itchat和matplotlib的结合使用爬取微信信息的实例
前几天无意中看到了一片文章,《用 Python 爬了爬自己的微信朋友(实例讲解)》,这篇文章写的是使用python中的itchat爬取微信中朋友的信息,其中信息包括,昵称、性别、地理位置等,然后对这些信息进行统计并且以图像形式显示。文章对itchat的使用写的很详细,但是代码是贴图,画图使用R中的包画,我对着做了一遍,并且把他没有贴画图的代码做了一遍,画图是使用matplotlib。由于他没有贴代码,所以我把我写的贴出来供以后复制。
首先是安装itchat的包,可以使用清华大学的镜像:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple itchat
爬取微信好友男女比例:
import itchat
itchat.login()
friends=itchat.get_friends(update=True)[0:]
male=female=other=0
for i in friends[1:]:
sex=i['Sex']
if sex==1:
male+=1
elif sex==2:
female+=1
else:
other+=1
total=len(friends[1:])
malecol=round(float(male)/total*100,2)
femalecol=round(float(female)/total*100,2)
othercol=round(float(other)/total*100,2)
print('男性朋友:%.2f%%' %(malecol)+'\n'+
'女性朋友:%.2f%%' % (femalecol)+'\n'+
'性别不明的好友:%.2f%%' %(othercol))
print("显示图如下:")
画图:柱状图和饼状图,图片如下:
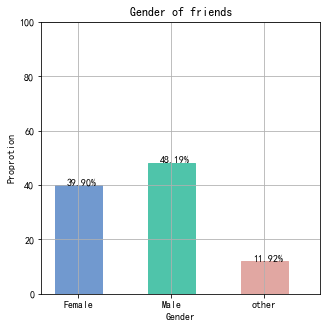

import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
#解决中文乱码不显示问题
mpl.rcParams['font.sans-serif'] = ['SimHei'] #指定默认字体
mpl.rcParams['axes.unicode_minus'] = False #解决保存图像是负号'-'显示为方块的问题
map = {
'Female': (malecol, '#7199cf'),
'Male': (femalecol, '#4fc4aa'),
'other': (othercol, '#e1a7a2')
}
fig = plt.figure(figsize=(5,5))# 整体图的标题
ax = fig.add_subplot(111)#添加一个子图
ax.set_title('Gender of friends')
xticks = np.arange(3)+0.15# 生成x轴每个元素的位置
bar_width = 0.5# 定义柱状图每个柱的宽度
names = map.keys()#获得x轴的值
values = [x[0] for x in map.values()]# y轴的值
colors = [x[1] for x in map.values()]# 对应颜色
bars = ax.bar(xticks, values, width=bar_width, edgecolor='none')# 画柱状图,横轴是x的位置,纵轴是y,定义柱的宽度,同时设置柱的边缘为透明
ax.set_ylabel('Proprotion')# 设置标题
ax.set_xlabel('Gender')
ax.grid()#打开网格
ax.set_xticks(xticks)# x轴每个标签的具体位置
ax.set_xticklabels(names)# 设置每个标签的名字
ax.set_xlim([bar_width/2-0.5, 3-bar_width/2])# 设置x轴的范围
ax.set_ylim([0, 100])# 设置y轴的范围
for bar, color in zip(bars, colors):
bar.set_color(color)# 给每个bar分配指定的颜色
height=bar.get_height()#获得高度并且让字居上一点
plt.text(bar.get_x()+bar.get_width()/4.,height,'%.2f%%' %float(height))#写值
plt.show()
#画饼状图
fig1 = plt.figure(figsize=(5,5))# 整体图的标题
ax = fig1.add_subplot(111)
ax.set_title('Pie chart')
labels = ['{}\n{} %'.format(name, value) for name, value in zip(names, values)]
ax.pie(values, labels=labels, colors=colors)#并指定标签和对应颜色
plt.show()
爬取其他信息,对省份分类并根据个数对其排序
#用来爬去各个变量
def get_var(var):
variable=[]
for i in friends:
value=i[var]
variable.append(value)
return variable
#调用函数得到各个变量,并把数据存到csv文件中,保存到桌面
NickName=get_var('NickName')
Sex=get_var('Sex')
Province=get_var('Province')
City=get_var('City')
Signature=get_var('Signature')
pros=set(Province)#去重
prosarray=[]
for item in pros:
prosarray.append((item,Province.count(item)))#获取个数
def by_num(p):
return p[1]
prosdsored=sorted(prosarray,key=by_num,reverse=True)#根据个数排序
画省份图:
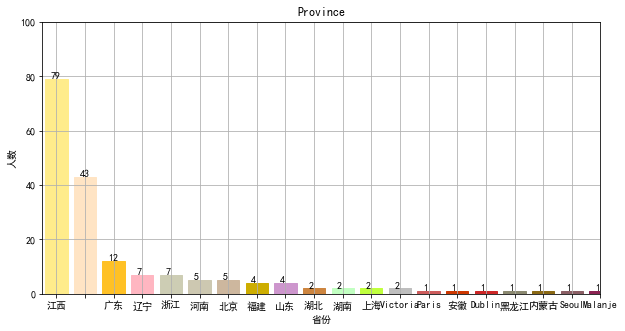
#画图
figpro = plt.figure(figsize=(10,5))# 整体图的标题
axpro = figpro.add_subplot(111)#添加一个子图
axpro.set_title('Province')
xticks = np.linspace(0.5,20,20)# 生成x轴每个元素的位置
bar_width = 0.8# 定义柱状图每个柱的宽度
pros=[]
values = []
count=0
for item in prosdsored:
pros.append(item[0])
values.append(item[1])
count=count+1
if count>=20:
break
colors = ['#FFEC8B','#FFE4C4','#FFC125','#FFB6C1','#CDCDB4','#CDC8B1','#CDB79E','#CDAD00','#CD96CD','#CD853F','#C1FFC1','#C0FF3E','#BEBEBE','#CD5C5C','#CD3700','#CD2626','#8B8970','#8B6914','#8B5F65','#8B2252']# 对应颜色
bars = axpro.bar(xticks, values, width=bar_width, edgecolor='none')
axpro.set_ylabel('人数')# 设置标题
axpro.set_xlabel('省份')
axpro.grid()#打开网格
axpro.set_xticks(xticks)# x轴每个标签的具体位置
axpro.set_xticklabels(pros)# 设置每个标签的名字
axpro.set_xlim(0,20)# 设置x轴的范围
axpro.set_ylim([0, 100])# 设置y轴的范围
for bar, color in zip(bars, colors):
bar.set_color(color)# 给每个bar分配指定的颜色
height=bar.get_height()#获得高度并且让字居上一点
plt.text(bar.get_x()+bar.get_width()/4.,height,'%.d' %float(height))#写值
plt.show()
还可以对数据进行保存:可用excel打开
#保存数据
from pandas import DataFrame
data={'NickName':NickName,'Sex':Sex,'Province':Province,'City':City,'Signature':Signature}
frame=DataFrame(data)
frame.to_csv('data.csv',index=True)
以上这篇itchat和matplotlib的结合使用爬取微信信息的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
itchat接口使用示例
有关itchat接口的知识,小编是初步学习,这里先给大家分享一段代码用法示例. sudo pip3 install itchat 今天用了下itchat接口,从url="https://lvyou.baidu.com/"上爬了数据,可以根据对方发的城市拼音比如qingdao自动回复这个城市的旅游信息. 有很多地方还没搞明白,但是程序照着数据分析那个公众号的一篇文章敲得,是可以运行了.具体的代码不到五十行: #Coding='utf-8' from time import ctime f
-

itchat和matplotlib的结合使用爬取微信信息的实例
前几天无意中看到了一片文章,<用 Python 爬了爬自己的微信朋友(实例讲解)>,这篇文章写的是使用python中的itchat爬取微信中朋友的信息,其中信息包括,昵称.性别.地理位置等,然后对这些信息进行统计并且以图像形式显示.文章对itchat的使用写的很详细,但是代码是贴图,画图使用R中的包画,我对着做了一遍,并且把他没有贴画图的代码做了一遍,画图是使用matplotlib.由于他没有贴代码,所以我把我写的贴出来供以后复制. 首先是安装itchat的包,可以使用清华大学的镜像:pip
-
使用python itchat包爬取微信好友头像形成矩形头像集的方法
初学python,我们必须干点有意思的事!从微信下手吧! 头像集样例如下: 大家可以发朋友圈开启辨认大赛哈哈~ 话不多说,直接上代码,注释我写了比较多,大家应该能看懂 import itchat import os import PIL.Image as Image from os import listdir import math import sys print("请输入查询模式:0-显示所有好友头像,但最终矩形头像集最后一行可能残缺:1-头像集为完整矩形,但好友可能不全,即在0模式下舍弃
-
python 爬取微信文章
本人想搞个采集微信文章的网站,无奈实在从微信本生无法找到入口链接,网上翻看了大量的资料,发现大家的做法总体来说大同小异,都是以搜狗为入口.下文是笔者整理的一份python爬取微信文章的代码,有兴趣的欢迎阅读 #coding:utf-8 author = 'haoning' **#!/usr/bin/env python import time import datetime import requests** import json import sys reload(sys) sys.setd
-
Scrapy基于selenium结合爬取淘宝的实例讲解
在对于淘宝,京东这类网站爬取数据时,通常直接使用发送请求拿回response数据,在解析获取想要的数据时比较难的,因为数据只有在浏览网页的时候才会动态加载,所以要想爬取淘宝京东上的数据,可以使用selenium来进行模拟操作 对于scrapy框架,下载器来说已经没多大用,因为获取的response源码里面没有想要的数据,因为没有加载出来,所以要在请求发给下载中间件的时候直接使用selenium对请求解析,获得完整response直接返回,不经过下载器下载,上代码 from selenium im
-
Python3爬虫学习之将爬取的信息保存到本地的方法详解
本文实例讲述了Python3爬虫学习之将爬取的信息保存到本地的方法.分享给大家供大家参考,具体如下: 将爬取的信息存储到本地 之前我们都是将爬取的数据直接打印到了控制台上,这样显然不利于我们对数据的分析利用,也不利于保存,所以现在就来看一下如何将爬取的数据存储到本地硬盘. 1 对.txt文件的操作 读写文件是最常见的操作之一,python3 内置了读写文件的函数:open open(file, mode='r', buffering=-1, encoding=None, errors=None,
-
Python3爬虫学习之MySQL数据库存储爬取的信息详解
本文实例讲述了Python3爬虫学习之MySQL数据库存储爬取的信息.分享给大家供大家参考,具体如下: 数据库存储爬取的信息(MySQL) 爬取到的数据为了更好地进行分析利用,而之前将爬取得数据存放在txt文件中后期处理起来会比较麻烦,很不方便,如果数据量比较大的情况下,查找更加麻烦,所以我们通常会把爬取的数据存储到数据库中便于后期分析利用. 这里,数据库选择MySQL,采用pymysql 这个第三方库来处理python和mysql数据库的存取,python连接mysql数据库的配置信息 db_
-
python爬取微信公众号文章
本文实例为大家分享了python爬取微信公众号文章的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from requests.exceptions import RequestException import time import random import MySQLdb import threading import socket import math soc
-
python使用webdriver爬取微信公众号
本文实例为大家分享了python使用webdriver爬取微信公众号的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- from selenium import webdriver import time import json import requests import re import random #微信公众号账号 user="" #公众号密码 password="" #设置要爬取的公众号列表 gzlist=['香河微服务
-
python3爬取torrent种子链接实例
本文环境是python3,采用的是urllib,BeautifulSoup搭建. 说下思路,这个项目分为管理器,url管理器,下载器,解析器,html文件生产器.各司其职,在管理器进行调度.最后将解析到的种子连接生产html文件显示.当然也可以保存在文件.最后效果如图. 首先在管理器SpiderMain()这个类的构造方法里初始化下载器,解析器,html生产器.代码如下. def__init__(self): self.urls = url_manager.UrlManager() self.d
-
Python如何使用BeautifulSoup爬取网页信息
这篇文章主要介绍了Python如何使用BeautifulSoup爬取网页信息,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 简单爬取网页信息的思路一般是 1.查看网页源码 2.抓取网页信息 3.解析网页内容 4.储存到文件 现在使用BeautifulSoup解析库来爬取刺猬实习Python岗位薪资情况 一.查看网页源码 这部分是我们需要的内容,对应的源码为: 分析源码,可以得知: 1.岗位信息列表在<section class="widg