Python制作爬虫抓取美女图
作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞个爬虫把美图都给扒下来!本次实例有2个:煎蛋上的妹子图,某网站的rosi图。我只是一个学习python的菜鸟,技术不可耻,技术是无罪的!!!
煎蛋:
先说说程序的流程:获取煎蛋妹子图URL,得到网页代码,提取妹子图片地址,访问图片地址并将图片保存到本地。Ready? 先让我们看看煎蛋妹子网页:
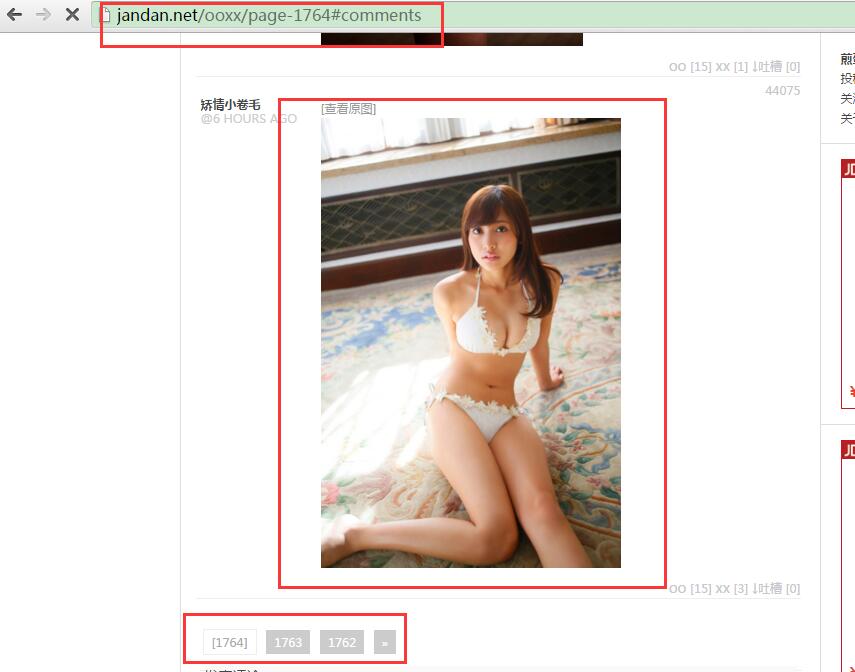
我们得到URL为:http://jandan.net/ooxx/page-1764#comments 1764就是页码, 首先我们要得到最新的页码,然后向前寻找,然后得到每页中图片的url。下面我们分析网站代码写出正则表达式!

根据之前文章的方法我们写出如下函数getNewPage:
def __getNewPage(self):
pageCode = self.Get(self.__Url)
type = sys.getfilesystemencoding()
pattern = re.compile(r'<div .*?cp-pagenavi">.*?<span .*?current-comment-page">\[(.*?)\]</span>',re.S)
newPage = re.search(pattern,pageCode.decode("UTF-8").encode(type))
print pageCode.decode("UTF-8").encode(type)
if newPage != None:
return newPage.group(1)
return 1500
不要问我为什么如果失败返回1500。。。 因为煎蛋把1500页之前的图片都给吃了。 你也可以返回0。接下来是图片的
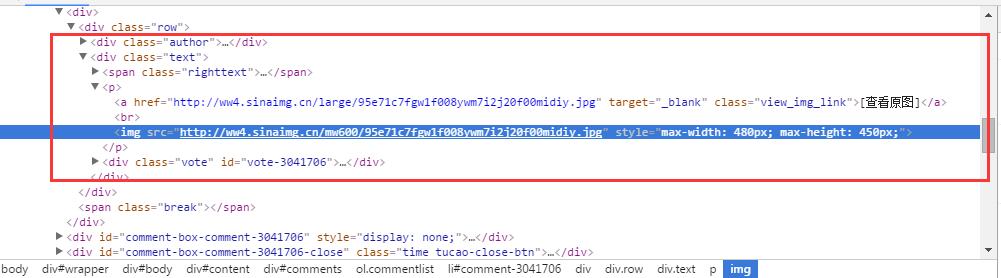
def __getAllPicUrl(self,pageIndex):
realurl = self.__Url + "page-" + str(pageIndex) + "#comments"
pageCode = self.Get(realurl)
type = sys.getfilesystemencoding()
pattern = re.compile('<p>.*?<a .*?view_img_link">.*?</a>.*?<img src="(.*?)".*?</p>',re.S)
items = re.findall(pattern,pageCode.decode("UTF-8").encode(type))
for item in items:
print item
好了,得到了图片地址,接下来就是访问图片地址然后保存图片了:
def __savePics(self,img_addr,folder):
for item in img_addr:
filename = item.split('/')[-1]
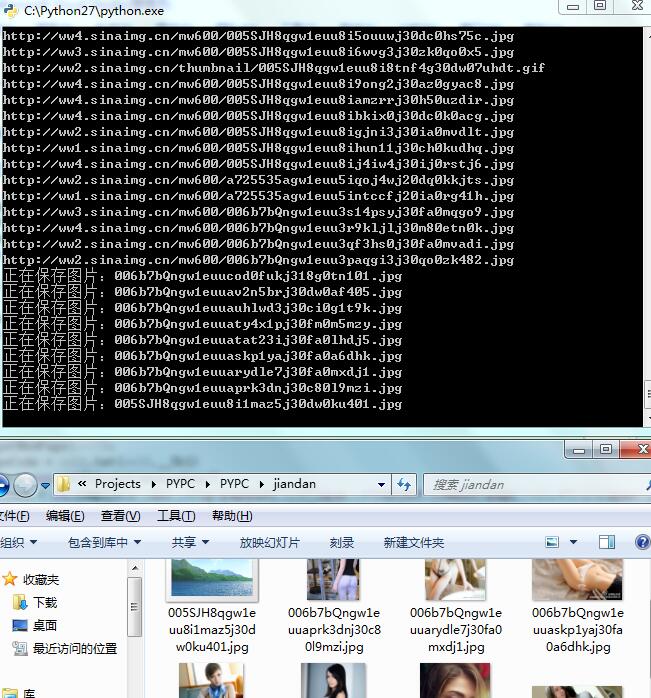
print "正在保存图片:" + filename
with open(filename,'wb') as file:
img = self.Get(item)
file.write(img)
当你觉得信心满满的时候,一定会有一盆冷水浇到你的头上,毕竟程序就是这样,考验你的耐性,打磨你的自信。你测试了一会儿,然后你发现你重启程序后再也无法获取最新页码,你觉得我什么也没动啊为什么会这样。别着急,我们将得到的网页代码打印出来看看:
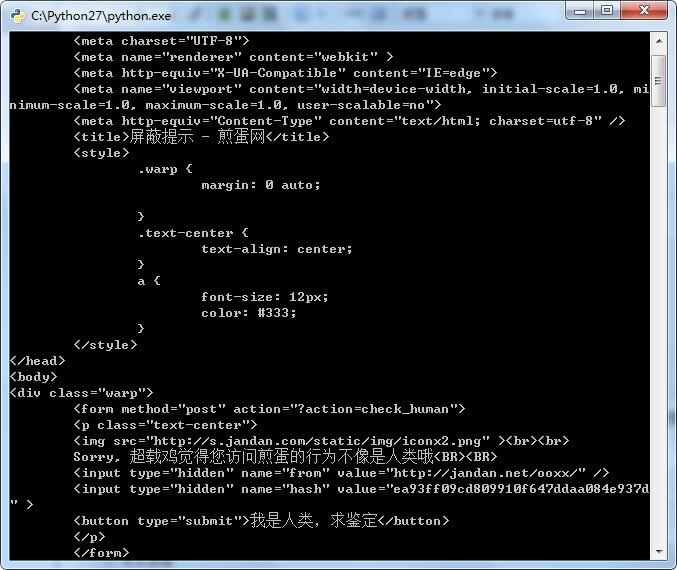
看到了吧,是服务器感觉你不像浏览器访问的结果把你的ip给屏蔽了。 真是给跪了,辛辛苦苦码一年,屏蔽回到解放前!那么这个如何解决呢,答:换ip 找代理。接下来我们要改一下我们的HttpClient.py 将里面的opener设置下代理服务器。具体代理服务器请自行百度之,关键字:http代理 。 想找到一个合适的代理也不容易 自己ie Internet选项挨个试试,测试下网速。
# -*- coding: utf-8 -*-
import cookielib, urllib, urllib2, socket
import zlib,StringIO
class HttpClient:
__cookie = cookielib.CookieJar()
__proxy_handler = urllib2.ProxyHandler({"http" : '42.121.6.80:8080'})#设置代理服务器与端口
__req = urllib2.build_opener(urllib2.HTTPCookieProcessor(__cookie),__proxy_handler)#生成opener
__req.addheaders = [
('Accept', 'application/javascript, */*;q=0.8'),
('User-Agent', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)')
]
urllib2.install_opener(__req)
def Get(self, url, refer=None):
try:
req = urllib2.Request(url)
#req.add_header('Accept-encoding', 'gzip')
if not (refer is None):
req.add_header('Referer', refer)
response = urllib2.urlopen(req, timeout=120)
html = response.read()
#gzipped = response.headers.get('Content-Encoding')
#if gzipped:
# html = zlib.decompress(html, 16+zlib.MAX_WBITS)
return html
except urllib2.HTTPError, e:
return e.read()
except socket.timeout, e:
return ''
except socket.error, e:
return ''
然后,就可以非常愉快的查看图片了。不过用了代理速度好慢。。。可以设置timeout稍微长一点儿,防止图片下载不下来!
好了,rosi的下篇文章再放!现在是时候上一波代码了:
# -*- coding: utf-8 -*-
import cookielib, urllib, urllib2, socket
import zlib,StringIO
class HttpClient:
__cookie = cookielib.CookieJar()
__proxy_handler = urllib2.ProxyHandler({"http" : '42.121.6.80:8080'})
__req = urllib2.build_opener(urllib2.HTTPCookieProcessor(__cookie),__proxy_handler)
__req.addheaders = [
('Accept', 'application/javascript, */*;q=0.8'),
('User-Agent', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)')
]
urllib2.install_opener(__req)
def Get(self, url, refer=None):
try:
req = urllib2.Request(url)
req.add_header('Accept-encoding', 'gzip')
if not (refer is None):
req.add_header('Referer', refer)
response = urllib2.urlopen(req, timeout=120)
html = response.read()
gzipped = response.headers.get('Content-Encoding')
if gzipped:
html = zlib.decompress(html, 16+zlib.MAX_WBITS)
return html
except urllib2.HTTPError, e:
return e.read()
except socket.timeout, e:
return ''
except socket.error, e:
return ''
def Post(self, url, data, refer=None):
try:
#req = urllib2.Request(url, urllib.urlencode(data))
req = urllib2.Request(url,data)
if not (refer is None):
req.add_header('Referer', refer)
return urllib2.urlopen(req, timeout=120).read()
except urllib2.HTTPError, e:
return e.read()
except socket.timeout, e:
return ''
except socket.error, e:
return ''
def Download(self, url, file):
output = open(file, 'wb')
output.write(urllib2.urlopen(url).read())
output.close()
# def urlencode(self, data):
# return urllib.quote(data)
def getCookie(self, key):
for c in self.__cookie:
if c.name == key:
return c.value
return ''
def setCookie(self, key, val, domain):
ck = cookielib.Cookie(version=0, name=key, value=val, port=None, port_specified=False, domain=domain, domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={'HttpOnly': None}, rfc2109=False)
self.__cookie.set_cookie(ck)
#self.__cookie.clear() clean cookie
# vim : tabstop=2 shiftwidth=2 softtabstop=2 expandtab
HttpClient
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
from HttpClient import HttpClient
import sys,re,os
class JianDan(HttpClient):
def __init__(self):
self.__pageIndex = 1500 #之前的图片被煎蛋吞了
self.__Url = "http://jandan.net/ooxx/"
self.__floder = "jiandan"
def __getAllPicUrl(self,pageIndex):
realurl = self.__Url + "page-" + str(pageIndex) + "#comments"
pageCode = self.Get(realurl)
type = sys.getfilesystemencoding()
pattern = re.compile('<p>.*?<a .*?view_img_link">.*?</a>.*?<img src="(.*?)".*?</p>',re.S)
items = re.findall(pattern,pageCode.decode("UTF-8").encode(type))
for item in items:
print item
self.__savePics(items,self.__floder)
def __savePics(self,img_addr,folder):
for item in img_addr:
filename = item.split('/')[-1]
print "正在保存图片:" + filename
with open(filename,'wb') as file:
img = self.Get(item)
file.write(img)
def __getNewPage(self):
pageCode = self.Get(self.__Url)
type = sys.getfilesystemencoding()
pattern = re.compile(r'<div .*?cp-pagenavi">.*?<span .*?current-comment-page">\[(.*?)\]</span>',re.S)
newPage = re.search(pattern,pageCode.decode("UTF-8").encode(type))
print pageCode.decode("UTF-8").encode(type)
if newPage != None:
return newPage.group(1)
return 1500
def start(self):
isExists=os.path.exists(self.__floder)#检测是否存在目录
print isExists
if not isExists:
os.mkdir(self.__floder)
os.chdir(self.__floder)
page = int(self.__getNewPage())
for i in range(self.__pageIndex,page):
self.__getAllPicUrl(i)
if __name__ == '__main__':
jd = JianDan()
jd.start()
JianDan
相关推荐
-
零基础写python爬虫之抓取百度贴吧代码分享
这里就不给大家废话了,直接上代码,代码的解释都在注释里面,看不懂的也别来问我,好好学学基础知识去! 复制代码 代码如下: # -*- coding: utf-8 -*- #--------------------------------------- # 程序:百度贴吧爬虫 # 版本:0.1 # 作者:why # 日期:2013-05-14 # 语言:Python 2.7 # 操作:输入带分页的地址,去掉最后面的数字,设置一下起始页数和终点页数. # 功能:下载对应页
-

使用Python编写简单网络爬虫抓取视频下载资源
我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎,所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了! 回到用Python写爬虫的话题. Python一直是我主要使用的脚本语言,没有之一.Python的语言简洁灵活,标准库功能强大,平常可以用作计算器,文本编码转换,图片处理,批量下载,批量处理文本等.总之我很喜欢,也越用越上手,这么好用的一个工具,一般人我不告诉他... 因为其强大的字符串处理能力,以及urllib2,cookielib,re,threading这些
-
零基础写python爬虫之使用urllib2组件抓取网页内容
版本号:Python2.7.5,Python3改动较大,各位另寻教程. 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地. 类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的内容发送到服务器端, 然后读取服务器端的响应资源. 在Python中,我们使用urllib2这个组件来抓取网页. urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件. 它以urlopen函数的形式提供了一个非常简单的接口. 最简
-
Python3.4编程实现简单抓取爬虫功能示例
本文实例讲述了Python3.4编程实现简单抓取爬虫功能.分享给大家供大家参考,具体如下: import urllib.request import urllib.parse import re import urllib.request,urllib.parse,http.cookiejar import time def getHtml(url): cj=http.cookiejar.CookieJar() opener=urllib.request.build_opener(urllib.
-
Python爬虫实现网页信息抓取功能示例【URL与正则模块】
本文实例讲述了Python爬虫实现网页信息抓取功能.分享给大家供大家参考,具体如下: 首先实现关于网页解析.读取等操作我们要用到以下几个模块 import urllib import urllib2 import re 我们可以尝试一下用readline方法读某个网站,比如说百度 def test(): f=urllib.urlopen('http://www.baidu.com') while True: firstLine=f.readline() print firstLine 下面我们说
-
Python实现抓取页面上链接的简单爬虫分享
除了C/C++以外,我也接触过不少流行的语言,PHP.java.javascript.python,其中python可以说是操作起来最方便,缺点最少的语言了. 前几天想写爬虫,后来跟朋友商量了一下,决定过几天再一起写.爬虫里重要的一部分是抓取页面中的链接,我在这里简单的实现一下. 首先我们需要用到一个开源的模块,requests.这不是python自带的模块,需要从网上下载.解压与安装: 复制代码 代码如下: $ curl -OL https://github.com/kennethreitz/
-
编写Python爬虫抓取暴走漫画上gif图片的实例分享
本文要介绍的爬虫是抓取暴走漫画上的GIF趣图,方便离线观看.爬虫用的是python3.3开发的,主要用到了urllib.request和BeautifulSoup模块. urllib模块提供了从万维网中获取数据的高层接口,当我们用urlopen()打开一个URL时,就相当于我们用Python内建的open()打开一个文件.但不同的是,前者接收一个URL作为参数,并且没有办法对打开的文件流进行seek操作(从底层的角度看,因为实际上操作的是socket,所以理所当然地没办法进行seek操作),而后
-
零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件. 项目内容: 用Python写的百度贴吧的网络爬虫. 使用方法: 新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行. 程序功能: 将贴吧中楼主发布的内容打包txt存储到本地. 原理解释: 首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了: http://tieba.baidu.com/p/2296712428?see_lz=1&pn=
-
零基础写python爬虫之抓取糗事百科代码分享
项目内容: 用Python写的糗事百科的网络爬虫. 使用方法: 新建一个Bug.py文件,然后将代码复制到里面后,双击运行. 程序功能: 在命令提示行中浏览糗事百科. 原理解释: 首先,先浏览一下糗事百科的主页:http://www.qiushibaike.com/hot/page/1 可以看出来,链接中page/后面的数字就是对应的页码,记住这一点为以后的编写做准备. 然后,右击查看页面源码: 观察发现,每一个段子都用div标记,其中class必为content,title是发帖时间,我们只需
-
Python爬虫抓取手机APP的传输数据
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 方法详细可以参考这篇博文:Fiddler如何抓取手机APP数据包 得到超级课程表登录的地址:http://120.55.151.61/V2/StudentSkip/loginCheckV4.action 表单: 表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是. 另外必须加header,一开始我没有加header得
-
实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
安装部署Scrapy 在安装Scrapy前首先需要确定的是已经安装好了Python(目前Scrapy支持Python2.5,Python2.6和Python2.7).官方文档中介绍了三种方法进行安装,我采用的是使用 easy_install 进行安装,首先是下载Windows版本的setuptools(下载地址:http://pypi.python.org/pypi/setuptools),下载完后一路NEXT就可以了. 安装完setuptool以后.执行CMD,然后运行一下命令: easy_i
-
python制作爬虫并将抓取结果保存到excel中
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫. 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候,搜索Python,或者是PHP等等的岗位信息,其实是向服务器发出相应请求,由服务器动态的响应请求,将我们所需要的内容通过浏览器解析,呈现在我们的面前. 可以看到我们发出的请求当中,FormData中的kd参数,就代表着向服务器请求关键词为Python的招聘信息. 分析比较复杂的页面请求与响应信息,