Python处理EXCEL表格导入操作分步讲解
目录
- 一、前期准备
- 二、编写代码基本思路
- 三、编写代码读取数据
- 四、结语
一、前期准备
此篇使用两种导入excel数据的方式,形式上有差别,但两者的根本方法实际上是一样的。
首先需要安装两个模块,一个是pandas,另一个是xlrd。
在顶部菜单栏中点击文件,再点击设置,然后在设置中找到以下界面,并点击“+”号。

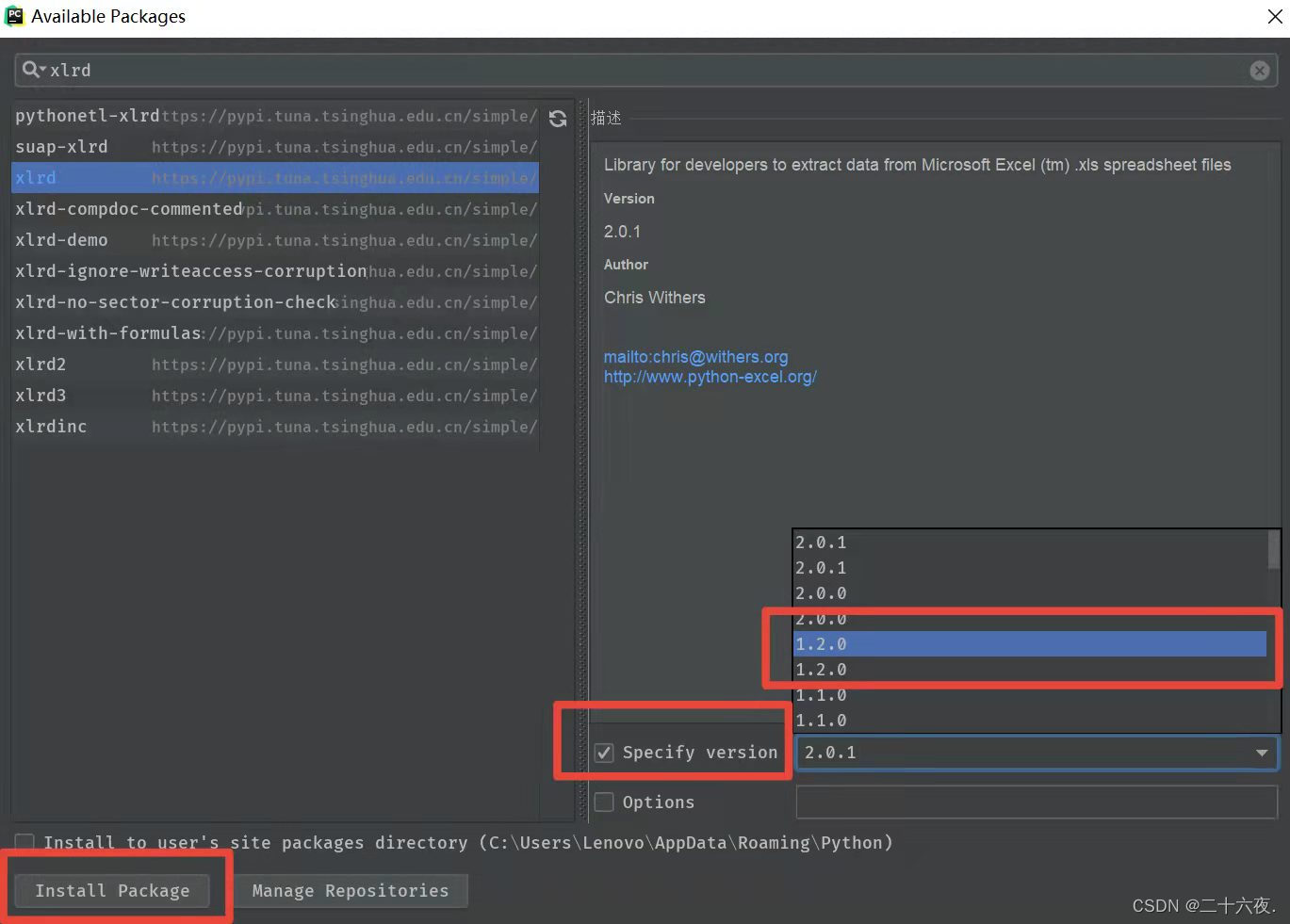
然后会出现以下界面,在搜索框中分别搜索以上两个模块:pandas/xlrd。

选中搜索出来的模块,并点击左下角的的安装按钮,便可将模块安装到自己电脑中。

需要注意的是,xlrd的新版本并不支持xlsx格式的excel表格,如果安装新版本的xlrd模块则会导致在运行代码的时候报错,而解决办法则是选择较低版本的xlrd模块进行安装。一般推荐安装1.2.0的版本即可。
当两个模块都安装好后,便可以开始编写代码用python来读取excel表格里的数据了。
二、编写代码基本思路
编写代码前需要思考打开EXCEL表格需要几步,或者说是哪些步骤。
(1)通过文件路径打开文件的工作簿。
(2)根据名称找到工作表。
(3)根据行(nrows)和列(ncols)读取单元格的位置。
(4)通过单元格位置获取单元格当中的数据(数值)。
三、编写代码读取数据
首先是第一种方式,即导入pandas的方式来读取EXCEL表格中的数据。
其中 r"D:\杂货\编码数据.xlsx" 为表格路径,sheet_name="Sheet1"为所读取的表单Sheet1。
pd.read_excel()为读取表格所使用的方法。
import pandas as pd#导入pandas库 fm=pd.read_excel(r"D:\杂货\编码数据.xlsx",sheet_name="Sheet1")#用该方法读取表格和表单里的单元格的数据 print(fm)
运行以上代码便可输出以下结果,由于表单的数据过多,因此在输出时其中间数据会以“···”的形式省略掉。

接下来是使用导入xlrd模块的方式来读取表格数据。
其中使用了xlrd.open_workbook()方法来打开EXCEL文件。
sheet_by_name()方法用于打开EXCEL文件中的Sheet表单。
通过两个for循环遍历出每个单元格的“行”和“列”的值,相当于坐标系中的“横轴”和“纵轴”,由此可以定义一个点的位置,EXCEL表格中同理,通过行列的数值可以得到指定单元格中的值。
最后将读取得到的每一个单元格的值放入到dataset这个列表中,并通过pprint输出该列表(若pprint报错则需要到设置中添加pprint,方法同本文“一、前期准备”部分),输出结果可见下图。
注:网络上有些代码示例在for循环中的range()函数可能会写成xrange()函数,而在python3中两者的功能都能在range()函数中实现,因此可直接使用range()函数,而不必太纠结于xrange()函数的问题。
import xlrd#导入xlrd库
file='D:/杂货/编码数据.xlsx'#文件路径
wb=xlrd.open_workbook(filename=file)#用方法打开该文件路径下的文件
ws=wb.sheet_by_name("Sheet1")#打开该表格里的表单
dataset=[]
for r in range(ws.nrows):#遍历行
col=[]
for l in range(ws.ncols):#遍历列
col.append(ws.cell(r, l).value)#将单元格中的值加入到列表中(r,l)相当于坐标系,cell()为单元格,value为单元格的值
dataset.append(col)
from pprint import pprint#pprint的输出形式为一行输出一个结果,下一个结果换行输出。实质上pprint输出的结果更为完整
pprint(dataset)
由于使用了循环遍历的方法,因此该处输出的结果为EXCEL文件中所包含的所有的单元格的值,因此输出结果很长,与前一部分的输出结果稍有不同。
四、结语
以上便是本篇的所有内容,编写该文的目的除了记录自学python数据处理的过程外,顺便将一些个人碰到的问题摘取下来,给出个人当时解决该类问题的方法与经验,并分享出来,适用于从零开始学习的朋友。并非专业的编程博主,存在的表述不正确等问题还请指出与理解。本篇为基础准备部分,后续会逐步分享其他的数据分析操作的教程。
到此这篇关于Python处理EXCEL表格导入操作分步讲解的文章就介绍到这了,更多相关Python EXCEL表格内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python实现读取excel表格详解方法
目录 一.python读取excel表格数据 1.读取excel表格数据常用操作 2.xlrd模块主要操作 3.读取单元格内容为日期时间的方式 4.读取合并单元格的数据 二.python写入excel表格数据 一.python读取excel表格数据 1.读取excel表格数据常用操作 import xlrd # 打开excel表格 data_excel = xlrd.open_workbook('data/dataset.xlsx') # 获取所有sheet名称 names = data_exc
-
Python办公自动化Word转Excel文件批量处理
目录 前言 首先使用Python将Word文件导入 row和cell解析所需内容 内层解析循环 前言 大家好,今天有一个公务员的小伙伴委托我给他帮个忙,大概是有这样一份Word(由于涉及文件私密所以文中的具体内容已做修改) 一共有近2600条类似格式的表格细栏,每个栏目包括的信息有: 日期 发文单位 文号 标题 签收栏 需要提取其中加粗的这三项内容到Excel表格中存储,表格样式如下: 也就是需要将收文时间.文件标题.文号填到指定位置,同时需要将时间修改为标准格式,如果是完全手动复制和修改时间,
-
python 对excel交互工具的使用详情
目录 python 对excel的 读入 与 改写 二.python 写入数据 1 . xlwt包写入Excel文件 2.openpyx 只可以读xlsx 不可读xls文档 三.小结 python 对excel的 读入 与 改写 (对比xlwt.openpyxl.xlrd) xlwt不支持写xlsx文件. openpyxl不支持读xls文件. 计划任务xlrd支持读xls,xlsx文件. 计划任务推荐读文件用xlrd,写文件用openpyxl. #一.xlrd 读 # 1.引入库& 下载库 xl
-
基于Python实现文本文件转Excel
目录 一.前言 二.openpyxl模块 1.安装 2.简单操作 三.文本文件转excel文件 1.寻找规律 2.开始转换 补充 一.前言 Excel文件是我们常用的一种文件,在工作中使用非常频繁.Excel中有许多强大工具,因此用Excel来处理文件会给我们带来很多便捷.但是有时候我们拿到了文件不是Excel文件,而且我们又想用Excel中的工具,这个时候我们就可以想办法把这个文件转换成Excel文件了.今天我们就来实现一下,需要注意我们只能把有规律的文件转换成Excel,而且今天的内容也不是
-
利用Python实现简单的Excel统计函数
目录 需求分析 解决步骤 最终结果 技术总结 需求分析 根据原始数据,计算出累计和.回撤.连续正确.连续错误.连续正确值与连续错误值6项数据,其中原始数据大于等于0认定为正确,原始数据小于0为错误.明白了要求,那我们就开始撸代码吧~ 解决步骤 import pandas as pd #创建一个计算数据的函数 def calculate(df): pass #读取原始数据,将索引列去除 df = pd.read_excel('需求0621.xlsx',index_col=0) #调用计算数据的函数
-
Python一步步带你操作Excel
目录 一.安装库的操作 二.xlwt库使用 三.xlrd库使用 四.openpyxl库使用-写入数据 五.openpyxl库使用-读取数据 ➤数据处理是 Python 的一大应用场景,而 Excel 则是最流行的数据处理软件.因此用 Python 进行数据相关的工作时,难免要和 Excel 打交道.Python处理Excel 常用的系列库有:xlrd.xlwt.xlutils.openpyxl ◈xlrd - 用于读取 Excel 文件,支持.xls和.xlsx格式 ◈xlwt - 用于写入 E
-
Python处理EXCEL表格导入操作分步讲解
目录 一.前期准备 二.编写代码基本思路 三.编写代码读取数据 四.结语 一.前期准备 此篇使用两种导入excel数据的方式,形式上有差别,但两者的根本方法实际上是一样的. 首先需要安装两个模块,一个是pandas,另一个是xlrd. 在顶部菜单栏中点击文件,再点击设置,然后在设置中找到以下界面,并点击“+”号. 然后会出现以下界面,在搜索框中分别搜索以上两个模块:pandas/xlrd. 选中搜索出来的模块,并点击左下角的的安装按钮,便可将模块安装到自己电脑中. 需要注意的是,xlrd的新版本
-
python 删除excel表格重复行,数据预处理操作
使用python删除excel表格重复行. # 导入pandas包并重命名为pd import pandas as pd # 读取Excel中Sheet1中的数据 data = pd.DataFrame(pd.read_excel('test.xls', 'Sheet1')) # 查看读取数据内容 print(data) # 查看是否有重复行 re_row = data.duplicated() print(re_row) # 查看去除重复行的数据 no_re_row = data.drop_d
-
利用Python改正excel表格数据
目录 一.前言 二.代码实现及讲解 1.模块的导入 2.获取“数据原表”中数据 3.获取生产记录更新表中的日期和材料 4.对生产数据更新表中数据的修改 5.最后,调用函数并保存数据 三.效果展示 四.结尾 一.前言 大家好,今天我来介绍我接一个Python单子.我完成这个单子前后不到2小时.首先我接到这个单子的想法是处理Excel表,在两个表之间建立联系,并通过项目需求,修改excel表中的数据.我是运用面向过程写的,将每一步都放在了不同的函数中,下面让我来介绍一下我是怎么通过自己的思路一步一步
-
Python读取Excel表格,并同时画折线图和柱状图的方法
今日给大家分享一个Python读取Excel表格,同时采用表格中的数值画图柱状图和折线图,这里只需要几行代码便可以实. 首先我们需要安装一个Excel操作的库xlrd,这个很简单,在安装Python后直接在DOS命令下输入pip install xlrd,便可以安装成功,如果还是不行,就输入Python -m pip install xlrd.后面会附上完整的代码和截图: 这行代码就是读取本地Excel文件的: data = xlrd.open_workbook(r'C:\\Users\\ASU
-
如何用python处理excel表格
openpyxl是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装. 读取Excel文件 需要导入相关函数 from openpyxl import load_workbook # 默认可读写,若有需要可以指定write_only和read_only为True wb = load_workbook('pythontab.xlsx') 默认打开的文件为可读写,若有需要可以指定参数read_only为True. 获取工作表--Sheet # 获得所有s
-
如何使用Python对Excel表格进行拼接合并
目录 准备工作 一.横向拼接 1.1 一般拼接 1.2 指定键进行拼接,即指定某一列作为两个表的连接依据. 1.2.1 多对一 1.2.2 多对多 1.2.3 用on来指定多个连接键 1.2.4 指定左右连接键 1.2.5 索引当作连接键 1.3 连接的方式 1.3.1 内连接(inner) 1.3.2 左连接(left) 1.3.3 右连接(right) 1.3.4 外连接(outer) 二.纵向拼接 2.1 普通合并 2.2 重叠数据的合并 三.整合代码 准备工作 我准备了两个表格数据,以此
-
使用Python对Excel进行读写操作
学习Python的过程中,我们会遇到Excel的读写问题.这时,我们可以使用xlwt模块将数据写入Excel表格中,使用xlrd模块从Excel中读取数据.下面我们介绍如何实现使用Python对Excel进行读写操作. Python版:3.5.2 通过pip安装xlwt,xlrd这两个模块,如果没有安装的话: pip install xlwt pip install xlrd 一.对Excel文件进行写入操作: # -*- conding:utf-8 -*- __author__ = 'mayi
-
python读取Excel表格文件的方法
python读取Excel表格文件,例如获取这个文件的数据 python读取Excel表格文件,需要如下步骤: 1.安装Excel读取数据的库-----xlrd 直接pip install xlrd安装xlrd库 #引入Excel库的xlrd import xlrd 2.获取Excel文件的位置并且读取进来 #导入需要读取Excel表格的路径 data = xlrd.open_workbook(r'C:\Users\NHT\Desktop\Data\\test1.xlsx') table = d
-
使用python对excel表格处理的一些小功能
python对excel表格处理的一些小功能 功能概览pandas库的一些应用文件读入计算表格中每一行的英文单词数简单用textblob进行自然语言情感分析判断一行中是不是有两列值都与其他行重复(可推广至多列)对表格中的两列自定义函数运算判断表格中某列中是否有空对表格某列中时间格式的修正运用matplotlib画时间序列图,重叠图 功能概览 做数模模拟赛时学到的一些对表格处理的知识,为了方便自己以后查找,遂写成一篇文章,也希望能帮助大家:) pandas库的一些应用 文件读入 代码如下,每一句后
-
c#使用EPPlus封装excel表格导入功能的问题
前言 最近做系统的时候有很多 excel导入 的功能,以前我前后端都做的时候是在前端解析,然后再做个批量插入的接口 我觉着这样挺好的,后端部分可以做的很简单(很偷懒的) 但是因为各种各样的原因,最终还是需要做个专门的 excel导入 接口 遇到的问题 由于之前从来没有在后端部分处理过表格,所以我选择看一下同事的代码是怎么写的 虽然我之前没写过相关的业务,但是直觉的认为这样写非常麻烦,那个 ExcelHelper 好像也没干什么事,我希望一套操作下来可以把 excel 转成能够直接传入 AddRa