货拉拉大数据对BitMap的探索实践详解
目录
- 关于Bitmap
- What
- BitMap的简单实现
- BitSet源码理解
- 备注信息
- 核心片段理解
- Why
- BitMap的特点
- BitMap的优化
- RoaringBitmap的核心原理
- how
- BitMap在用户分群的应用
- 传统解决方案
- 使用BitMap的方案
- BitMap在A/B实验平台业务的应用
- 结语
关于Bitmap
在大数据时代,想要不断提升基于海量数据获取的决策、洞察发现和流程优化等能力,就需要不停思考,如何在利用有限的资源实现高效稳定地产出可信且丰富的数据,从而提高赋能下游产品的效率以及效果。在货拉拉数仓构建过程中,我们不断探索各种方式来实现降本提效。例如在一些场景下,利用Bitmap去提升下游的数据使用体验,并达成我们想要的降本提效的目的。
为了更好的展示Bitmap在货拉拉实践应用中的探索与实践,我们分了两篇文章来介绍,本文主要介绍Bitmap的实现原理与应用优化,以及在一些常见业务场景中的实践应用,让大家在面对相应场景的时候,能够有一个区别于传统的解决方案的新思路。下一篇文章则是重点介绍Bitmap在货拉拉中的具体落地,以及使用时遇到的一些痛点和对应解决方案。
首先从Bitmap开始说起,这里采用经典的WWH结构,让不熟悉的小伙伴能够快速了解掌握。
What
BitMap,即位图,是比较常见的数据结构,简单来说就是按位存储,主要为了解决在去重场景里面大数据量存储的问题。本质其实就是哈希表的一种应用实现,使用每个位来表示某个数字。
举个例子
假设有个1,3,5,7的数字集合,如果常规的存储方法,要用4个Int的空间。其中一个Int就是32位的空间。3个就是4*32Bit,相当于16个字节。
如果用Bitmap存储呢,只用8Bit(1个字节)就够了。bitmap通过使用每一bit位代表一个数,位号就是数值,1标识有,0标识无。如下所示:

BitMap的简单实现
对于 BitMap 这种经典的数据结构,在 Java 语言里面,其实已经有对应实现的数据结构类 java.util.BitSet 了,而 BitSet 的底层原理,其实就是用 long 类型的数组来存储元素,因为使用的是long类型的数组,而 1 long = 64 bit,所以数据大小会是64的整数倍。这样看可能很难理解,下面参考bitmap源码写了一个例子,并写上了详细的备注,方便理解
import java.util.Arrays;
public class BitMap {
// 用 byte 数组存储数据
private byte[] bits;
// 指定 bitMap的长度
private int bitSize;
// bitmap构造器
public BitMap(int bitSize) {
this.bitSize = (bitSize >> 3) + 1;
//1byte 能存储8个数据,那么要存储 bitSize的长度需要多少个bit呢,bitSize/8+1,右移3位相当于除以8
bits = new byte[(bitSize >> 3) + 1];
}
// 在bitmap中插入数字
public void add(int num) {
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后和以前的数据做|,这样,那个位置就替换成1了。
bits[arrayIndex] |= 1 << position;
}
// 判断bitmap中是否包含某数字
public boolean contain(int num) {
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后和以前的数据做&,判断是否为0即可
return (bits[arrayIndex] & (1 << position)) != 0;
}
// 清除bitmap中的某个数字
public void clear(int num) {
// num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后对取反,再与当前值做&,即可清除当前的位置了.
bits[arrayIndex] &= ~(1 << position);
}
// 打印底层bit存储
public static void printBit(BitMap bitMap) {
int index=bitMap.bitSize & 0x07;
for (int j = 0; j < index; j++) {
System.out.print("byte["+j+"] 的底层存储:");
byte num = bitMap.bits[j];
for (int i = 7; i >= 0; i--) {
System.out.print((num & (1 << i)) == 0 ? "0" : "1");
}
System.out.println();
}
}
// 输出数组元素,也可以使用Arrays的toString方法
private static void printArray(int[] arr) {
System.out.print("数组元素:");
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]+" ");
}
System.out.println();
}
}
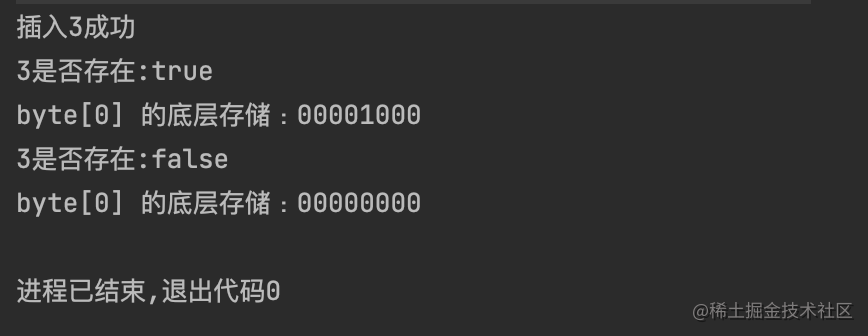
下面就来简单玩一玩这个自制的BitMap,先尝试插入一个3,并清理掉它,看看底层二进制结构是怎样变化的
public static void main(String[] args) {
// 简单试验
BitMap bitmap = new BitMap(3);
bitmap.add(3);
System.out.println("插入3成功");
boolean isexsit = bitmap.contain(3);
System.out.println("3是否存在:" + isexsit);
printBit(bitmap);
bitmap.clear(3);
isexsit = bitmap.contain(3);
System.out.println("3是否存在:" + isexsit);
printBit(bitmap);
}
输出结果如下:
再通过数组,插入多个元素看看效果
public static void main(String[] args) {
// 数组试验
int[] arr = {8,3,3,4,9};
printArray(arr);
int size = Arrays.stream(arr).max().getAsInt();
BitMap b = new BitMap(size);
for (int i = 0; i < arr.length; i++) {
b.add(arr[i]);
}
printBit(b);
}
输出结果如下:

BitSet源码理解
前面简单了解了一下BitMap,下面就通过源码来看看java是如何实现BitSet的。
备注信息
打开源码,首先映入眼帘的是下面这一段长长的备注,简单翻译一下,便于英语不好的小伙伴理解

源码备注翻译如下
- 这个类实现了一个根据需要增长的位向量。位集的每个组件都有一个布尔值。BitSet的位由非负整数索引。可以检查、设置或清除单个索引位。一个位集可用于通过逻辑AND、逻辑inclusive OR和逻辑exclusive OR操作修改另一个位集的内容。
- 默认情况下,集合中的所有位最初的值都为false。
- 每个BitSet都有一个当前大小,即BitSet当前使用的空间位数。请注意,大小与BitSet的实现有关,因此它可能会随着实现而改变。BitSet的长度与BitSet的逻辑长度有关,并且与实现无关。
- 除非另有说明,否则将null参数传递给位集中的任何方法都将导致NullPointerException。
- 如果没有外部同步,BitSet对于多线程使用是不安全的。
核心片段理解
首先可以看到源码中,最核心的属性信息。在BitSet 中使用的是long[] 作为底层存储的数据结构,并通过一个 int 类型的变量,来记录当前已经使用数组元素的个数。
这种类型的属性结构很常见,比如StringBuilder、StringBuffer底层是一个char[] 作为存储,一个int 变量用来计数,相似的还有ArrayList,Vector等
/** * The internal field corresponding to the serialField "bits". */ private long[] words; /** * The number of words in the logical size of this BitSet. */ private transient int wordsInUse = 0;
再往下看,是一个很重要的方法,是用来获取某个数在数组中的下标,采用的算法是将这个数右移6位,这是因为 bitIndex >> 6 = bitIndex / (2^6) = bitIndex /64,而long就是64个字节
private final static int ADDRESS_BITS_PER_WORD = 6;
/**
* Given a bit index, return word index containing it.
*/
private static int wordIndex(int bitIndex) {
return bitIndex >> ADDRESS_BITS_PER_WORD;
}
接着比较有意思的就是它的空参构造器,BITS_PER_WORD默认是1<<6 也就是64,根据上面方法原理,wordIndex(64-1)+1 = 1 ,所以最终初始化的是长度为1的数组
private final static int BITS_PER_WORD = 1 << ADDRESS_BITS_PER_WORD;
/**
* Creates a new bit set. All bits are initially { @code false}.
*/
public BitSet() {
initWords(BITS_PER_WORD);
sizeIsSticky = false;
}
private void initWords(int nbits) {
words = new long[wordIndex(nbits-1) + 1];
}
最后看到这个很经典也很重要的方法,由于底层是数组,在初始化的时候,并不知道将来会需要存储多大的数据,所以对于这一类底层核心实现结构是数组的实体类,通常会使用动态扩容的方法,具体实现细节也都大同小异,这里实现的动态扩容是原本的两倍,和Vector类似。
/**
* Ensures that the BitSet can hold enough words.
* @param wordsRequired the minimum acceptable number of words.
*/
private void ensureCapacity(int wordsRequired) {
// 如果数组的长度小于所需要的就要进行扩容
if (words.length < wordsRequired) {
// Allocate larger of doubled size or required size
// 扩容最终的大小,最小为原来的两倍
int request = Math.max(2 * words.length, wordsRequired);
// 创建新的数组,容量为request,然后将原本的数组拷贝到新的数组中
words = Arrays.copyOf(words, request);
// 并设置数组大小不固定
sizeIsSticky = false;
}
}
至于其他的源码细节,因为篇幅有限,就暂且不表,感兴趣的可以自行阅读~
Why
BitMap的特点
根据bitmap的实现原理,其实可以总结出使用bitmap的几个主要原因:
- 针对海量数据的存储,可以极大的节约存储成本!当需要存储一些很大,且无序,不重复的整数集合,那使用Bitmap的存储成本是非常低的。
- 因为其天然去重的属性,对于需要去重存储的数据很友好!因为bitmap每个值都只对应唯一的一个位置,不能存储两个值,所以Bitmap结构天然适合做去重操作。
- 同样因为其下标的存在,可以快速定位数据!比如想判断数字 99999是否存在于该bitmap中,若是使用传统的集合型存储,那就要逐个遍历每个元素进行判断,时间复杂度为O(N)。而由于采用Bitmap存储,只要查看对应的下标数的值是0还是1即可,时间复杂度为O(1)。所以使用bitmap可以非常方便快速的查询某个数据是否在bitmap中。
- 还有因为其类集合的特性,对于一些集合的交并集等操作也可以支持!比如想查询[1,2,3]与[3,4,5] 两个集合的交集,用传统方式取交集就要两层循环遍历。而Bitmap实现的底层原理,就是把01110000和00011100进行与操作就行了。而计算机做与、或、非、异或等等操作是非常快的。
虽然bitmap有诸多好处,但是正所谓人无完人,它也存在很多缺陷。
- 只能存储正整数而不能是其他的类型;
- 不适合存储稀疏的集合,简单理解,一个集合存放了两个数[1,99999999],那用bitmap存储的话就很不划算,这也与它本来节约存储的优点也背离了;
- 不适用于存储重复的数据。
BitMap的优化
既然bitmap的优点如此突出,那应该如何去优化它存在的一些局限呢?
- 针对存储非正整数的类型,如字符串类型的,可以考虑将字符串类型的数据利用类似hash的方法,映射成整数的形式来使用bitmap,但是这个方法会有hash冲突的问题,解决这个可以优化hash方法,采用多重hash来解决,但是根据经验,这个效果都不太好,通常的做法就是针对字符串建立映射表的方式。
- 针对bitmap的优化最核心的还是对于其存储成本的优化,毕竟大数据领域里面,大多数时候数据都是稀疏数据,而我们又经常需要使用到bitmap的特长,比如去重等属性,所以存在一些进一步的优化,比较知名的有WAH、EWAH、RoaringBitmap等,其中性能最好并且应用最为广泛的当属RoaringBitmap
RoaringBitmap的核心原理
为了快速把这个原理说清楚,这里就不继续撸源码了,有兴趣的小伙伴可以自行搜索相关源码阅读,下面简单阐述一下它的核心原理:1个Int 类型相当于有32 bit 也就相当于2^32=2^16 x 2^16,这意味着任意一个Int 类型可以拆分成两个16bit的来存储,每一个拆出来的都不会大于2^16, 2^16就是65536,而Int的正整数实际最大值为 2147483647。而RoaringBitmap的压缩首先做的就是用原本的数去除65536,结果表示成(商,余数),其中商和余数是都不会超过65536。
如下图所示
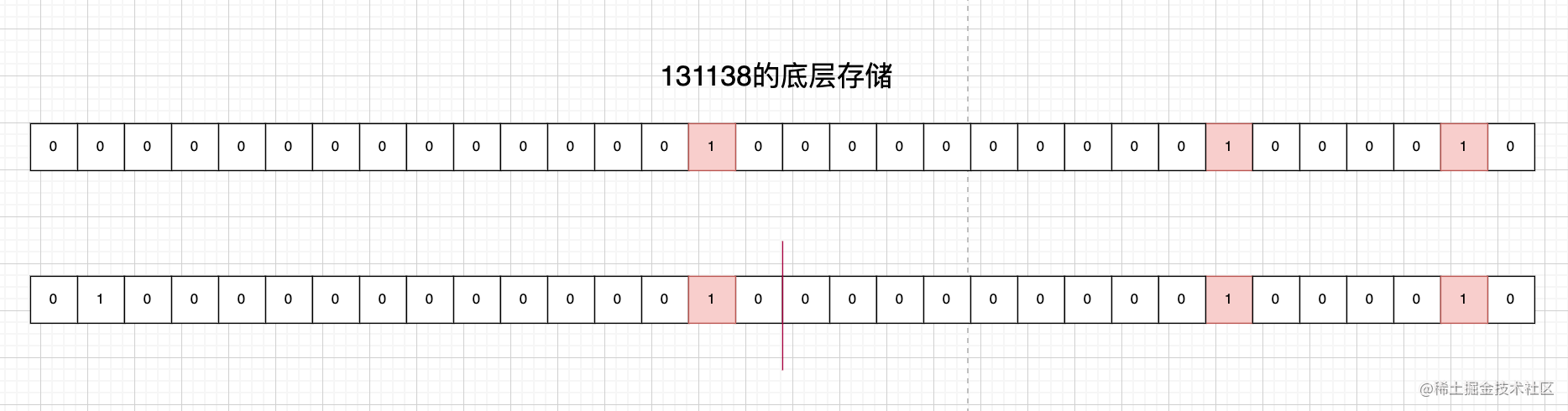
RoaringBitmap的做法就是将131138 原本32bit的存储结构,拆分成连两个16bit的结构,而拆分出的两个16bit分别存储了131138除65536的商2以及余数66。
在RoaringBitmap中,把商所处的16bit 被称为高16位,除数所处的16bit 被称为低16位。并用key和Container去存储的这些拆分出来的数据,其中key是short[] ,存放的就是商,因为bitmap的特性,商和余数不会存在完全相同的情况。
通过商来作为key划分不同的Container,就类似划分不同的桶,key就是标识数据应该存在哪个桶,container用来存对应数据的低16位的数字。比如 1000和60666 除以65536后的结果分别是(0,1000)和(0,60666),所以这两个数据存储到RoaringBitmap中,就会都放到key位0那个container中,container中就是1000和60666。
由于container中存放的数字是0~65536的一些数据,可能稀疏可能稠密,所以RoaringBitmap依据不同的场景,提供了 3 种不同的 Container,分别是 ArrayContainer 、 BitmapContainer 、RunContainer。
关于三个Container的存储原理如下:
- ArrayContainer 存储的方式就是 shot类型的数组, 每个数字占16bit 也就是2Byte,当id 数达到4096个时,占用4096x2 = 8196byte 也就是8kb,而id数最大是65536,占用 65536x2 =131072 byte 也就是128kb。
- BitmapContainer存储的方式就是bitmap类型,bitmap的位数为 65536,能存储0~65535个数字,占用 65536/8/1024=8kb,也就是bitmap container占用空间恒定为8kb。
- RunContainer存储的必须是连续的数字,比如存储1,2,3...100w,RunContainer就只会存储[1,100w]也就是开头和结尾的一个数字,其压缩效率取决于连续的数字有多长。
关于ArrayContainer和BitmapContainer的选择:

如图所示,可以看到ArrayContainer 更适合存放稀疏的数据,BitmapContainer 适合存放稠密的数据。在RoaringBitmap中,若一个 Container 里面的元素数量小于 4096,会使用 ArrayContainer 来存储。当 Array Container 超过最大容量 4096 时,会转换为 BitmapContainer,这样能够最大化的优化存储。
how
bitmap就像一柄双刃剑,用的好可以帮助我们破除瓶颈,解决痛点。用的不好不仅会丢失它所有的优点,还要搭上过多的存储,甚至会丧失掉最重要的准确性,所以要针对不同业务场景灵活使用我们的武器,才能事半功倍!
下面举例bitmap的一些使用场景,来看看实际开发中,到底怎么正确使用bitmap:
BitMap在用户分群的应用
假设有用户的标签宽表,对应字段及值如下
| user_id(用户id) | city_id(城市id) | is_user_start(是否启动) | is_evl(是否估价) | is_order(是否下单) |
|---|---|---|---|---|
| 1 | 1001 | 1 | 1 | 1 |
| 2 | 1001 | 1 | 1 | 0 |
| 3 | 1002 | 1 | 1 | 1 |
| 4 | 1002 | 1 | 0 | 0 |
| 5 | 1003 | 0 | 0 | 0 |
如果想根据标签划分人群,比如:1001城市 + 下单。
传统解决方案
通常是对列值进行遍历筛选,如果优化也就是列上建立索引,但是当这张表有很多标签列时,如果要索引生效并不是每列有索引就行,要每种查询组合建一个索引才能生效,索引数量相当于标签列排列组合的个数,当标签列有1、2 k 的时候,这基本就是不可能的。通常的做法是在数仓提前将热点的组合聚合过滤成新字段,或者只对热点组合加索引,但这样都很不灵活。
使用BitMap的方案
通过采用bitmap的办法,按字段重组成Bitmap。
| 标签 | 标签值 | bitmap字段底层二进制结构 |
|---|---|---|
| city_id(城市id) | 1001 | 00000110 |
| city_id(城市id) | 1002 | 00011000 |
| city_id(城市id) | 1003 | 00100000 |
| is_user_start(是否启动) | 1 | 00011110 |
| is_user_start(是否启动) | 0 | 00100000 |
| is_evl(是否估价) | 1 | 00001110 |
| is_evl(是否估价) | 0 | 00110000 |
| is_order(是否下单) | 1 | 00001010 |
| is_order(是否下单) | 0 | 00110100 |
把数据调整成这样的结构,再进行条件组合,那就简单了。比如: 1001城市 + 下单 = Bitmap[00000110] & Bitmap[00001010]= 1 ,这个计算速度相比宽表条件筛选是快很多的,如果数据是比较稠密的,bitmap可以极大的节省底层存储,如果数据比较稀疏,可以采用RoaringBitmap来优化。
BitMap在A/B实验平台业务的应用
在支持货拉拉A/B实验平台业务的场景中,会有一个实验对应很多司机的情况,因为要在数仓处理成明细宽表,来支持OLAP引擎的使用,随着维度的增多,数据发散的情况变得很严重,数仓及OLAP的存储与计算资源都消耗巨大。为了解决这个痛点,在架构组同事建议下,引入了BitMap,将组装好的司机id数组转换成RoaringBitmap格式,再传入到OLAP引擎里面使用。
在数仓应用层,由于引入了BitMap,重构了原本的数据表结构及链路,并优化了数仓的分层。不仅让整个链路耗时缩短了2个多小时,还节省了后续往OLAP引擎导数的时间,再算上数仓层的计算与存储资源的节省,很完美的实现了降本增效!而在OLAP引擎层,由架构组的同事通过二次开发,支持了Bitmap的使用,也取得了很不错的效果。
具体的落地与应用则在下篇文章给大家详细分享。
结语
本文首先通过对于BitMap的简单实现以及对于Java中BitSet源码的分析,提升读者对于其底层原理的理解,然后分析了BitMap的特点,并针对其存储优化的方案,讲解了RoaringBitmap技术的原理,最后列举了对于BitMap的常见使用场景。希望大家读后都能有所收获。
更多关于货拉拉BitMap大数据的资料请关注我们其它相关文章!
相关推荐
-
go数据结构和算法BitMap原理及实现示例
目录 1. BitMap介绍 如何判断数字在bit数组的位置 设置数据到bit数组 从bit数组中清除数据 数字是否在bit数组中 2. Go语言位运算 左移 右移 使用&^和位移运算来给某一位置0 3. BitMap的Go语言实现 定义 创建BitMap结构 将数据添加到BitMap 从BitMap中删除数据 判断BitMap中是否存在指定的数据 1. BitMap介绍 BitMap可以理解为通过一个bit数组来存储特定数据的一种数据结构.BitMap常用于对大量整形数据做去重和查询.在这类查
-

Redis特殊数据类型bitmap位图
目录 Redis数据类型bitmap位图 一.setbit 二.getbit 三.bitcount Redis数据类型bitmap位图 bitmap数据结构,是基于二进制位来进行操作记录的,只有0 和 1两个状态.可以想象成一个数组,里面只有0或者1. 能干嘛呢? 现实中会有这些场景,比如统计用户信息,活跃用户和非活跃用户.登录的.未登录的用户,打卡的.未打卡的,像这种只有2个状态,并且数据量非常大的,就适合使用bitmap. 网上找了一个对比,可以帮助记忆下bitmap的优点. 一.setbi
-
Redis中的bitmap详解
1.什么是bitmap? bitmap也叫位图,也就是用一个bit位来表示一个东西的状态,我们都知道bit位是二进制,所以只有两种状态,0和1. 2.为什么要有bitmap? bitmap的出现就是为了大数据量而来的,但是前提是统计的这个大数据量每个的状态只能有两种,因为每一个bit位只能表示两种状态. 下面我们直接以一个统计亿级用户活动的状态来说明吧. 3.案例说明 3.1.案例描述 如果有一个上亿用户的系统,需要我们去统计每一天的用户登录情况,我们应该如何去解决? 前提条件:设置在9月19号
-
Redis高级数据类型Hyperloglog、Bitmap的使用
前言 很多小伙伴在面试中都会被问道 Redis的常用数据结构有哪些? 可能很大一部分回答都是 string.hash.list.set.zset.当然啦,这个答案肯定是没有错的,但是相信这个答案,面试官已经听的耳朵都起茧了. 本身我们选择的这个行业竞争就极强,学历拼不过难道还要知识都拼不过吗??? 希望进来的小伙伴能好好看完这篇文章,也希望你以后的回答能是 常用的数据结构有string.hash.list.set.zset,但我平时可能还会用到 Hyperloglog和Bitmap.相信面试官听
-
Redis基于Bitmap实现用户签到功能
目录 功能分析 更多应用场景 总结 参考资料 很多应用上都有用户签到的功能,尤其是配合积分系统一起使用.现在有以下需求: 签到1天得1积分,连续签到2天得2积分,3天得3积分,3天以上均得3积分等. 如果连续签到中断,则重置计数,每月重置计数. 显示用户某月的签到次数和首次签到时间. 在日历控件上展示用户每月签到,可以切换年月显示. ... 功能分析 对于用户签到数据,如果直接采用数据库存储,当出现高并发访问时,对数据库压力会很大,例如双十一签到活动.这时候应该采用缓存,以减轻数据库的压力,Re
-
货拉拉大数据对BitMap的探索实践详解
目录 关于Bitmap What BitMap的简单实现 BitSet源码理解 备注信息 核心片段理解 Why BitMap的特点 BitMap的优化 RoaringBitmap的核心原理 how BitMap在用户分群的应用 传统解决方案 使用BitMap的方案 BitMap在A/B实验平台业务的应用 结语 关于Bitmap 在大数据时代,想要不断提升基于海量数据获取的决策.洞察发现和流程优化等能力,就需要不停思考,如何在利用有限的资源实现高效稳定地产出可信且丰富的数据,从而提高赋能下游产品的
-
Python实现大数据收集至excel的思路详解
一.在工程目录中新建一个excel文件 二.使用python脚本程序将目标excel文件中的列头写入,本文省略该部分的code展示,可自行网上查询 三.以下code内容为:实现从接口获取到的数据值写入excel的整体步骤 1.整体思路: (1).根据每日调取接口的日期来作为excel文件中:列名为"收集日期"的值 (2).程序默认是每天会定时调取接口并获取接口的返回值并写入excel中(我使用的定时任务是:linux下的contab) (3).针对接口异常未正确返回数据时,使用特殊符号
-
大数据开发phoenix连接hbase流程详解
目录 一.安装phoennix添加配置 二.启动phoenix服务 三.phoenix常用语法 四.java代码集成phoenix 一.安装phoennix添加配置 1.将phoenix-server-hbase-2.4-5.1.2.jar拷贝至hbase的的lib下 cp phoenix-server-hbase-2.4-5.1.2.jar ../hbase/lib/ 2.配置phoenix可以访问hbase的系统表 (1)将以下配置添加至hbase-site.xml中 <property>
-
Apache Pulsar 微信大流量实时推荐场景下实践详解
目录 导语 作者简介 实践 1:大流量场景下的 K8s 部署实践 实践 2:非持久化 Topic 的应用 实践 3:负载均衡与 Broker 缓存优化 实践 4:COS Offloader 开发与应用 未来展望与计划 导语 本文整理自 8 月 Apache Pulsar Meetup 上,刘燊题为<Apache Pulsar 在微信的大流量实时推荐场景实践>的分享.本文介绍了微信团队在大流量场景下将 Pulsar 部署在 K8s 上的实践与优化.非持久化 Topic 的应用.负载均衡与 Bro
-
Android Bitmap像素级操作详解
一:什么是Bitmap像素级的操作 相信大家都知道一张jpg或png放大后会是一个个小格子,称为一个像素(px),而且一个小格子是一种颜色,也就是一张jpg或png图片就是很多颜色的合集,而这些合集信息都被封装到了Bitmap类中.你可以使用Bitmap获取任意像素点,并修改它,对与某像素点而言,颜色信息是其主要的部分.所以像素级操作就是对一个个点的颜色超过. 二:载入与像素读写 在Android SDK中,图像的像素读写能够通过getPixel与setPixel两个Bitmap的API实现.
-
oracle数据匹配merge into的实例详解
oracle数据匹配merge into的实例详解 前言: 很久之前,估计在2010年左右在使用Oralce,当时有个需求就是需要对两个表的数据进行匹配,这两个表的数据结构一致,一个是正式表,一个是临时表,这两表数据量还算是比较大几百M.业务需求是用临时表中的数据和正式表的匹配,所有字段都需要一一匹配,而且两表还没有主键,这是一个比较麻烦和糟糕的事情. 场景: 1.如果两表所有字段值都一致则不处理: 2.如果有部分字段不一致则更新: 3.如果正式表中数据在临时表中不存在,则需要删除: 满足上面场
-
MySQL数据备份之mysqldump的使用详解
mysqldump常用于MySQL数据库逻辑备份. 1.各种用法说明 A. 最简单的用法: mysqldump -uroot -pPassword [database name] > [dump file] 上述命令将指定数据库备份到某dump文件(转储文件)中,比如: mysqldump -uroot -p123 test > test.dump 生成的test.dump文件中包含建表语句(生成数据库结构哦)和插入数据的insert语句. B. --opt 如果加上--opt参数则生成的du
-
vuejs实现本地数据的筛选分页功能思路详解
今天项目需要一份根据本地数据的筛选分页功能,好吧,本来以为很简单,网上搜了搜全是ajax获取的数据,这不符合要求啊,修改起来太费力气,还不如我自己去写,不多说直接上代码 效果图: 项目需要:点击左侧进行数据筛选,实现自动分页,自动生成页数,点击自动跳转 项目代码:js代码 var subList=new Vue({ el:'#main', data:{ // subcontentData为本地数据 subContents:subcontentData, // 页面需要展现的数据 yemianda
-
MATLAB教程数据运算变量操作及矩阵表示详解
目录 MATLAB数值数据 整数 浮点数 浮点型转换函数示例: 复数 数据的输出格式 变量及其操作 变量与赋值语句 预定义变量 变量的管理 MATLAB矩阵的表示 矩阵的建立 冒号表达式 矩阵的引用 MATLAB数值数据 整数 带符号8位整数数据的最大值时127,int8函数转换时只输出最大值. 浮点数 单精度 (single) 双精度(double) 单精度型实数在内存中只占用4个字节 双精度型实数在内存中占用8个字节 在MATLAB中数据默认位双精度型. 浮点型转换函数示例: 复数 实部和虚
-
Docker探索namespace详解
Docker通过namespace实现了资源隔离,通过cgroups实现了资源限制,通过写时复制(copy-on-write)实现了高效的文件操作. 1.namespace资源隔离 namepsace的6项隔离: namespace 系统调用参数 隔离内容 UTS CLONE_NEWUTS 主机名与域名 IPC CLONE_NEWIPC 信号量,消息队列和共享内存 PID CLONE_NEWPID 进程编号 Network CLONE_NEWNET 网络设备,网络栈,端口等 Mount CLON