介绍 我们可以通过for循环来迭代list.tuple.dict.set.字符串,dict比较特殊dict的存储不是连续的,所以迭代(遍历)出来的值的顺序也会发生变化. 迭代(遍历) #!/usr/bin/env python3 #-*- coding:utf-8 -*- vlist=['a','b','c'] vtuple=('a','b','c') vdict={'a': 1, 'b': 2, 'c': 3} vset={'a','b','c'} vstr='abc' for x in vl