Mysql 索引结构直观图解介绍
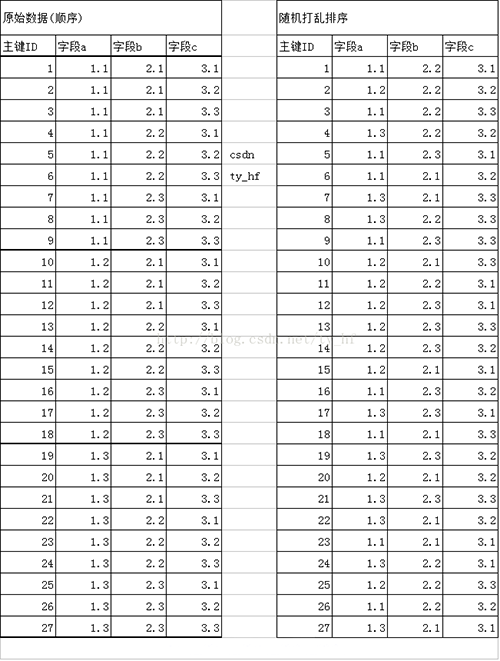
一.模拟创建原始数据 下图中,左边是自己方便说明,模拟的数据。引擎为mysiam~ 右边是用EXCEL把它们随机排列后的一个正常仿真数据表,把主键按照1-27再排列(不随机的话我在模拟数据时本来就是按顺序写的,再加索引看不大出这个索引排序的过程) 也就是说右边的数据,使我们要测试的原始数据,没建索引前是这样排序的,后边所有的数据都是以这个为依准进行的,这样更好看索引生成后的排序效果。 该表有4个字段(id,a,b,c),共21行数据
二.创建索引 a 如下图,当创建索引a以后,在该索引结构中,从原来的按照主键ID排序,变成了新的规则,我们说索引其实就是一个数据结构。则建立索引a,就是新另建立一个结构,排序按照字段a规则排序,第一条为主键ID为1代表的数据行,第二条ID=3的数据行,第三条ID=5代表的数据行。。。
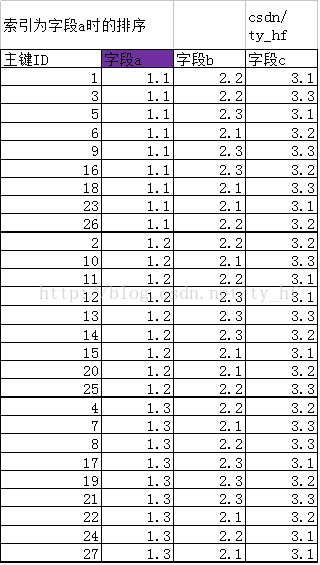
新排序主键ID(以ID代表他们这行的数据):1 3 5 6 9 16 18 23 26 2 10 11 12 13 14 15 20 25 4 7 8 17 19 21 22 24 27 不难发现,当字段a相同时,他们的排列 前后主键ID来排,比如同样是a=1.1的值,但是他们的排序是ID值为1,3,5,6。。对应的行,和主键ID排序顺序相近。
三.创建索引 (a,b) 如下图,当创建联合索引(a,b)以后,在该索引结构中,从原来的按照主键ID排序,变成了新的规则,排序规则先按照字段a排序,在a的基础上在按照字段b排序。即在索引a的基础上,对字段b也进行了排序。
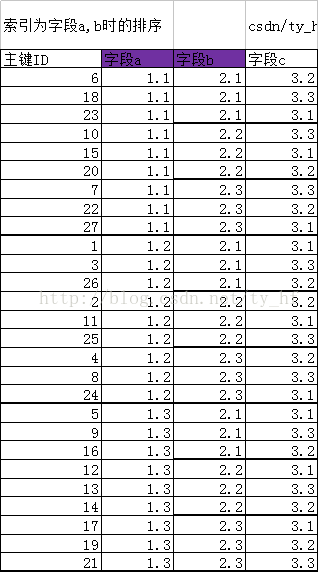
新排序主键ID(以ID代表他们这行的数据):6 18 23 10 15 20 7 22 27 1 3 26 2 11 25 4 8 24 5 9 16 12 13 14 17 19 21 不难发现,当字段a,b值都相同时,他们的排列前后,也是由主键ID决定的,比如同样是a=1.1,b=2.1的行(18,6,23),但是他们的排序是6,18,23。 字段(a,b)索引,先按a索引排序,然后在a的基础上,按照b排序 6 18 23 10 15 20 7 22 27 1 3 26 2 11 25 4 8 24 5 9 16 12 13 14 17 19 21
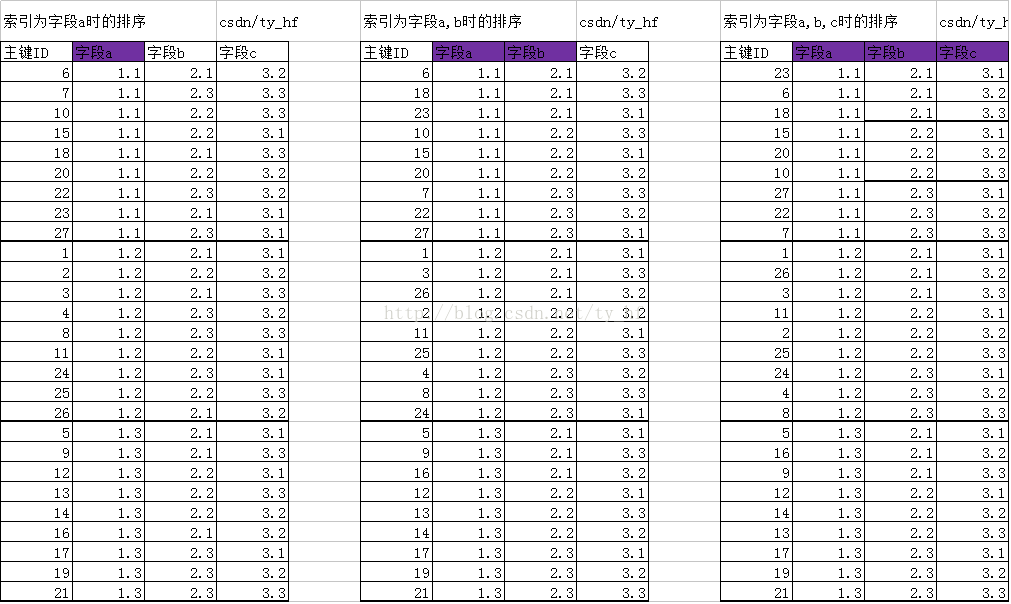
四.创建索引 (a,b,c)
字段(a,b,c)索引,先按a,b索引排序,然后在(a,b)的基础上,按照c排序
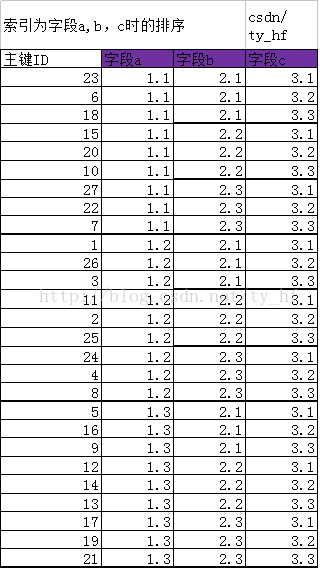
新排序主键ID(以ID代表他们这行的数据):23 6 18 15 20 10 27 22 7 1 26 3 11 2 25 24 4 8 5 16 9 12 14 13 17 19 21
五.结论:

和上一篇Mysql-索引-BTree类型【精简版】讲的一样,B-TREE树的最后一排叶子节点,从左往右排,就是按照这个顺序的,不同索引不同顺序。
我们知道,读取数据的一个过程(相当于找房间的过程),如果有索引(房间登记表),先读取索引的数据结构(因为它数据小读取快嘛),在其结构的叶子节点,找到真实物理磁盘的存放位置(相当于找到门牌号码了),然后拿着门牌号码去磁盘里直接拿数据,这就是一个读取数据的过程。如果没索引那你就相当于不知道目的地,挨个房间找吧。
当没有索引时,其实主键ID就是他们的索引,按照主键ID从小到大的规则排列; 当有所索引时,索引a,联合索引(a,b),联合索引(a,b,c)三者的对应3个B+TREE结构上,其叶子节点末尾指向的物理磁盘是是不一样的。
结论: 1.如果没有建立索引,是按照ID主键递增排列 2.当建立了索引a,会生成一个新的结构索引(B+TREE)用来记录新的一个结构规则,方便快速查找 3.当建立索引a,索引ab,索引abc,他们三个对应的数据排序是不一样的 4.索引abc,是兼顾了索引ab,索引a的,所以有前者时后两者可以不用建立 5.当建立了索引,非索引的列默认是按照ID递增来排序的
当新insert一条数据时,存储数据的同时,也会维护此表的一个索引,把它安放到一个合适的位置。解释了为什么再数据量特别大的时候索引可能会有负面影响,在被索引的表上INSERT和DELETE会变慢,频繁的插入删除数据同样会对维护索引消耗时间,瓶颈多少??500W? 这里是简单介绍一个索引的存储原理。
相关推荐
-
详解mysql中的冗余和重复索引
mysql允许在相同列上创建多个索引,无论是有意还是无意,mysql需要单独维护重复的索引,并且优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能. 重复索引是指的在相同的列上按照相同的顺序创建的相同类型的索引,应该避免这样创建重复索引,发现以后也应该立即删除.但,在相同的列上创建不同类型的索引来满足不同的查询需求是可以的. CREATE TABLE test( ID INT NOT NULL PRIMARY KEY, A INT NOT NULL, B INT NOT NULL, UNI
-
mysql为字段添加和删除唯一性索引(unique) 的方法
1.添加PRIMARY KEY(主键索引) mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) 2.添加UNIQUE(唯一索引) mysql>ALTER TABLE `table_name` ADD UNIQUE ( `column` ) 3.添加INDEX(普通索引) mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column` ) 4.添加FULLTEX
-
MySQL修改表一次添加多个列(字段)和索引的方法
MySQL修改表一次添加多个列(字段) ALTER TABLE table_name ADD func varchar(50), ADD gene varchar(50), ADD genedetail varchar(50); MySQL修改表一次添加多个索引 ALTER TABLE table_name ADD INDEX idx1 ( `func`), ADD INDEX idx2 ( `func`,`gene`), ADD INDEX idx3( `genedetail`); 以上这篇
-

Mysql 索引结构直观图解介绍
一.模拟创建原始数据 下图中,左边是自己方便说明,模拟的数据.引擎为mysiam~ 右边是用EXCEL把它们随机排列后的一个正常仿真数据表,把主键按照1-27再排列(不随机的话我在模拟数据时本来就是按顺序写的,再加索引看不大出这个索引排序的过程) 也就是说右边的数据,使我们要测试的原始数据,没建索引前是这样排序的,后边所有的数据都是以这个为依准进行的,这样更好看索引生成后的排序效果. 该表有4个字段(id,a,b,c),共21行数据 二.创建索引 a 如下图,当创建索引a以后,在该索引结构中,从
-
浅析MySQL索引结构采用B+树的问题
目录 1.B树和B+树 2.原因分析 3.总结 一位6年经验的小伙伴去字节面试的时候被问到这样一个问题,为什么MySQL索引结构要采用B+树?这位小伙伴从来就没有思考过这个问题.只因为现在都这么卷,后面还特意查了很多资料,他也希望听听我的见解. 另外,我花了1个多星期把往期的面试题解析配套文档准备好了,一共有10万字,想获取的小伙伴可以在我的煮叶简介中找到. 1.B树和B+树 一般来说,数据库的存储引擎都是采用B树或者B+树来实现索引的存储.首先来看B树,如图所示. B树是一种多路平衡树,用这种
-
MySQL索引结构详细解析
目录 简介 索引结构(树) 为什么用树,而不用哈希表 BTree索引 B+Tree索引 聚簇索引与非聚簇索引 索引分类 性能分析 索引创建场景 简介 在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法.这种数据结构,就是索引. 一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上. 优点: 1.类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本. 2.通过
-
MySQL索引类型总结和使用技巧以及注意事项
在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytable表: 复制代码 代码如下: CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL ); 我们随机向里面插入了10000条记录,其中有一条:5555, admin. 在查找username="admin"的记录 SELECT * FROM mytable WHERE username='admin';时,如果在
-
Mysql索引结合explain分析示例
目录 简介 1.索引分类 聚簇索引 为什么选择B+树 explain 简介 Mysql 在我们项目中使用是非常广的,当我们数据量大的时候,就需要考虑建立索引了,我感觉这也是一种以空间换时间的方式:在我们查询的时候,通过使用索引来提高速度:那么,我们在使用的过程中,怎么判定有没有走索引呢?有一个explain语句来进行分析,根据阿里的Java编程规范,至少类型要提升到range;我那时候就在想为什么要提升到range呢?后来结合Mysql的索引终于知道explain和Mysql底层B+树的对应关系
-
mysql 索引使用及优化详情
目录 前言 mysql索引原理 mysql索引分类 索引创建语法 1.创建索引 2.查看索引 3.删除索引 4.为 username和password创建联合索引 5.给user表添加一个info的字段,并为这个字段添加全文索引 已经存在的表创建.删除索引等 1.使用ALTER TABLE语句创建索引 2.使用ALTER TABLE语句删除索引 常用的索引设计原则 索引失效情况总结 尽量使用覆盖索引 前言 索引对有一定开发经验的同学来说并不陌生,合理使用索引,能大大提升sql查询的性能,可以这么
-
一篇文章讲解清楚MySQL索引
目录 一丶什么是索引 二丶索引的数据结构 1.哈希表 2.有序数组 3.跳表 4.平衡二叉搜索树 5.B-树,B+树 三丶InnoDB索引方案 1.InnoDB行结构 2.InnoDB页结构 2.1行结构中记录头信息的作用 2.2页目录 3.InnoDB索引方案 3.1为页建立目录项 3.2 根据目录项定位数据行的过程 三丶聚集索引和非聚集索引 四丶回表查询 五丶联合索引 六丶索引与排序和分组 1.索引用于排序 2.索引用于分组 七丶多范围读取MRR 八丶索引合并 1.交集索引合并 2.并集索引
-
MySQL索引的缺点以及MySQL索引在实际操作中有哪些事项
以下的文章主要介绍的是MySQL索引的缺点以及MySQL索引在实际操作中有哪些事项是值得我们大家注意的,我们大家可能不知道过多的对索引进行使用将会造成滥用.因此MySQL索引也会有它的缺点: 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT.UPDATE和DELETE.因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件. 建立索引会占用磁盘空间的索引文件.一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快. 索引只是提高效
-
简单谈谈Mysql索引与redis跳表
摘要 面试时,交流有关mysql索引问题时,发现有些人能够涛涛不绝的说出B+树和B树,平衡二叉树的区别,却说不出B+树和hash索引的区别.这种一看就知道是死记硬背,没有理解索引的本质.本文旨在剖析这背后的原理,欢迎留言探讨 问题 如果对以下问题感到困惑或一知半解,请继续看下去,相信本文一定会对你有帮助 mysql 索引如何实现 mysql 索引结构B+树与hash有何区别.分别适用于什么场景 数据库的索引还能有其他实现吗 redis跳表是如何实现的 跳表和B+树,LSM树有和区别呢 解析 首先
-
MySQL索引介绍及优化方式
目录 一.导致sql执行慢的原因 二.分析原因时,一定要找切入点 三.什么是索引? 四.Explain分析 1.id 2.select_type 3.table 4.type(★) 5.possible_key 6.key(★) 7.key_len 8.ref(★) 9.rows(★) 10.extra 五.优化案例 六.是否需要创建索引? 一.导致sql执行慢的原因 硬件条件限制: io吞吐量小,形成瓶颈(读取磁盘数据) 网络传输速度慢 内存不足(读取磁盘数据加载到内存) 程序设计方面: 没有