编写高性能JavaScript(译)
译者按:本人第一次翻译外文,言语难免有些晦涩,但尽量表达了作者的原意,未经过多的润色,欢迎批评指正。另本文篇幅较长、信息量大,可能难以消化,欢迎留言探讨细节问题。本文主要关注V8的性能优化,部分内容并不适用于所有JS引擎。最后,转载请注明出处: )
========================译文分割线===========================
很多JavaScript引擎,如Google的V8引擎(被Chrome和Node所用),是专门为需要快速执行的大型JavaScript应用所设计的。如果你是一个开发者,并且关心内存使用情况与页面性能,你应该了解用户浏览器中的JavaScript引擎是如何运作的。无论是V8,SpiderMonkey的(Firefox)的Carakan(Opera),Chakra(IE)或其他引擎,这样做可以帮助你更好地优化你的应用程序。这并不是说应该专门为某一浏览器或引擎做优化,千万别这么做。
但是,你应该问自己几个问题:
- 在我的代码里,是否可以使代码更高效一些
- 主流的JavaScript引擎都做了哪些优化
- 什么是引擎无法优化的,垃圾回收器(GC)是否能回收我所期望的东西

加载快速的网站就像是一辆快速的跑车,需要用到特别定制的零件. 图片来源: dHybridcars.
编写高性能代码时有一些常见的陷阱,在这篇文章中,我们将展示一些经过验证的、更好的编写代码方式。
那么,JavaScript在V8里是如何工作的?
如果你对JS引擎没有较深的了解,开发一个大型Web应用也没啥问题,就好比会开车的人也只是看过引擎盖而没有看过车盖内的引擎一样。鉴于Chrome是我的浏览器首选,所以谈一下它的JavaScript引擎。V8是由以下几个核心部分组成:
- 一个基本的编译器,它会在代码执行前解析JavaScript代码并生成本地机器码,而不是执行字节码或简单地解释它。这些代码最开始并不是高度优化的。
- V8将对象构建为对象模型。在JavaScript中对象表现为关联数组,但是在V8中对象被看作是隐藏的类,一个为了优化查询的内部类型系统。
- 运行时分析器监视正在运行的系统,并标识了“hot”的函数(例如花费很长时间运行的代码)。
- 优化编译器重新编译和优化那些被运行时分析器标识为“hot”的代码,并进行“内联”等优化(例如用被调用者的主体替换函数调用的位置)。
- V8支持去优化,这意味着优化编译器如果发现对于代码优化的假设过于乐观,它会舍弃优化过的代码。
- V8有个垃圾收集器,了解它是如何工作的和优化JavaScript一样重要。
垃圾回收
垃圾回收是内存管理的一种形式,其实就是一个收集器的概念,尝试回收不再被使用的对象所占用的内存。在JavaScript这种垃圾回收语言中,应用程序中仍在被引用的对象不会被清除。
手动消除对象引用在大多数情况下是没有必要的。通过简单地把变量放在需要它们的地方(理想情况下,尽可能是局部作用域,即它们被使用的函数里而不是函数外层),一切将运作地很好。

垃圾回收器尝试回收内存. 图片来源: Valtteri Mäki.
在JavaScript中,是不可能强制进行垃圾回收的。你不应该这么做,因为垃圾收集过程是由运行时控制的,它知道什么是最好的清理时机。
“消除引用”的误解
网上有许多关于JavaScript内存回收的讨论都谈到delete这个关键字,虽然它可以被用来删除对象(map)中的属性(key),但有部分开发者认为它可以用来强制“消除引用”。建议尽可能避免使用delete,在下面的例子中delete o.x 的弊大于利,因为它改变了o的隐藏类,并使它成为一个"慢对象"。
var o = { x: 1 };
delete o.x; // true
o.x; // undefined
你会很容易地在流行的JS库中找到引用删除——这是具有语言目的性的。这里需要注意的是避免在运行时修改”hot”对象的结构。JavaScript引擎可以检测出这种“hot”的对象,并尝试对其进行优化。如果对象在生命周期中其结构没有较大的改变,引擎将会更容易优化对象,而delete操作实际上会触发这种较大的结构改变,因此不利于引擎的优化。
对于null是如何工作也是有误解的。将一个对象引用设置为null,并没有使对象变“空”,只是将它的引用设置为空而已。使用o.x= null比使用delete会更好些,但可能也不是很必要。
var o = { x: 1 };
o = null;
o; // null
o.x // TypeError
如果此引用是当前对象的最后引用,那么该对象将被作为垃圾回收。如果此引用不是当前对象的最后引用,则该对象是可访问的且不会被垃圾回收。
另外需要注意的是,全局变量在页面的生命周期里是不被垃圾回收器清理的。无论页面打开多久,JavaScript运行时全局对象作用域中的变量会一直存在。
var myGlobalNamespace = {};
全局对象只会在刷新页面、导航到其他页面、关闭标签页或退出浏览器时才会被清理。函数作用域的变量将在超出作用域时被清理,即退出函数时,已经没有任何引用,这样的变量就被清理了。
经验法则
为了使垃圾回收器尽早收集尽可能多的对象,不要hold着不再使用的对象。这里有几件事需要记住:
- 正如前面提到的,在合适的范围内使用变量是手动消除引用的更好选择。即一个变量只在一个函数作用域中使用,就不要在全局作用域声明它。这意味着更干净省心的代码。
- 确保解绑那些不再需要的事件监听器,尤其是那些即将被销毁的DOM对象所绑定的事件监听器。
- 如果使用的数据缓存在本地,确保清理一下缓存或使用老化机制,以避免大量不被重用的数据被存储。
函数
接下来,我们谈谈函数。正如我们已经说过,垃圾收集的工作原理,是通过回收不再是访问的内存块(对象)。为了更好地说明这一点,这里有一些例子。
function foo() {
var bar = new LargeObject();
bar.someCall();
}
当foo返回时,bar指向的对象将会被垃圾收集器自动回收,因为它已没有任何存在的引用了。
对比一下:
function foo() {
var bar = new LargeObject();
bar.someCall();
return bar;
}
// somewhere else
var b = foo();
现在我们有一个引用指向bar对象,这样bar对象的生存周期就从foo的调用一直持续到调用者指定别的变量b(或b超出范围)。
闭包(CLOSURES)
当你看到一个函数,返回一个内部函数,该内部函数将获得范围外的访问权,即使在外部函数执行之后。这是一个基本的闭包 —— 可以在特定的上下文中设置的变量的表达式。例如:
function sum (x) {
function sumIt(y) {
return x + y;
};
return sumIt;
}
// Usage
var sumA = sum(4);
var sumB = sumA(3);
console.log(sumB); // Returns 7
在sum调用上下文中生成的函数对象(sumIt)是无法被回收的,它被全局变量(sumA)所引用,并且可以通过sumA(n)调用。
让我们来看看另外一个例子,这里我们可以访问变量largeStr吗?
var a = function () {
var largeStr = new Array(1000000).join('x');
return function () {
return largeStr;
};
}();
是的,我们可以通过a()访问largeStr,所以它没有被回收。下面这个呢?
var a = function () {
var smallStr = 'x';
var largeStr = new Array(1000000).join('x');
return function (n) {
return smallStr;
};
}();
我们不能再访问largeStr了,它已经是垃圾回收候选人了。【译者注:因为largeStr已不存在外部引用了】
定时器
最糟的内存泄漏地方之一是在循环中,或者在setTimeout()/ setInterval()中,但这是相当常见的。思考下面的例子:
var myObj = {
callMeMaybe: function () {
var myRef = this;
var val = setTimeout(function () {
console.log('Time is running out!');
myRef.callMeMaybe();
}, 1000);
}
};
如果我们运行myObj.callMeMaybe();来启动定时器,可以看到控制台每秒打印出“Time is running out!”。如果接着运行myObj = null,定时器依旧处于激活状态。为了能够持续执行,闭包将myObj传递给setTimeout,这样myObj是无法被回收的。相反,它引用到myObj的因为它捕获了myRef。这跟我们为了保持引用将闭包传给其他的函数是一样的。
同样值得牢记的是,setTimeout/setInterval调用(如函数)中的引用,将需要执行和完成,才可以被垃圾收集。
当心性能陷阱
永远不要优化代码,直到你真正需要。现在经常可以看到一些基准测试,显示N比M在V8中更为优化,但是在模块代码或应用中测试一下会发现,这些优化真正的效果比你期望的要小的多。

做的过多还不如什么都不做. 图片来源: Tim Sheerman-Chase.
比如我们想要创建这样一个模块:
- 需要一个本地的数据源包含数字ID
- 绘制包含这些数据的表格
- 添加事件处理程序,当用户点击的任何单元格时切换单元格的css class
这个问题有几个不同的因素,虽然也很容易解决。我们如何存储数据,如何高效地绘制表格并且append到DOM中,如何更优地处理表格事件?
面对这些问题最开始(天真)的做法是使用对象存储数据并放入数组中,使用jQuery遍历数据绘制表格并append到DOM中,最后使用事件绑定我们期望地点击行为。
注意:这不是你应该做的
var moduleA = function () {
return {
data: dataArrayObject,
init: function () {
this.addTable();
this.addEvents();
},
addTable: function () {
for (var i = 0; i < rows; i++) {
$tr = $('<tr></tr>');
for (var j = 0; j < this.data.length; j++) {
$tr.append('<td>' + this.data[j]['id'] + '</td>');
}
$tr.appendTo($tbody);
}
},
addEvents: function () {
$('table td').on('click', function () {
$(this).toggleClass('active');
});
}
};
}();
这段代码简单有效地完成了任务。
但在这种情况下,我们遍历的数据只是本应该简单地存放在数组中的数字型属性ID。有趣的是,直接使用DocumentFragment和本地DOM方法比使用jQuery(以这种方式)来生成表格是更优的选择,当然,事件代理比单独绑定每个td具有更高的性能。
要注意虽然jQuery在内部使用DocumentFragment,但是在我们的例子中,代码在循环内调用append并且这些调用涉及到一些其他的小知识,因此在这里起到的优化作用不大。希望这不会是一个痛点,但请务必进行基准测试,以确保自己代码ok。
对于我们的例子,上述的做法带来了(期望的)性能提升。事件代理对简单的绑定是一种改进,可选的DocumentFragment也起到了助推作用。
var moduleD = function () {
return {
data: dataArray,
init: function () {
this.addTable();
this.addEvents();
},
addTable: function () {
var td, tr;
var frag = document.createDocumentFragment();
var frag2 = document.createDocumentFragment();
for (var i = 0; i < rows; i++) {
tr = document.createElement('tr');
for (var j = 0; j < this.data.length; j++) {
td = document.createElement('td');
td.appendChild(document.createTextNode(this.data[j]));
frag2.appendChild(td);
}
tr.appendChild(frag2);
frag.appendChild(tr);
}
tbody.appendChild(frag);
},
addEvents: function () {
$('table').on('click', 'td', function () {
$(this).toggleClass('active');
});
}
};
}();
接下来看看其他提升性能的方式。你也许曾经在哪读到过使用原型模式比模块模式更优,或听说过使用JS模版框架性能更好。有时的确如此,不过使用它们其实是为了代码更具可读性。对了,还有预编译!让我们看看在实践中表现的如何?
moduleG = function () {};
moduleG.prototype.data = dataArray;
moduleG.prototype.init = function () {
this.addTable();
this.addEvents();
};
moduleG.prototype.addTable = function () {
var template = _.template($('#template').text());
var html = template({'data' : this.data});
$tbody.append(html);
};
moduleG.prototype.addEvents = function () {
$('table').on('click', 'td', function () {
$(this).toggleClass('active');
});
};
var modG = new moduleG();
事实证明,在这种情况下的带来的性能提升可以忽略不计。模板和原型的选择并没有真正提供更多的东西。也就是说,性能并不是开发者使用它们的原因,给代码带来的可读性、继承模型和可维护性才是真正的原因。
更复杂的问题包括高效地在canvas上绘制图片和操作带或不带类型数组的像素数据。
在将一些方法用在你自己的应用之前,一定要多了解这些方案的基准测试。也许有人还记得JS模版的shoot-off和随后的扩展版。你要搞清楚基准测试不是存在于你看不到的那些虚拟应用,而是应该在你的实际代码中去测试带来的优化。
V8优化技巧
详细介绍了每个V8引擎的优化点在本文讨论范围之外,当然这里也有许多值得一提的技巧。记住这些技巧你就能减少那些性能低下的代码了。
- 特定模式可以使V8摆脱优化的困境,比如说try-catch。欲了解更多有关哪些函数能或不能进行优化,你可以在V8的脚本工具d8中使用–trace-opt file.js命令。
- 如果你关心速度,尽量使你的函数职责单一,即确保变量(包括属性,数组,函数参数)只使用相同隐藏类包含的对象。举个例子,别这么干:
function add(x, y) { return x+y; } add(1, 2); add('a','b'); add(my_custom_object, undefined); - 不要加载未初始化或已删除的元素。如果这么做也不会出现什么错误,但是这样会使速度变慢。
- 不要使函数体过大,这样会使得优化更加困难。
更多内容可以去看Daniel Clifford在Google I/O的分享 Breaking the JavaScript Speed Limit with V8。 Optimizing For V8 — A Series也非常值得一读。
对象VS数组:我应该用哪个?
- 如果你想存储一串数字,或者一些相同类型的对象,使用一个数组。
- 如果你语义上需要的是一堆的对象的属性(不同类型的),使用一个对象和属性。这在内存方面非常高效,速度也相当快。
- 整数索引的元素,无论存储在一个数组或对象中,都要比遍历对象的属性快得多。
- 对象的属性比较复杂:它们可以被setter们创建,具有不同的枚举性和可写性。数组中则不具有如此的定制性,而只存在有和无这两种状态。在引擎层面,这允许更多存储结构方面的优化。特别是当数组中存在数字时,例如当你需要容器时,不用定义具有x,y,z属性的类,而只用数组就可以了。
JavaScript中对象和数组之间只有一个的主要区别,那就是数组神奇的length属性。如果你自己来维护这个属性,那么V8中对象和数组的速度是一样快的。
使用对象时的技巧
- 使用一个构造函数来创建对象。这将确保它创建的所有对象具有相同的隐藏类,并有助于避免更改这些类。作为一个额外的好处,它也略快于Object.create()
- 你的应用中,对于使用不同类型的对象和其复杂度(在合理的范围内:长原型链往往是有害的,呈现只有一个极少数属性的对象比大对象会快一点)是有没限制的。对于“hot”对象,尽量保持短原型链,并且少属性。
对象克隆
对于应用程序开发人员,对象克隆是一个常见的问题。虽然各种基准测试可以证明V8对这个问题处理得很好,但仍要小心。复制大的东西通常是较慢的——不要这么做。JS中的for..in循环尤其糟糕,因为它有着恶魔般的规范,并且无论是在哪个引擎中,都可能永远不会比任何对象快。
当你一定要在关键性能代码路径上复制对象时,使用数组或一个自定义的“拷贝构造函数”功能明确地复制每个属性。这可能是最快的方式:
function clone(original) {
this.foo = original.foo;
this.bar = original.bar;
}
var copy = new clone(original);
模块模式中缓存函数
使用模块模式时缓存函数,可能会导致性能方面的提升。参阅下面的例子,因为它总是创建成员函数的新副本,你看到的变化可能会比较慢。
另外请注意,使用这种方法明显更优,不仅仅是依靠原型模式(经过jsPerf测试确认)。

使用模块模式或原型模式时的性能提升
这是一个原型模式与模块模式的性能对比测试:
// Prototypal pattern
Klass1 = function () {}
Klass1.prototype.foo = function () {
log('foo');
}
Klass1.prototype.bar = function () {
log('bar');
}
// Module pattern
Klass2 = function () {
var foo = function () {
log('foo');
},
bar = function () {
log('bar');
};
return {
foo: foo,
bar: bar
}
}
// Module pattern with cached functions
var FooFunction = function () {
log('foo');
};
var BarFunction = function () {
log('bar');
};
Klass3 = function () {
return {
foo: FooFunction,
bar: BarFunction
}
}
// Iteration tests
// Prototypal
var i = 1000,
objs = [];
while (i--) {
var o = new Klass1()
objs.push(new Klass1());
o.bar;
o.foo;
}
// Module pattern
var i = 1000,
objs = [];
while (i--) {
var o = Klass2()
objs.push(Klass2());
o.bar;
o.foo;
}
// Module pattern with cached functions
var i = 1000,
objs = [];
while (i--) {
var o = Klass3()
objs.push(Klass3());
o.bar;
o.foo;
}
// See the test for full details
使用数组时的技巧
接下来说说数组相关的技巧。在一般情况下,不要删除数组元素,这样将使数组过渡到较慢的内部表示。当索引变得稀疏,V8将会使元素转为更慢的字典模式。
数组字面量
数组字面量非常有用,它可以暗示VM数组的大小和类型。它通常用在体积不大的数组中。
// Here V8 can see that you want a 4-element array containing numbers:
var a = [1, 2, 3, 4];
// Don't do this:
a = []; // Here V8 knows nothing about the array
for(var i = 1; i <= 4; i++) {
a.push(i);
}
存储单一类型VS多类型
将混合类型(比如数字、字符串、undefined、true/false)的数据存在数组中绝不是一个好想法。例如var arr = [1, “1”, undefined, true, “true”]
正如我们所看到的结果,整数的数组是最快的。
稀疏数组与满数组
当你使用稀疏数组时,要注意访问元素将远远慢于满数组。因为V8不会分配一整块空间给只用到部分空间的数组。取而代之的是,它被管理在字典中,既节约了空间,但花费访问的时间。
预分配空间VS动态分配
不要预分配大数组(如大于64K的元素),其最大的大小,而应该动态分配。在我们这篇文章的性能测试之前,请记住这只适用部分JavaScript引擎。
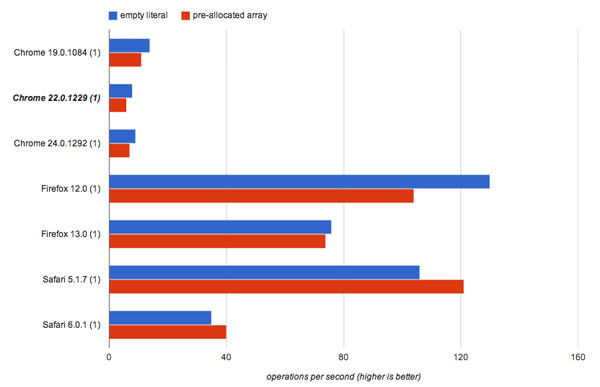
空字面量与预分配数组在不同的浏览器进行测试
Nitro (Safari)对预分配的数组更有利。而在其他引擎(V8,SpiderMonkey)中,预先分配并不是高效的。
// Empty array
var arr = [];
for (var i = 0; i < 1000000; i++) {
arr[i] = i;
}
// Pre-allocated array
var arr = new Array(1000000);
for (var i = 0; i < 1000000; i++) {
arr[i] = i;
}
优化你的应用
在Web应用的世界中,速度就是一切。没有用户希望用一个要花几秒钟计算某列总数或花几分钟汇总信息的表格应用。这是为什么你要在代码中压榨每一点性能的重要原因。

图片来源: Per Olof Forsberg.
理解和提高应用程序的性能是非常有用的同时,它也是困难的。我们推荐以下的步骤来解决性能的痛点:
- 测量:在您的应用程序中找到慢的地方(约45%)
- 理解:找出实际的问题是什么(约45%)
- 修复它! (约10%)
下面推荐的一些工具和技术可以协助你。
基准化(BENCHMARKING)
有很多方式来运行JavaScript代码片段的基准测试其性能——一般的假设是,基准简单地比较两个时间戳。这中模式被jsPerf团队指出,并在SunSpider和Kraken的基准套件中使用:
var totalTime,
start = new Date,
iterations = 1000;
while (iterations--) {
// Code snippet goes here
}
// totalTime → the number of milliseconds taken
// to execute the code snippet 1000 times
totalTime = new Date - start;
在这里,要测试的代码被放置在一个循环中,并运行一个设定的次数(例如6次)。在此之后,开始日期减去结束日期,就得出在循环中执行操作所花费的时间。
然而,这种基准测试做的事情过于简单了,特别是如果你想运行在多个浏览器和环境的基准。垃圾收集器本身对结果是有一定影响的。即使你使用window.performance这样的解决方案,也必须考虑到这些缺陷。
不管你是否只运行基准部分的代码,编写一个测试套件或编码基准库,JavaScript基准其实比你想象的更多。如需更详细的指南基准,我强烈建议你阅读由Mathias Bynens和John-David Dalton提供的Javascript基准测试。
分析(PROFILING)
Chrome开发者工具为JavaScript分析有很好的支持。可以使用此功能检测哪些函数占用了大部分时间,这样你就可以去优化它们。这很重要,即使是代码很小的改变会对整体表现产生重要的影响。
Chrome开发者工具的分析面板
分析过程开始获取代码性能基线,然后以时间线的形式体现。这将告诉我们代码需要多长时间运行。“Profiles”选项卡给了我们一个更好的视角来了解应用程序中发生了什么。JavaScript CPU分析文件展示了多少CPU时间被用于我们的代码,CSS选择器分析文件展示了多少时间花费在处理选择器上,堆快照显示多少内存正被用于我们的对象。
利用这些工具,我们可以分离、调整和重新分析来衡量我们的功能或操作性能优化是否真的起到了效果。
“Profile”选项卡展示了代码性能信息。
一个很好的分析介绍,阅读Zack Grossbart的 JavaScript Profiling With The Chrome Developer Tools。
提示:在理想情况下,若想确保你的分析并未受到已安装的应用程序或扩展的任何影响,可以使用--user-data-dir <empty_directory>标志来启动Chrome。在大多数情况下,这种方法优化测试应该是足够的,但也需要你更多的时间。这是V8标志能有所帮助的。
避免内存泄漏——3快照技术
在谷歌内部,Chrome开发者工具被Gmail等团队大量使用,用来帮助发现和排除内存泄漏。
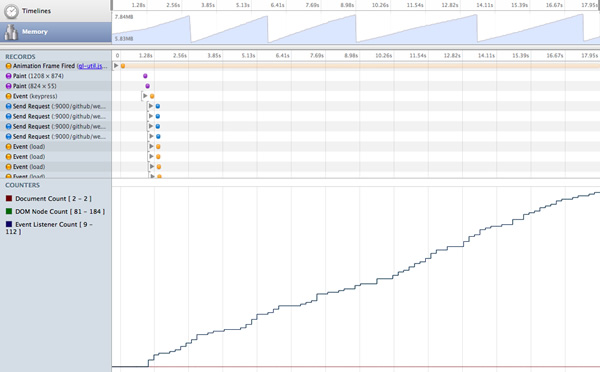
Chrome开发者工具中的内存统计
内存统计出我们团队所关心的私有内存使用、JavaScript堆的大小、DOM节点数量、存储清理、事件监听计数器和垃圾收集器正要回收的东西。推荐阅读Loreena Lee的“3快照”技术。该技术的要点是,在你的应用程序中记录一些行为,强制垃圾回收,检查DOM节点的数量有没有恢复到预期的基线,然后分析三个堆的快照来确定是否有内存泄漏。
单页面应用的内存管理
单页面应用程序(例如AngularJS,Backbone,Ember)的内存管理是非常重要的,它们几乎永远不会刷新页面。这意味着内存泄漏可能相当明显。移动终端上的单页面应用充满了陷阱,因为设备的内存有限,并在长期运行Email客户端或社交网络等应用程序。能力愈大责任愈重。
有很多办法解决这个问题。在Backbone中,确保使用dispose()来处理旧视图和引用(目前在Backbone(Edge)中可用)。这个函数是最近加上的,移除添加到视图“event”对象中的处理函数,以及通过传给view的第三个参数(回调上下文)的model或collection的事件监听器。dispose()也会被视图的remove()调用,处理当元素被移除时的主要清理工作。Ember 等其他的库当检测到元素被移除时,会清理监听器以避免内存泄漏。
Derick Bailey的一些明智的建议:
与其了解事件与引用是如何工作的,不如遵循的标准规则来管理JavaScript中的内存。如果你想加载数据到的一个存满用户对象的Backbone集合中,你要清空这个集合使它不再占用内存,那必须这个集合的所有引用以及集合内对象的引用。一旦清楚了所用的引用,资源就会被回收。这就是标准的JavaScript垃圾回收规则。
在文章中,Derick涵盖了许多使用Backbone.js时的常见内存缺陷,以及如何解决这些问题。
Felix Geisendörfer的在Node中调试内存泄漏的教程也值得一读,尤其是当它形成了更广泛SPA堆栈的一部分。
减少回流(REFLOWS)
当浏览器重新渲染文档中的元素时需要 重新计算它们的位置和几何形状,我们称之为回流。回流会阻塞用户在浏览器中的操作,因此理解提升回流时间是非常有帮助的。
回流时间图表
你应该批量地触发回流或重绘,但是要节制地使用这些方法。尽量不处理DOM也很重要。可以使用DocumentFragment,一个轻量级的文档对象。你可以把它作为一种方法来提取文档树的一部分,或创建一个新的文档“片段”。与其不断地添加DOM节点,不如使用文档片段后只执行一次DOM插入操作,以避免过多的回流。
例如,我们写一个函数给一个元素添加20个div。如果只是简单地每次append一个div到元素中,这会触发20次回流。
function addDivs(element) {
var div;
for (var i = 0; i < 20; i ++) {
div = document.createElement('div');
div.innerHTML = 'Heya!';
element.appendChild(div);
}
}
要解决这个问题,可以使用DocumentFragment来代替,我们可以每次添加一个新的div到里面。完成后将DocumentFragment添加到DOM中只会触发一次回流。
function addDivs(element) {
var div;
// Creates a new empty DocumentFragment.
var fragment = document.createDocumentFragment();
for (var i = 0; i < 20; i ++) {
div = document.createElement('a');
div.innerHTML = 'Heya!';
fragment.appendChild(div);
}
element.appendChild(fragment);
}
可以参阅 Make the Web Faster,JavaScript Memory Optimization 和 Finding Memory Leaks。
JS内存泄漏探测器
为了帮助发现JavaScript内存泄漏,谷歌的开发人员((Marja Hölttä和Jochen Eisinger)开发了一种工具,它与Chrome开发人员工具结合使用,检索堆的快照并检测出是什么对象导致了内存泄漏。
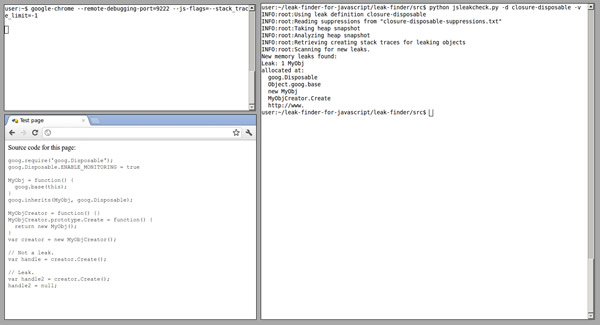
一个JavaScript内存泄漏检测工具
有完整的文章介绍了如何使用这个工具,建议你自己到内存泄漏探测器项目页面看看。
如果你想知道为什么这样的工具还没集成到我们的开发工具,其原因有二。它最初是在Closure库中帮助我们捕捉一些特定的内存场景,它更适合作为一个外部工具。
V8优化调试和垃圾回收的标志位
Chrome支持直接通过传递一些标志给V8,以获得更详细的引擎优化输出结果。例如,这样可以追踪V8的优化:
"/Applications/Google Chrome/Google Chrome" --js-flags="--trace-opt --trace-deopt"
Windows用户可以这样运行 chrome.exe –js-flags=”–trace-opt –trace-deopt”
在开发应用程序时,下面的V8标志都可以使用。
- trace-opt —— 记录优化函数的名称,并显示跳过的代码,因为优化器不知道如何优化。
- trace-deopt —— 记录运行时将要“去优化”的代码。
- trace-gc —— 记录每次的垃圾回收。
V8的处理脚本用*(星号)标识优化过的函数,用~(波浪号)表示未优化的函数。
如果你有兴趣了解更多关于V8的标志和V8的内部是如何工作的,强烈建议 阅读Vyacheslav Egorov的excellent post on V8 internals。
HIGH-RESOLUTION TIME 和 NAVIGATION TIMING API
高精度时间(HRT)是一个提供不受系统时间和用户调整影响的亚毫秒级高精度时间接口,可以把它当做是比 new Date 和 Date.now()更精准的度量方法。这对我们编写基准测试帮助很大。
高精度时间(HRT)提供了当前亚毫秒级的时间精度
目前HRT在Chrome(稳定版)中是以window.performance.webkitNow()方式使用,但在Chrome Canary中前缀被丢弃了,这使得它可以通过window.performance.now()方式调用。Paul Irish在HTML5Rocks上了关于HRT更多内容的文章。
现在我们知道当前的精准时间,那有可以准确测量页面性能的API吗?好吧,现在有个Navigation Timing API可以使用,这个API提供了一种简单的方式,来获取网页在加载呈现给用户时,精确和详细的时间测量记录。可以在console中使用window.performance.timing来获取时间信息:
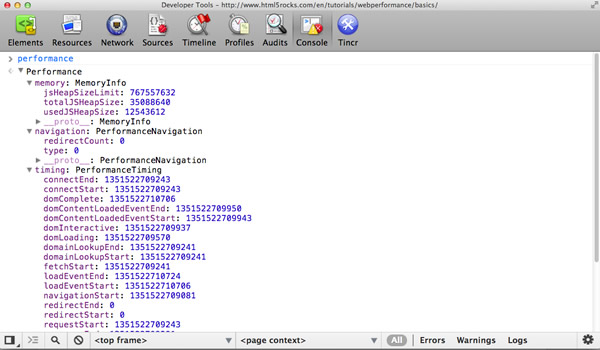
显示在控制台中的时间信息
我们可以从上面的数据获取很多有用的信息,例如网络延时为responseEnd – fetchStart,页面加载时间为loadEventEnd – responseEnd,处理导航和页面加载的时间为loadEventEnd – navigationStart。
正如你所看到的,perfomance.memory的属性也能显示JavaScript的内存数据使用情况,如总的堆大小。
更多Navigation Timing API的细节,阅读 Sam Dutton的 Measuring Page Load Speed With Navigation Timing。
ABOUT:MEMORY 和 ABOUT:TRACING
Chrome中的about:tracing提供了浏览器的性能视图,记录了Chrome的所有线程、tab页和进程。
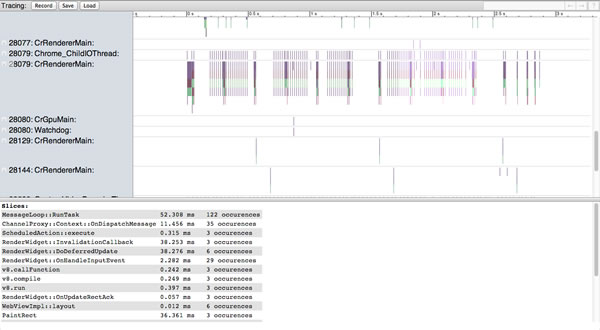
About:Tracing提供了浏览器的性能视图
这个工具的真正用处是允许你捕获Chrome的运行数据,这样你就可以适当地调整JavaScript执行,或优化资源加载。
Lilli Thompson有一篇写给游戏开发者的使用about:tracing分析WebGL游戏的文章,同时也适合JavaScript的开发者。
在Chrome的导航栏里可以输入about:memory,同样十分实用,可以获得每个tab页的内存使用情况,对定位内存泄漏很有帮助。
总结
我们看到,JavaScript的世界中有很多隐藏的陷阱,且并没有提升性能的银弹。只有把一些优化方案综合使用到(现实世界)测试环境,才能获得最大的性能收益。即便如此,了解引擎是如何解释和优化代码,可以帮助你调整应用程序。
测量,理解,修复。不断重复这个过程。

图片来源: Sally Hunter
谨记关注优化,但为了便利可以舍弃一些很小的优化。例如,有些开发者选择.forEach和Object.keys代替for和for..in循环,尽管这会更慢但使用更方便。要保证清醒的头脑,知道什么优化是需要的,什么优化是不需要的。
同时注意,虽然JavaScript引擎越来越快,但下一个真正的瓶颈是DOM。回流和重绘的减少也是重要的,所以必要时再去动DOM。还有就是要关注网络,HTTP请求是珍贵的,特别是移动终端上,因此要使用HTTP的缓存去减少资源的加载。
记住这几点可以保证你获取了本文的大部分信息,希望对你有所帮助!
原文:http://coding.smashingmagazine.com/2012/11/05/writing-fast-memory-efficient-javascript/
作者:Addy Osmani
相关推荐
-
编写高性能的JavaScript 脚本的加载与执行
脚本可以放在html页面的head里面,也可以放在body里面. 把脚本放在body中,当浏览器遇见<script>标签时, 浏览器不知道脚本会插入文本还是html标签,因此浏览器会停止分析html页面而去执行脚本.当使用src的方式添加脚本时,浏览器也会做同样的动作.在脚本处理的时候,页面呈现和用户交互将被完全阻止.脚本下载和执行阻塞了其他资源的下载,比如呈现页面使用的图片.(虽然很多浏览器实现了脚本并行下载的技术,但是这个问题依然没有解决) 脚本的位置 鉴于上面的理由,脚本应该始终放在页面
-
javascript for循环设法提高性能
一般在javascript里对数组进行遍历一般是使用for循环,像下面一样 复制代码 代码如下: var arr = []; for(var i=0; i<arr.length; i++){ //loop } 这种代码最大的问题,就在于每次循环时都要通过 .操作符获取 .length,增加了开销.那么我们可以这样改进. 复制代码 代码如下: var arr = []; for(var i=0, n=arr.length; i<n; i++){ //loop } 这样子,先把 arr.lengt
-
High Performance JavaScript(高性能JavaScript)读书笔记分析
第一章:加载和执行 浏览器的JavaScript的引擎是编译器层的优化: 当浏览器执行JavaScript代码时,不能同时做其他任何事情(单一进程),意味着<script>标签每次出现都霸道地让页面等带脚本的解析和执行(每个文件必须等到前一个文件下载并执行完成才会开始下载),所以头部的JS和CSS用来渲染页面,交互行为(几乎所有)的JS放在<body>底部: 主流浏览器都允许并行下载JS. 减少外链脚本数量将会改善性能(合并JS) 任何网站都可以使用一个把制定文件合并处理后的URL
-
编写高性能Javascript代码的N条建议
多年来,Javascript一直在web应用开发中占据重要的地位,但是很多开发者往往忽视一些性能方面的知识,特别是随着计算机硬件的不断升级,开发者越发觉得Javascript性能优化的好不好对网页的执行效率影响不明显.但在某些情况下,不优化的Javascript代码必然会影响用户的体验.因此,即使在当前硬件性能已经大大提升的时代,在编写Javascript代码时,若能遵循Javascript规范和注意一些性能方面的知识,对于提升代码的可维护性和优化性能将大有好处. 下面给出编写高性能的Javas
-

高性能Javascript笔记 数据的存储与访问性能优化
局部变量也就可以理解为在函数内部定义的变量,很明显访问局部变量要比域外的变量要快,因为它位于作用域链的第一个变量对象中(关于作用域链的介绍可以阅读这篇文章).变量在作用域链的位置越深,访问所需要的时间就越长,全局变量总是最慢的,因为它们位于作用域链的最后一个变量对象. 每种数据类型的访问都需要付出点性能代价,对于直接量和局部变量基本都能消费得起,而访问数组项和对象成员则要代价高点.下图显示了不同浏览器,分别对这四种数据类型进行了200'000次操作所用的时间. 由上图可以看出,要想优化代码的性能
-
javascript下高性能字符串连接StringBuffer类
复制代码 代码如下: function StringBuffer(){ this.__strings__ = new Array(); } StringBuffer.prototype.append = function(str){ this.__strings__.push(str); }; StringBuffer.prototype.toString = function(){ this.__strings__.join(" "); }; 其实上面的代码,主要利用了js的数组原理
-
高性能JavaScript DOM编程(1)
我们知道,DOM是用于操作XML和HTML文档的应用程序接口,用脚本进行DOM操作的代价很昂贵.有个贴切的比喻,把DOM和JavaScript(这里指ECMScript)各自想象为一个岛屿,它们之间用收费桥梁连接,ECMAScript每次访问DOM,都要途径这座桥,并交纳"过桥费",访问DOM的次数越多,费用也就越高.因此,推荐的做法是尽量减少过桥的次数,努力待在ECMAScript岛上.我们不可能不用DOM的接口,那么,怎样才能提高程序的效率? 1.DOM访问与修改 访问DOM元素是
-
编写高性能JavaScript(译)
译者按:本人第一次翻译外文,言语难免有些晦涩,但尽量表达了作者的原意,未经过多的润色,欢迎批评指正.另本文篇幅较长.信息量大,可能难以消化,欢迎留言探讨细节问题.本文主要关注V8的性能优化,部分内容并不适用于所有JS引擎.最后,转载请注明出处: ) ========================译文分割线=========================== 很多JavaScript引擎,如Google的V8引擎(被Chrome和Node所用),是专门为需要快速执行的大型JavaScript应
-
在 C# 中使用 Span<T> 和 Memory<T> 编写高性能代码的详细步骤
目录 .NET 中支持的内存类型 .NET Core 2.1 中新增的类型 访问连续内存: Span 和 Memory Span 介绍 C# 中的 Span Span 和 Arrays Span 和 ReadOnlySpan Memory 入门 ReadOnlyMemory Span 和 Memory 的优势 连续和非连续内存缓冲区 不连续的缓冲区: ReadOnly 序列 实际场景 Benchmarking 基准测试 安装 NuGet 包 Benchmarking Span 执行基准测试 解读
-
高性能JavaScript模板引擎实现原理详解
随着 web 发展,前端应用变得越来越复杂,基于后端的 javascript(Node.js) 也开始崭露头角,此时 javascript 被寄予了更大的期望,与此同时 javascript MVC 思想也开始流行起来.javascript 模板引擎作为数据与界面分离工作中最重要一环,越来越受开发者关注,近一年来在开源社区中更是百花齐放,在 Twitter.淘宝网.新浪微博.腾讯QQ空间.腾讯微博等大型网站中均能看到它们的身影. 本文将用最简单的示例代码描述现有的 javascript 模板引擎
-
高性能JavaScript 重排与重绘(2)
先回顾下前一篇文章高性能JavaScript DOM编程,主要提了两点优化,一是尽量减少DOM的访问,而把运算放在ECMAScript这一端,二是尽量缓存局部变量,比如length等等,最后介绍了两个新的API querySelector()以及querySelectorAll(),在做组合选择的时候可以大胆使用.而本文主要讲的是DOM编程可能最耗时的地方,重排和重绘. 1.什么是重排和重绘 浏览器下载完页面中的所有组件--HTML标记.JavaScript.CSS.图片之后会解析生成两个内部数
-
你不知道的高性能JAVASCRIPT
本文会分享一些高效的JavaScript的最佳实践,提高大家对JS的底层和实现原理的理解. 数据存储 计算机学科中有一个经典问题是通过改变数据存储的位置来获得最佳的读写性能,在JavaScript中,数据存储的位置会对代码性能产生重大影响. – 能使用{}创建对象就不要使用new Object,能使用[]创建数组就不要使用new Array.JS中字面量的访问速度要高于对象. – 变量在作用域链中的位置越深,访问所需实践越长.对于这种变量,可以通过缓存使用局部变量保存起来,减少对作用域链访问次数
-
编写高性能Lua代码的方法
前言 Lua是一门以其性能著称的脚本语言,被广泛应用在很多方面,尤其是游戏.像<魔兽世界>的插件,手机游戏<大掌门><神曲><迷失之地>等都是用Lua来写的逻辑. 所以大部分时候我们不需要去考虑性能问题.Knuth有句名言:"过早优化是万恶之源".其意思就是过早优化是不必要的,会浪费大量时间,而且容易导致代码混乱. 所以一个好的程序员在考虑优化性能前必须问自己两个问题:"我的程序真的需要优化吗?".如果答案为是,那么再
-
编写一个javascript元循环求值器的方法
在上一篇文章中,我们通过AST完成了微信小程序组件的多端编译,在这篇文章中,让我们更深入一点,通过AST完成一个javascript元循环求值器 结构 一个元循环求值器,完整的应该包含以下内容: tokenizer:对代码文本进行词法和语法分析,将代码分割成若干个token parser:根据token,生成AST树 evaluate:根据AST树节点的type,执行对应的apply方法 apply:根据环境,执行实际的求值计算 scope:当前代码执行的环境 代码目录 根据结构看,我将代码目录