使用imba.io框架得到比 vue 快50倍的性能基准

我是标题党吗?是,但也不是。以图为证。
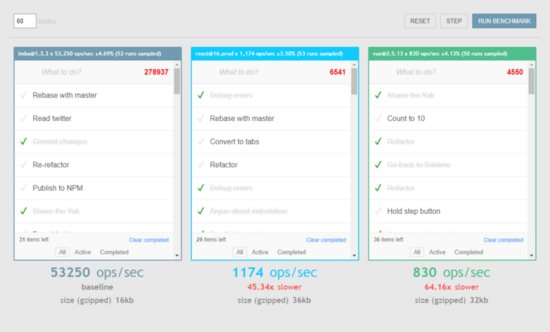
上图表示了vue, react 以及 imba 在 todo 这个项目中拥有60个 todoItem 不同进行 crud 操作的表现。可以看到 imba 达到了每秒操作5w次以上。如果你也想试一试该测试,可以访问Todos Bench。测试使用的是 Benchmark.js。
imba 简单介绍
imba 是一种新的编程语言,可以编译为高性能的 JavaScript。可以直接用于 Web 编程(服务端与客户端)开发。
下面是语法:
// 自定义标签
tag App
// 属性
prop items
// 方法定义
def addItem
if @input.value
items.push(title: @input.value)
@input.value = ""
def toggleItem item
item:completed = !item:completed
// 挂载 Imba.mount(element, into)
// 如果没有第二个参数,默认挂载到 document.body 上面
Imba.mount <App.vbox items=[] ->
<form.bar :submit.prevent.addItem>
<input@input>
<button> 'add'
<ul> for item in items
<li .done=item:completed :tap.toggleItem(item)> item:title
可以看出作者喜欢 ruby 以及 pug与,偏向于缩进类风格(个人并不是很喜欢这种语法风格)。具体语法可以参考 imba 文档 。当然了,因为可以编译成js,所以服务端编译成 js 进行node开发也是可以实现的。
imba 框架极速的性能基础
任何一个实现的性能优化都有其理论基础,那么 imba 性能那么快的基础究竟是什么呢?答案也就是 memoized DOM(记忆DOM)。
理论基础
浏览器的 DOM 操作可以说是浏览器最终要的功能,无论框架是基于虚拟 DOM 或者是真实 DOM,最终离不开操作 DOM 对象。
HTML DOM 是浏览器定义了访问和操作 HTML 文档的标准方法。但是操作 DOM 的接口是 JavaScript。但是浏览器通常会把 js 引擎和渲染引擎分开实现。也就是页面实际渲染部分是和解析js部分分开的。
借着《高性能的 JavaScript》话说,如果把 DOM 和 js 各自想象为岛屿。他们需要一座桥进行沟通。所以每一次执行 DOM 操作就过桥一次。
那我们先谈谈虚拟DOM,虚拟DOM 的性能提升在于是将 DOM 的对比放在了js层。进而通过对比不同之处来进行实际的 DOM 渲染。也就是说,其实虚拟DOM 并没有“实际”的性能收益,桥仍旧还在那边。仅仅在 js引擎需要过桥的那边找到了一位聪明睿智的大叔,对过桥的人和过桥的货物进行优化和限制(虚拟DOM 高性能的diff算法,状态批量更新)。
那么 memoized DOM 又是怎么做的呢?把 DOM 节点的控制直接放入内存之中。类似于此类优化.
function getEls(sel) {
// 设置缓存
if (!getEls.cache) getEls.cache = {};
// 如果缓存中存在 el,直接返回
if (getEls.cache[sel]) {
return getEls.cache[sel];
}
// 没有去通过 DOM 查询
const r = document.querySelectorAll(sel || '☺'),
length = r.length;
// 缓存并返回元素节点
return getEls.cache[sel] = (length == 1) ? r[0] : r;
}
我们可以测试一下。这里我写一个 getElsByDocument 以及 simplePerTest。
// 直接通过 querySelectorAll 获取节点
function getElsByDocument(sel) {
const r = document.querySelectorAll(sel || '☺'),
length = r.length;
return length == 1 ? r[0] : r;
}
// 简单性能测试
function simplePerTest(fn, el) {
const fnName = fn.name
console.time(fnName)
// 2000 次操作
for(let i = 0,len = 2000; i < len; i++) {
fn(el)
}
console.timeEnd(fnName)
}
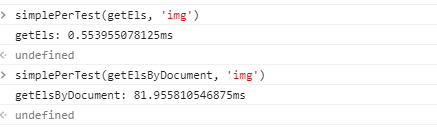
这个缓存的节点查询可要比 querySelectorAll 快了 140倍以上啊,随着 img 节点越多,得到的性能提升也越高啊。如果imba 框架中所有的节点都在内存中呢?同时,我们还会得到一个 js 运行时优化( GC 的大量减少),因为虚拟DOM 要维护一个树,在进行多次 crud 之后就会产生大量无用对象从而导致浏览器进行 GC,而 memoized DOM 在多次 crud 不会进行多次 GC。(可能会在渲染引擎中 GC?但我感觉渲染引擎中GC 要比JS 中影响要小很多。挖个坑,研究完渲染引擎再来探讨一下)
框架实践
实例如下所示:
tag Component
def render
<self>
<h1.title> "Welcome"
<p.desc> "I am a component"
上面的自定义组件会编译成下面的js
var Component = Imba.defineTag('Component', function(tag){
tag.prototype.render = function (){
var $ = this.$;
// 返回dom
return this.setChildren($.$ = $.$ || [
createElement('h1',$,0,this).flag('title').setText("Welcome"),
createElement('p',$,1,this).flag('desc').setText("I am a component")
]).synced();
};
});
仔细观察一下这里的函数,你会看到该组件在第一次调用渲染时,将使用 createElement 创建两个子节点,并设置它们的属性并且缓存。第二次或者第一万次调用时,children-array将被缓存,不会发生任何调用。
// 在第一次调用时候 $.$不存在 $.$会等于 后面的数组 // 第二次调用 $.$ 是存在的,无运行时消耗 $.$ = $.$ || 数组
其中查看源码,我们可以看到 setChildren 函数都是对真实DOM 进行了操作。获取之前的DOM节点进行一系列操作后将当前节点返回并缓存。
tag.prototype.setChildren = function (new$,typ){
var old = this._tree_;
if (new$ === old && (!(new$) || new$.taglen == undefined)) {
return this;
};
if (!old && typ != 3) {
this.removeAllChildren();
appendNested(this,new$);
} else if (typ == 1) {
var caret = null;
for (var i = 0, items = iter$(new$), len = items.length; i < len; i++) {
caret = reconcileNested(this,items[i],old[i],caret);
};
} else if (typ == 2) {
return this;
} else if (typ == 3) {
var ntyp = typeof new$;
if (ntyp != 'object') {
return this.setText(new$);
};
if (new$ && new$._dom) {
this.removeAllChildren();
this.appendChild(new$);
} else if (new$ instanceof Array) {
if (new$._type == 5 && old && old._type == 5) {
reconcileLoop(this,new$,old,null);
} else if (old instanceof Array) {
reconcileNested(this,new$,old,null);
} else {
this.removeAllChildren();
appendNested(this,new$);
};
} else {
return this.setText(new$);
};
} else if (typ == 4) {
reconcileIndexedArray(this,new$,old,null);
} else if (typ == 5) {
reconcileLoop(this,new$,old,null);
} else if ((new$ instanceof Array) && (old instanceof Array)) {
reconcileNested(this,new$,old,null);
} else {
// what if text?
this.removeAllChildren();
appendNested(this,new$);
};
this._tree_ = new$;
return this;
};
如果我们使用了动态属性。代码如下
tag Component
def render
<self>
<h1.title> "Welcome"
# 有 50% 几率 拥有 red class
<p.desc .red=(Math.random > 0.5)> "IMBA"
可以得到如下代码,详细查看可以看出,imba 提取了可变量,放入了 synced 函数中,每次渲染中只会执行 synced 里面的数据,所以依然会得到极高的渲染速度
var Component = Imba.defineTag('Component', function(tag){
tag.prototype.render = function (){
var $ = this.$;
return this.setChildren($.$ = $.$ || [
_1('h1',$,0,this).flag('title').setText("Welcome"),
_1('p',$,1,this).flag('desc').setText("Roulette")
],2).synced((
$[1].flagIf('red',Math.random() > 0.5)
,true));
};
});
精确的抽取不可变量,然后无需虚拟DOM 计算,同时对于真实DOM 还进行了缓存,我们可以看出 memoized DOM 与 虚拟DOM 不同,memoized DOM 是具有实际的性能收益。
imba 框架“虚假”的性能测试
我们在上面看到了 imba 框架的理论基础,那么他是否真的比vue快50倍?当然不是,这也就是在上面说我是标题党的原因。
浏览器的运行机制
浏览器本身只能达到 60 fps( 1 秒刷新了60次 )。当然了,其实对于体验而言,60fps的体验已经差不多够用了,也就是浏览器渲染上大概需要 17ms 去渲染一次。事实上无论是每秒操作dom 5w次还是 1000次,浏览器渲染引擎也只会记录当前的脏数据。然后在需要渲染时候再进行重绘与重排。
真实世界的内存限制
面对 memoized DOM 的缓存优化以及更少 GC 带来的运行时提升,我们需要更多内存来对每一个 dom节点进行缓存。这个在初始化渲染时有大量的消耗。同时我们的浏览器执行速度和渲染速度已经足够快了,虚拟DOM已经完全够用了。
imba 框架与浏览器的畅想
Google io 大会 chorme Portals 技术
单页应用程序(Single Page Applications,SPA)提供了很好的页面交互,但代价是构建的复杂性更高,多页面应用程序(Multi-page Applications,MPA)更容易构建,但最终会在页面之间出现空白屏幕。
Portals 结合了这两者的优势,主要用于改进网页交互体验,目标是无缝导航。它类似于 iframe ,内嵌在网页上,但可以导航到页面内容上。用户在一个页面跳转另一个内容时,虽然 URL 相应地发生变化,但是不需要打开另一个窗口,此时该内容标记的 Portals 会变成原来页面的顶级页面,同时原来页面在其后保持主进程地位。现场演示了这对于购物体验的极大便利,此外还有对漫画这类单页面应用的演示。

js引擎 与 渲染引擎的关联
在之前,浏览器 js引擎和渲染引擎是没有任何关联的,我们去写动画只能通过 setTimeout 或者 setInterval,更加没有办法知道浏览器什么时候处于空闲状态,但是随着时间的发展,我们可以通过 requestAnimationFrame 和 requestIdleCallback。requestAnimationFrame 要求浏览器在下次重绘之前调用指定的回调函数更新动画。requestIdleCallback方法将在浏览器的空闲时段期间对要调用的队列函数进行执行。
那么内置DOM 操作是否能够在js引擎中,是否能够减少过桥的性能消耗或者完全把桥打通。让我们拭目以待。
相关推荐
-
使用异步组件优化Vue应用程序的性能
单页应用其一个问题是首屏屏渲染速度较慢.这是因为页面首次加载时服务器将向客户端发送大量JavaScript,在屏幕上显示任何内容之前必须下载并解析.可以想象,随着应用程序规模的扩大,这个问题对用户体验的影响也会越来越突出. 现在幸运的是,当使用Vue CLI构建Vue应用程序时(使用webpack),可以采取一些措施来抵消这种情况.在本文中,我将演示如何在应用程序的初始渲染之后使用 异步组件 和webpack的代码分割功能加载到页面的某些部分.这将使初始加载时间降至最低,并为您的应用程序提供更好
-

如何测量vue应用运行时的性能
在上一篇文章中,我们讨论了如何提高大型数据的性能.但是我们还没有测量它提高了多少. 我们可以使用Chrome DevTools 的性能选项来实现这一点.但是为了获取准确数据,我们必须在Vue上激活性能模式. 我们可以在main.js或者插件中设置全局变量,代码如下: Vue.config.performance = true; 如果你设置了正确的 NODE_ENV 环境变量,那么可以使用非生产环境做判断. const isDev = process.env.NODE_ENV !== "produ
-
如何提升vue.js中大型数据的性能
你好!欢迎大家访问VueDose的第一篇文章!我们在VueDose中开始冒险吧,你会喜欢这些对你有帮助的小技巧. VueDose的所有的文章都非常的简洁,我相信人们在这种格式下更容易找到有用的东西.所以,让我们直奔主题. 通常我们需要获取对象数据,比如用户,项目,文章,等等等等····· 有时,我们甚至不需要修改它们,只是为了展示它们或在(a.k.a. Vuex)中存贮它们的全局状态.那么获取这个数据的简单代码如下: export default { data: () => ({ users:
-
mpvue性能优化实战技巧(小结)
最近一直在折腾mpvue写的微信小程序的性能优化,分享下实战的过程. 先上个优化前后的图: 可以看到打包后的代码量从813KB减少到387KB,Audits体验评分从B到A,效果还是比较明显的.其实这个指标说明不了什么,而且轻易就可以做到,更重要的是优化小程序运行过程中的卡顿感,请耐心往下看. 常规优化 常规的Web端优化方法在小程序中也是适用的,而且不可忽视. 一.压缩图片 这一步最简单,但是容易被忽视.在tiny上在线压缩,然后下载替换即可. 我这项目的压缩率高达72%,可以说打包后的代码从
-
浅谈Vue 性能优化之深挖数组
背景 最近在用 Vue 重构一个历史项目,一个考试系统,题目量很大,所以核心组件的性能成为了关注点.先来两张图看下最核心的组件 Paper 的样式. 从图中来看,分为答题区与选择面板区. 稍微对交互逻辑进行下拆解: 答题模式与学习模式可以相互切换,控制正确答案显隐. 单选与判断题直接点击就记录答案正确性,多选是选择答案之后点击确定才能记录正确性. 选择面板则是记录做过的题目的情况,分为六种状态(未做过的,未做过且当前选择的,做错的,做错的且当前选择的,做对的,做对的且当前选择的),用不同的样式去
-
使用imba.io框架得到比 vue 快50倍的性能基准
我是标题党吗?是,但也不是.以图为证. 上图表示了vue, react 以及 imba 在 todo 这个项目中拥有60个 todoItem 不同进行 crud 操作的表现.可以看到 imba 达到了每秒操作5w次以上.如果你也想试一试该测试,可以访问Todos Bench.测试使用的是 Benchmark.js. imba 简单介绍 imba 是一种新的编程语言,可以编译为高性能的 JavaScript.可以直接用于 Web 编程(服务端与客户端)开发. 下面是语法: // 自定义标签 tag
-
Vue服务端渲染和Vue浏览器端渲染的性能对比(实例PK )
Vue 2.0 开始支持服务端渲染的功能,所以本文章也是基于vue 2.0以上版本.网上对于服务端渲染的资料还是比较少,最经典的莫过于Vue作者尤雨溪大神的 vue-hacker-news.本人在公司做Vue项目的时候,一直苦于产品.客户对首屏加载要求,SEO的诉求,也想过很多解决方案,本次也是针对浏览器渲染不足之处,采用了服务端渲染,并且做了两个一样的Demo作为比较,更能直观的对比Vue前后端的渲染. talk is cheap,show us the code!话不多说,我们分别来看两个D
-
Cookbook组件形式:优化 Vue 组件的运行时性能
Vue 2.0 在发布之初,就以其优秀的运行时性能著称,你可以通过这个第三方 benchmark来对比其他框架的性能.Vue 使用了 Virtual DOM 来进行视图渲染,当数据变化时,Vue 会对比前后两棵组件树,只将必要的更新同步到视图上. Vue 帮我们做了很多,但对于一些复杂场景,特别是大量的数据渲染,我们应当时刻关注应用的运行时性能. 本文仿照Vue Cookbook组织形式,对优化 Vue 组件的运行时性能进行阐述. 基本的示例 在下面的示例中,我们开发了一个树形控件,支持基本的树
-
几行代码让 Python 函数执行快 30 倍
目录 1.Python 多线程处理的基本指南 2.多处理入门 3.它为什么如此重要? 4.实现 5.基准测试 Python 是一种流行的编程语言,也是数据科学社区中最受欢迎的语言.与其他流行编程语言相比,Python 的主要缺点是它的动态特性和多功能属性拖慢了速度表现.Python 代码是在运行时被解释的,而不是在编译时被编译为原生代码. 1.Python 多线程处理的基本指南 C 语言的执行速度比 Python 代码快 10 到 100 倍.但如果对比开发速度的话,Python 比 C 语言要
-
几行代码让 Python 函数执行快 30 倍
目录 1.Python 多线程处理的基本指南 2.多处理入门 3.它为什么如此重要? 4.实现 5.基准测试 Python 是一种流行的编程语言,也是数据科学社区中最受欢迎的语言.与其他流行编程语言相比,Python 的主要缺点是它的动态特性和多功能属性拖慢了速度表现.Python 代码是在运行时被解释的,而不是在编译时被编译为原生代码. 1.Python 多线程处理的基本指南 C 语言的执行速度比 Python 代码快 10 到 100 倍.但如果对比开发速度的话,Python 比 C 语言要
-
详解Java中IO字节流基本操作(复制文件)并测试性能
此次案例将以复制文件的形式来演示IO字节流的基本操作,复制一个mp3文件,文件信息如下图: main方法测试 public static void main(String[] args) throws Exception { //源文件 String srcFile = "src/a.mp3"; //目的文件 String destFile = "src/b.mp3"; long start = System.currentTimeMillis(); ... 复制文
-
Python读取文件比open快十倍的库fileinput
目录 1. 从标准输入中读取 2. 单独打开一个文件 3. 批量打开多个文件 4. 读取的同时备份文件 5. 标准输出重定向替换 6. 不得不介绍的方法 7. 进阶一点的玩法 8. 列举一些实用案例 9. 写在最后 使用 open 函数去读取文件,似乎是所有 Python 工程师的共识. 今天明哥要给大家推荐一个比 open 更好用.更优雅的读取文件方法 – 使用 fileinput 1. 从标准输入中读取 当你的 Python 脚本没有传入任何参数时,fileinput 默认会以 stdin
-
前端框架之封装Vue第三方组件三个技巧
目录 引言 一.使用第三方组件的属性 二.使用第三方组件的自定义事件 三.使用第三方组件的插槽 四.使用第三方组件的方法 引言 在封装第三方组件中,经常会遇到一个问题,如何通过封装的组件去使用第三方组件的Attributes(属性).Events(自定义事件).Methods(方法).Slots(插槽). 当然这个问题并不是难以解决,用普通方法解决难免陷入繁琐重复的工作中,而且封装的组件代码可读性也不高. 本专栏将介绍三种技巧来使用第三方组件的Attributes(属性).Events(自定义事
-
iOS + node.js使用Socket.IO框架进行实时通信示例
Socket.IO是一个基于WebSocket的实时通信库,在主流平台都有很好的支持,此文主要是通过一个小例子来演示Socket.IO的使用. 基础环境搭建 新建一个文件夹(JS工程),创建一个package.json,复制以下内容并保存. { "name": "socket-chat-example", "version": "0.0.1", "description": "my first s