Python制作CSDN免积分下载器
CSDN免积分下载 你懂的。
1、输入资源地址如:http://download.csdn.net/download/gengqkun/4127808
2、输入验证码
3、点击下载,会弹出浏览器下载。
注:成功率在70-80% ,界面很丑,请将就着用。
#-*-coding:utf-8-*-
#python3.3.5
import urllib.parse,urllib.request,http.cookiejar,io,webbrowser
import tkinter as tk
from tkinter import *
from tkinter.ttk import *
from urllib.request import urlopen
from PIL import Image, ImageTk
global root
#设置cookie
cookie = http.cookiejar.CookieJar()
cookieProc = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(cookieProc)
urllib.request.install_opener(opener)
#根据路径和POST内容来提交表单
def getUrlRequest(iUrl,iStrPostData):
postdata = urllib.parse.urlencode(iStrPostData)
postdata = postdata.encode(encoding='UTF8')
header = {'User-Agent':'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)'}
req= urllib.request.Request(
url = iUrl,
data = postdata,
headers = header)
data = urllib.request.urlopen(req).read()
try:
data = data.decode('utf-8')
except:
data = data.decode('gbk', 'ignore')
return data
#获取验证码图片
def getCodeImg():
urlCode='http://csdn.juming.com/code.htm'
image_bytes = urlopen(urlCode).read()
# internal data file
data_stream = io.BytesIO(image_bytes)
# open as a PIL image object
pil_image = Image.open(data_stream)
tk_image = ImageTk.PhotoImage(pil_image)
return tk_image
#构建界面
def createGui(msg=''):
global root
root = tk.Tk()
root.title("CSDN免积分下载器 v0.1")
root.resizable(False, False) #禁止修改窗口大小
root.geometry('+400+250') #屏幕位置
#-------------------------------------------
tk_image = getCodeImg()
# put the image on a typical widget
frm_top_label = tk.Label(root,compound = 'top',image=tk_image,text="验证码图片",fg="blue",bg="brown",font=('Tempus Sans ITC',20))
frm_top_label.grid(row = 0, column = 0, padx = 15, pady = 2)
#-------------------------------------------
frm_bottom = tk.LabelFrame(root)
frm_bottom.grid(row = 1, column = 0, padx = 15, pady = 2)
frm_bottom_label_0 = tk.Label(frm_bottom,text="下载地址:", font=('Tempus Sans ITC',15))
frm_bottom_label_0.grid(row = 0, column = 0, padx = 5, pady = 2,sticky = "e") #控件右对齐
frm_bottom_label_1 = tk.Label(frm_bottom,text=" 验证码:", font=('Tempus Sans ITC',15))
frm_bottom_label_1.grid(row = 1, column = 0, padx = 5, pady = 2,sticky = "e")
frm_bottom_entry_var_0 = StringVar()
frm_bottom_entry_0 = tk.Entry(frm_bottom,textvariable=frm_bottom_entry_var_0)
frm_bottom_entry_0.grid(row = 0, column = 1, padx = 15, pady = 2)
frm_bottom_entry_var_1 = StringVar()
frm_bottom_entry_1 = tk.Entry(frm_bottom,textvariable=frm_bottom_entry_var_1) #设置密码输入框,熟悉show
frm_bottom_entry_1.grid(row = 1, column = 1, padx = 15, pady = 2)
frm_bottom_btn_0 = tk.Button(frm_bottom,text="下 载",relief=RIDGE,bd=4,width=10, font=('Tempus Sans ITC',12),command=lambda:downloadSource(frm_bottom_entry_var_0,frm_bottom_entry_var_1,frm_top_label,frm_foot_label))
frm_bottom_btn_0.grid(row = 3, column = 1, padx = 15, pady = 2,sticky = "w")
frm_foot_label = tk.Label(root,text=msg ,font=('Tempus Sans ITC',10))
frm_foot_label.grid(row = 3, column = 0, padx = 15, pady = 2)
root.mainloop()
#获取下载资源地址
def getSourceUrl(code,ziyuandz):
#资源信息
strLoginInfo = {'csdn_zh': '用户名',
'csdn_mm': '密码',
're_yzm':code,
'ziyuandz':ziyuandz #'http://download.csdn.net/detail/shinian1987/8430743' #
}
#下载资源地址
urlLogin='http://csdn.juming.com/index.htm'
returnHtml = str(getUrlRequest(urlLogin,strLoginInfo))
a = returnHtml.find('电信下载地址:<strong>') + 15
b = returnHtml.find('</strong><br>网通下载地址:')
durl = returnHtml[a:b]
return durl
#下载资源
def downloadSource(frm_bottom_entry_var_0,frm_bottom_entry_var_1,frm_top_label,frm_foot_label):
try:
ziyuandz = frm_bottom_entry_var_0.get()
code = frm_bottom_entry_var_1.get()
durl = getSourceUrl(code,ziyuandz)
print('资源地址:'+ durl)
reMsg = "已经打开浏览器,请下载..."
yzm = durl.find("验证码")
#yzm += durl.find("验证码验证错误")
#yzm += durl.find("验证码输入不正确")
fs = durl.find("封杀本工具特意加")
gs = durl.find("正确的格式如")
jf = durl.find("成功获取到0点积分")
xzzy = durl.find("http:")
if fs > 0:
reMsg = "该资源被封杀,请稍后再下载..."
elif code=='':
reMsg = "验证码不能为空..."
elif ziyuandz=='':
reMsg = "下载地址不能为空..."
elif gs > 0:
reMsg = "资源地址错误,请重新输入..."
elif yzm > 0:
reMsg = "验证码输入错误..."
elif jf > 0:
reMsg = "积分不足,资源无法下载..."
elif xzzy >= 0:
webbrowser.open(durl, new=0, autoraise=True)
else:
reMsg = "资源错误或没有找到下载资源..."
#print(xzzy)
frm_foot_label['text'] = reMsg
tk_image = getCodeImg()
frm_top_label.configure(image = tk_image)
frm_top_label.image= tk_image
except:
root.destroy()
createGui('程序错误,请重新下载...')
#MAIN
createGui()
演示图片
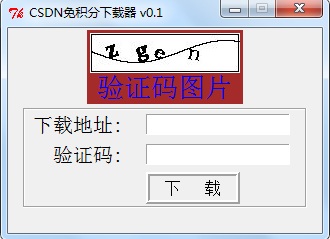
以上就是本文的全部内容了,希望大家能够喜欢。
相关推荐
-
iOS开发实现下载器的基本功能(1)
今天,做了一个下载器的Demo,即从本地配置的Apache服务器上,下载指定的文件.这次,我们下载服务器根目录下的html.mp4文件. 按照惯例,我们先创建一个URL对象和请求. NSURL *url = [NSURL URLWithString:@"http://127.0.0.1/html.mp4"]; NSURLRequest *request = [NSURLRequest requestWithURL:url]; 这里有两点需要注意,第一,这个url的字符串是全英文的,如
-
php实现的css文件背景图片下载器代码
本文实例讲述了php实现的css文件背景图片下载器代码.分享给大家供大家参考.具体实现方法如下: 下载css文件里面的背景图片是我们这些盗版份子长期搞的事情,下载个css图片下载器常出现各种广告弹窗,实在扛不住.这里就提供了一个php版的css文件背景图片下载器给大家. 把文件放到php程序目录 dos下面 php.exe cssImages.php 0 http://www.xxxx.com/css/style.css \images\ 先在php程序目录建个images文件夹,呵呵,贴代码:
-
命令行使用支持断点续传的java多线程下载器
复制代码 代码如下: package org.load.download; import java.io.File;import java.io.IOException;import java.io.InputStream;import java.io.RandomAccessFile;import java.text.DecimalFormat; import org.apache.http.HttpEntity;import org.apache.http.HttpResponse;impo
-
替换ctfmon.exe的下载器window.exe的方法
病毒描述: 此病毒利用替换输入法输入程序的方法伪装自身,从而可以利用原先已有的ctfmon启动项目启动自身,并进行下载木马和感染htm文件等操作 File: window.exe Size: 19380 bytes Modified: 2007年10月19日, 17:42:28 MD5: BDAA1AB926518C7D3C05B730C8B5872C SHA1: BF4C82AA7F169FF37F436B78BBE9AA7FD652118A CRC32: BEC77526 1.病毒运行后,生
-
python使用urllib模块开发的多线程豆瓣小站mp3下载器
复制代码 代码如下: #! /usr/bin/python2.7# -- coding:utf-8 -- import os, urllib,urllib2, thread,threadingimport re #匹配音乐urlreg=re.compile('{"name":"(.+?)".+?"rawUrl":"(.+?)",.+?}', re.I) class downloader(threading.Thread):
-

关于WIN32.EXE变态木马下载器的解决办法
一.WIN32.EXE的来源:http://fdghewrtewrtyrew.biz/adv/130/win32.exe 二.运行后的表现:此WIN32.EXE通过80和8080端口访问若干个IP,若防火墙不能监测到或令防火墙允许该访问,WIN32.EXE会自动下载木马Kernels8.exe到system32目录下:Kernels8.exe自网络下载1.dlb.2.dlb.....等一堆木马到当前用户文件夹中,并自动运行.下载的木马加载运行后,又从网络上下载其它木马/蠕虫. 木马/蠕虫完全下载
-
利用stream实现一个简单的http下载器
其实这个http下载器的功能已经相当完善了,支持:限速.post投递和上传.自定义http header.设置user agent.设置range和超时 而且它还不单纯只能下载http,由于使用了stream,所以也支持其他协议,你也可以用它来进行文件之间的copy.纯tcp下载等等.. 完整demo请参考:https://github.com/waruqi/tbox/wiki stream.c /* ///////////////////////////////////////////////
-
login.exe HGFS木马下载器的手动查杀方法
样本信息:File: login.exe Size: 25428 bytes Modified: 2008年4月25日, 16:30:08 MD5: 9777E8C79312F2E3D175AA1F64B07C11 SHA1: 4236D76C4FAEFE1CDF22414A25E946E493E0D52E CRC32: 5A562203 1.病毒初始化:创建互斥量HGFSMUTEX,保证系统内只有一个实例在运行 2.释放如下文件或者副本 %systemroot%\system32\Autoru
-
Android编程开发实现多线程断点续传下载器实例
本文实例讲述了Android编程开发实现多线程断点续传下载器.分享给大家供大家参考,具体如下: 使用多线程断点续传下载器在下载的时候多个线程并发可以占用服务器端更多资源,从而加快下载速度,在下载过程中记录每个线程已拷贝数据的数量,如果下载中断,比如无信号断线.电量不足等情况下,这就需要使用到断点续传功能,下次启动时从记录位置继续下载,可避免重复部分的下载.这里采用数据库来记录下载的进度. 效果图: 断点续传 1.断点续传需要在下载过程中记录每条线程的下载进度 2.每次下载开始之前先读取数据库
-
Python制作CSDN免积分下载器
CSDN免积分下载 你懂的. 1.输入资源地址如:http://download.csdn.net/download/gengqkun/4127808 2.输入验证码 3.点击下载,会弹出浏览器下载. 注:成功率在70-80% ,界面很丑,请将就着用. 复制代码 代码如下: #-*-coding:utf-8-*- #python3.3.5 import urllib.parse,urllib.request,http.cookiejar,io,webbrowser import tkinter
-
Python编写一个优美的下载器
本文实例为大家分享了Python编写下载器的具体代码,供大家参考,具体内容如下 #!/bin/python3 # author: lidawei # create: 2016-07-11 # version: 1.0 # 功能说明: # 从指定的URL将文件取回本地 ##################################################### import http.client import os import threading import time impo
-
基于PyQt5制作一个表情包下载器
每次和朋友聊天苦于没有表情包,而别人的表情包似乎是取之不尽.用之不竭.作为一个程序员哪能甘愿认输,于是做了一个表情包下载器供大家斗图. 首先,还是介绍一下设计思路吧,和我们之前做的百度图片下载器2.0一样,使用pyqt5作为UI界面制作的框架,然后就是找一个表情包网站供我们可以下载很多的表情包. 表情包使用的网站是这个,大家也可以使用自己发现的表情包网站做下载. 话不多说,我们先说明一下使用到的python库有哪些. UI界面使用到的pyqt5模块是下面这几个,之前也是一直使用这几个库做UI界面
-
python基于gevent实现并发下载器代码实例
这篇文章主要介绍了python基于gevent实现并发下载器代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 并发下载原理 import gevent from gevent import monkey import urllib.request monkey.patch_all() def my_download(url): print('GET: %s' % url) resp = urllib.request.urlopen(url
-
python 制作简单的音乐播放器
如你所见,功能很简单.只有基本的播放,停止,甚至只针对一首歌曲,仅供初学者参考学习用. 代码 from tkinter import * from tkinter import filedialog from pygame import mixer class MusicPlayer: def __init__(self, window ): window.geometry('320x100'); window.title('Iris Player'); window.resizable(0,0
-
python爬虫中的url下载器用法详解
前期的入库筛选工作已经由url管理器完成了,整理的工作自然要由url下载器接手.当我们需要爬取的数据已经去重后,下载器的主要任务的是这些数据下载下来.所以它的使用也并不复杂,不过需要借助到我们之前所学过的一个库进行操作,相信之前的基础大家都学的很牢固.下面小编就来为大家介绍url下载器及其使用的方法. 下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载下来.python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是
-
python实现csdn全部博文下载并转PDF
我们学习编程,在学习的时候,会有想把有用的知识点保存下来,我们可以把知识点的内容爬下来转变成pdf格式,方便我们拿手机可以闲时翻看,是很方便的 先来一个单个的博文下载转pdf格式的操作 python中将html转化为pdf的常用工具是Wkhtmltopdf工具包,在python环境下,pdfkit是这个工具包的封装类.如何使用pdfkit以及如何配置呢?分如下几个步骤. 下载wkhtmltopdf安装包,并且安装到电脑上. 下载地址:https://wkhtmltopdf.org/downloa
-
基于Python制作B站视频下载小工具
目录 1. 原理简介 2. 网页分析 3. 视频爬取 4. 存入本地 5. GUI工具制作 1. 原理简介 原理很简单,就是获取视频资源的源地址,然后爬取视频的二进制内容,再写入到本地即可. 2. 网页分析 打开该网页,然后F12进入开发者模式,接着点开网络—>全部,因为视频资源一般比较大,我这里根据大小进行了从大到小的排序,找到了第一条这些可能和视频源地址有关. 然后,我们复制找到的这条里的url部分不变的部分,回到元素中ctrl+F搜索,找到了可能和视频源地址有关的节点. 果然,我们复制这部
-
基于Python制作简易的windows修改器
现在应该大部分人都使用win11系统吧,不用也要强行给你更新到win11,win11其实挺好用哈,只是有一点不好用,就是右键的菜单,今天做个小程序,就是应该修改win11的一个应用程序 先来看一段视频哈! 视频链接 windows11修改器 提取码:v9ms 源代码加编译后的文件 提取码:enr4 该程序的安装包 已被博主做成了安装包 这款软件纯python制作,内容简单 1.可以将win11的右键改为win10经典版,还可以进行恢复 2.可以去掉win11右键的终端(也就是win11的最高管理
-
基于python实现的百度音乐下载器python pyqt改进版(附代码)
前言 之前写过一个用python实现的百度新歌榜.热歌榜下载器的文章,实现了百度新歌.热门歌曲的爬取与下载.但那个采用的是单线程,网络状况一般的情况下,扫描前100首歌的时间大概得到40来秒.而且用Pyqt做的界面,在下载的过程中进行窗口操作,会出现UI阻塞的现象. 前两天有时间调整了一下,做了几方面的改进: 1.修改了UI界面阻塞的问题,下载的过程中可以进行其它的UI操作; 2.爬虫程序采用一个主线程,8个子线程的方式快速爬取,网络状况一致的情况下,将扫描100首歌曲的时间提高到了8.9秒左右