python实现决策树分类
上一篇博客主要介绍了决策树的原理,这篇主要介绍他的实现,代码环境python 3.4,实现的是ID3算法,首先为了后面matplotlib的绘图方便,我把原来的中文数据集变成了英文。
原始数据集:

变化后的数据集在程序代码中体现,这就不截图了
构建决策树的代码如下:
#coding :utf-8
'''
2017.6.25 author :Erin
function: "decesion tree" ID3
'''
import numpy as np
import pandas as pd
from math import log
import operator
def load_data():
#data=np.array(data)
data=[['teenager' ,'high', 'no' ,'same', 'no'],
['teenager', 'high', 'no', 'good', 'no'],
['middle_aged' ,'high', 'no', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'same', 'yes'],
['old_aged', 'low', 'yes', 'same' ,'yes'],
['old_aged', 'low', 'yes', 'good', 'no'],
['middle_aged', 'low' ,'yes' ,'good', 'yes'],
['teenager' ,'middle' ,'no', 'same', 'no'],
['teenager', 'low' ,'yes' ,'same', 'yes'],
['old_aged' ,'middle', 'yes', 'same', 'yes'],
['teenager' ,'middle', 'yes', 'good', 'yes'],
['middle_aged' ,'middle', 'no', 'good', 'yes'],
['middle_aged', 'high', 'yes', 'same', 'yes'],
['old_aged', 'middle', 'no' ,'good' ,'no']]
features=['age','input','student','level']
return data,features
def cal_entropy(dataSet):
'''
输入data ,表示带最后标签列的数据集
计算给定数据集总的信息熵
{'是': 9, '否': 5}
0.9402859586706309
'''
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
label = featVec[-1]
if label not in labelCounts.keys():
labelCounts[label] = 0
labelCounts[label] += 1
entropy = 0.0
for key in labelCounts.keys():
p_i = float(labelCounts[key]/numEntries)
entropy -= p_i * log(p_i,2)#log(x,10)表示以10 为底的对数
return entropy
def split_data(data,feature_index,value):
'''
划分数据集
feature_index:用于划分特征的列数,例如“年龄”
value:划分后的属性值:例如“青少年”
'''
data_split=[]#划分后的数据集
for feature in data:
if feature[feature_index]==value:
reFeature=feature[:feature_index]
reFeature.extend(feature[feature_index+1:])
data_split.append(reFeature)
return data_split
def choose_best_to_split(data):
'''
根据每个特征的信息增益,选择最大的划分数据集的索引特征
'''
count_feature=len(data[0])-1#特征个数4
#print(count_feature)#4
entropy=cal_entropy(data)#原数据总的信息熵
#print(entropy)#0.9402859586706309
max_info_gain=0.0#信息增益最大
split_fea_index = -1#信息增益最大,对应的索引号
for i in range(count_feature):
feature_list=[fe_index[i] for fe_index in data]#获取该列所有特征值
#######################################
'''
print('feature_list')
['青少年', '青少年', '中年', '老年', '老年', '老年', '中年', '青少年', '青少年', '老年',
'青少年', '中年', '中年', '老年']
0.3467680694480959 #对应上篇博客中的公式 =(1)*5/14
0.3467680694480959
0.6935361388961918
'''
# print(feature_list)
unqval=set(feature_list)#去除重复
Pro_entropy=0.0#特征的熵
for value in unqval:#遍历改特征下的所有属性
sub_data=split_data(data,i,value)
pro=len(sub_data)/float(len(data))
Pro_entropy+=pro*cal_entropy(sub_data)
#print(Pro_entropy)
info_gain=entropy-Pro_entropy
if(info_gain>max_info_gain):
max_info_gain=info_gain
split_fea_index=i
return split_fea_index
##################################################
def most_occur_label(labels):
#sorted_label_count[0][0] 次数最多的类标签
label_count={}
for label in labels:
if label not in label_count.keys():
label_count[label]=0
else:
label_count[label]+=1
sorted_label_count = sorted(label_count.items(),key = operator.itemgetter(1),reverse = True)
return sorted_label_count[0][0]
def build_decesion_tree(dataSet,featnames):
'''
字典的键存放节点信息,分支及叶子节点存放值
'''
featname = featnames[:] ################
classlist = [featvec[-1] for featvec in dataSet] #此节点的分类情况
if classlist.count(classlist[0]) == len(classlist): #全部属于一类
return classlist[0]
if len(dataSet[0]) == 1: #分完了,没有属性了
return Vote(classlist) #少数服从多数
# 选择一个最优特征进行划分
bestFeat = choose_best_to_split(dataSet)
bestFeatname = featname[bestFeat]
del(featname[bestFeat]) #防止下标不准
DecisionTree = {bestFeatname:{}}
# 创建分支,先找出所有属性值,即分支数
allvalue = [vec[bestFeat] for vec in dataSet]
specvalue = sorted(list(set(allvalue))) #使有一定顺序
for v in specvalue:
copyfeatname = featname[:]
DecisionTree[bestFeatname][v] = build_decesion_tree(split_data(dataSet,bestFeat,v),copyfeatname)
return DecisionTree
绘制可视化图的代码如下:
def getNumLeafs(myTree):
'计算决策树的叶子数'
# 叶子数
numLeafs = 0
# 节点信息
sides = list(myTree.keys())
firstStr =sides[0]
# 分支信息
secondDict = myTree[firstStr]
for key in secondDict.keys(): # 遍历所有分支
# 子树分支则递归计算
if type(secondDict[key]).__name__=='dict':
numLeafs += getNumLeafs(secondDict[key])
# 叶子分支则叶子数+1
else: numLeafs +=1
return numLeafs
def getTreeDepth(myTree):
'计算决策树的深度'
# 最大深度
maxDepth = 0
# 节点信息
sides = list(myTree.keys())
firstStr =sides[0]
# 分支信息
secondDict = myTree[firstStr]
for key in secondDict.keys(): # 遍历所有分支
# 子树分支则递归计算
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
# 叶子分支则叶子数+1
else: thisDepth = 1
# 更新最大深度
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
# ==================================================
# 输入:
# nodeTxt: 终端节点显示内容
# centerPt: 终端节点坐标
# parentPt: 起始节点坐标
# nodeType: 终端节点样式
# 输出:
# 在图形界面中显示输入参数指定样式的线段(终端带节点)
# ==================================================
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
'画线(末端带一个点)'
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', xytext=centerPt, textcoords='axes fraction', va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
# =================================================================
# 输入:
# cntrPt: 终端节点坐标
# parentPt: 起始节点坐标
# txtString: 待显示文本内容
# 输出:
# 在图形界面指定位置(cntrPt和parentPt中间)显示文本内容(txtString)
# =================================================================
def plotMidText(cntrPt, parentPt, txtString):
'在指定位置添加文本'
# 中间位置坐标
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
# ===================================
# 输入:
# myTree: 决策树
# parentPt: 根节点坐标
# nodeTxt: 根节点坐标信息
# 输出:
# 在图形界面绘制决策树
# ===================================
def plotTree(myTree, parentPt, nodeTxt):
'绘制决策树'
# 当前树的叶子数
numLeafs = getNumLeafs(myTree)
# 当前树的节点信息
sides = list(myTree.keys())
firstStr =sides[0]
# 定位第一棵子树的位置(这是蛋疼的一部分)
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
# 绘制当前节点到子树节点(含子树节点)的信息
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
# 获取子树信息
secondDict = myTree[firstStr]
# 开始绘制子树,纵坐标-1。
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys(): # 遍历所有分支
# 子树分支则递归
if type(secondDict[key]).__name__=='dict':
plotTree(secondDict[key],cntrPt,str(key))
# 叶子分支则直接绘制
else:
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
# 子树绘制完毕,纵坐标+1。
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
# ==============================
# 输入:
# myTree: 决策树
# 输出:
# 在图形界面显示决策树
# ==============================
def createPlot(inTree):
'显示决策树'
# 创建新的图像并清空 - 无横纵坐标
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
# 树的总宽度 高度
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
# 当前绘制节点的坐标
plotTree.xOff = -0.5/plotTree.totalW;
plotTree.yOff = 1.0;
# 绘制决策树
plotTree(inTree, (0.5,1.0), '')
plt.show()
if __name__ == '__main__':
data,features=load_data()
split_fea_index=choose_best_to_split(data)
newtree=build_decesion_tree(data,features)
print(newtree)
createPlot(newtree)
'''
{'age': {'old_aged': {'level': {'same': 'yes', 'good': 'no'}}, 'teenager': {'student': {'no': 'no', 'yes': 'yes'}}, 'middle_aged': 'yes'}}
'''
结果如下:
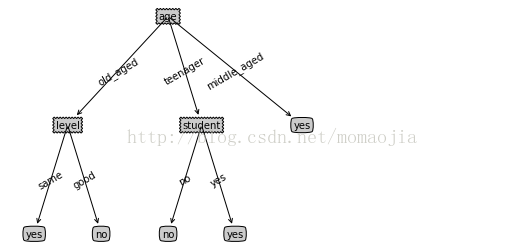
怎么用决策树分类,将会在下一章。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python决策树分类算法学习
从这一章开始进入正式的算法学习. 首先我们学习经典而有效的分类算法:决策树分类算法. 1.决策树算法 决策树用树形结构对样本的属性进行分类,是最直观的分类算法,而且也可以用于回归.不过对于一些特殊的逻辑分类会有困难.典型的如异或(XOR)逻辑,决策树并不擅长解决此类问题. 决策树的构建不是唯一的,遗憾的是最优决策树的构建属于NP问题.因此如何构建一棵好的决策树是研究的重点. J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3算法.后续的C4.5,
-
python实现ID3决策树算法
ID3决策树是以信息增益作为决策标准的一种贪心决策树算法 # -*- coding: utf-8 -*- from numpy import * import math import copy import cPickle as pickle class ID3DTree(object): def __init__(self): # 构造方法 self.tree = {} # 生成树 self.dataSet = [] # 数据集 self.labels = [] # 标签集 # 数据导入函数
-
Python实现决策树并且使用Graphvize可视化的例子
一.什么是决策树(decision tree)--机器学习中的一个重要的分类算法 决策树是一个类似于数据流程图的树结构:其中,每个内部节点表示一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类的分布,树的最顶层是根结点 根据天气情况决定出游与否的案例 二.决策树算法构建 2.1决策树的核心思路 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法). 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集
-
解读python如何实现决策树算法
数据描述 每条数据项储存在列表中,最后一列储存结果 多条数据项形成数据集 data=[[d1,d2,d3...dn,result], [d1,d2,d3...dn,result], . . [d1,d2,d3...dn,result]] 决策树数据结构 class DecisionNode: '''决策树节点 ''' def __init__(self,col=-1,value=None,results=None,tb=None,fb=None): '''初始化决策树节点 args: col -
-
基于Python实现的ID3决策树功能示例
本文实例讲述了基于Python实现的ID3决策树功能.分享给大家供大家参考,具体如下: ID3算法是决策树的一种,它是基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事.ID3算法,即Iterative Dichotomiser 3,迭代二叉树3代,是Ross Quinlan发明的一种决策树算法,这个算法的基础就是上面提到的奥卡姆剃刀原理,越是小型的决策树越优于大的决策树,尽管如此,也不总是生成最小的树型结构,而是一个启发式算法. 如下示例是一个判断海洋生物数据是否是鱼类而构建的基于ID3思想
-
python输出决策树图形的例子
windows10: 1,先要pip安装pydotplus和graphviz: pip install pydotplus pip install graphviz 2,www.graphviz.org下载msi文件并安装. 3,系统环境变量path中增加两项: C:\Program Files (x86)\Graphviz2.38\bin C:\Program Files (x86)\Graphviz2.38 #确认graphviz是安装在上面路径当中. 4,python中使用方法: from
-
python实现C4.5决策树算法
C4.5算法使用信息增益率来代替ID3的信息增益进行特征的选择,克服了信息增益选择特征时偏向于特征值个数较多的不足.信息增益率的定义如下: # -*- coding: utf-8 -*- from numpy import * import math import copy import cPickle as pickle class C45DTree(object): def __init__(self): # 构造方法 self.tree = {} # 生成树 self.dataSet =
-
Python3.0 实现决策树算法的流程
决策树的一般流程 检测数据集中的每个子项是否属于同一个分类 if so return 类标签 Else 寻找划分数据集的最好特征 划分数据集 创建分支 节点 from math import log import operator #生成样本数据集 def createDataSet(): dataSet = [[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no']] labels = ['no surfacing','flipp
-
python实现决策树分类算法
本文实例为大家分享了python实现决策树分类算法的具体代码,供大家参考,具体内容如下 1.概述 决策树(decision tree)--是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用. 2.算法思想 通俗来说,决策树分类的思想类似于找对象.现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26. 女儿:长的帅不帅? 母亲:挺帅的. 女儿:收入高不?
-
python实现决策树分类算法代码示例
目录 前置信息 1.决策树 2.样本数据 策树分类算法 1.构建数据集 2.数据集信息熵 3.信息增益 4.构造决策树 5.实例化构造决策树 6.测试样本分类 后置信息:绘制决策树代码 总结 前置信息 1.决策树 决策树是一种十分常用的分类算法,属于监督学习:也就是给出一批样本,每个样本都有一组属性和一个分类结果.算法通过学习这些样本,得到一个决策树,这个决策树能够对新的数据给出合适的分类 2.样本数据 假设现有用户14名,其个人属性及是否购买某一产品的数据如下: 编号 年龄 收入范围 工作性质
-
python实现决策树分类
上一篇博客主要介绍了决策树的原理,这篇主要介绍他的实现,代码环境python 3.4,实现的是ID3算法,首先为了后面matplotlib的绘图方便,我把原来的中文数据集变成了英文. 原始数据集: 变化后的数据集在程序代码中体现,这就不截图了 构建决策树的代码如下: #coding :utf-8 ''' 2017.6.25 author :Erin function: "decesion tree" ID3 ''' import numpy as np import pandas as
-
python实现决策树分类(2)
在上一篇文章中,我们已经构建了决策树,接下来可以使用它用于实际的数据分类.在执行数据分类时,需要决策时以及标签向量.程序比较测试数据和决策树上的数值,递归执行直到进入叶子节点. 这篇文章主要使用决策树分类器就行分类,数据集采用UCI数据库中的红酒,白酒数据,主要特征包括12个,主要有非挥发性酸,挥发性酸度, 柠檬酸, 残糖含量,氯化物, 游离二氧化硫, 总二氧化硫,密度, pH,硫酸盐,酒精, 质量等特征. 下面是具体代码的实现: #coding :utf-8 ''' 2017.6.26 aut
-
python机器学习之决策树分类详解
决策树分类与上一篇博客k近邻分类的最大的区别就在于,k近邻是没有训练过程的,而决策树是通过对训练数据进行分析,从而构造决策树,通过决策树来对测试数据进行分类,同样是属于监督学习的范畴.决策树的结果类似如下图: 图中方形方框代表叶节点,带圆边的方框代表决策节点,决策节点与叶节点的不同之处就是决策节点还需要通过判断该节点的状态来进一步分类. 那么如何通过训练数据来得到这样的决策树呢? 这里涉及要信息论中一个很重要的信息度量方式,香农熵.通过香农熵可以计算信息增益. 香农熵的计算公式如下: p(xi)
-
Python机器学习应用之决策树分类实例详解
目录 一.数据集 二.实现过程 1 数据特征分析 2 利用决策树模型在二分类上进行训练和预测 3 利用决策树模型在多分类(三分类)上进行训练与预测 三.KEYS 1 构建过程 2 划分选择 3 重要参数 一.数据集 小企鹅数据集,提取码:1234 该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量.共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo).包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
python实现决策树
本文实例为大家分享了python实现决策树的具体代码,供大家参考,具体内容如下 算法优缺点: 优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关的特征数据 缺点:可能会产生过度匹配的问题 适用数据类型:数值型和标称型 算法思想: 1.决策树构造的整体思想: 决策树说白了就好像是if-else结构一样,它的结果就是你要生成这个一个可以从根开始不断判断选择到叶子节点的树,但是呢这里的if-else必然不会是让我们认为去设置的,我们要做的是提供一种方法,计算机可以根据这种方法得
-
python实现决策树、随机森林的简单原理
本文申明:此文为学习记录过程,中间多处引用大师讲义和内容. 一.概念 决策树(Decision Tree)是一种简单但是广泛使用的分类器.通过训练数据构建决策树,可以高效的对未知的数据进行分类.决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析:2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度. 看了一遍概念后,我们先从一个简单的案例开始,如下图我们样本: 对于上面的样本数据,根据不同特征值我们最后是选择是否约会,我们先自定义的一个决策树