Python3 文章标题关键字提取的例子
思路:
1.读取所有文章标题;
2.用“结巴分词”的工具包进行文章标题的词语分割;
3.用“sklearn”的工具包计算Tf-idf(词频-逆文档率);
4.得到满足关键词权重阈值的词
结巴分词详见:结巴分词Github
sklearn详见:文本特征提取——4.2.3.4 Tf-idf项加权
import os
import jieba
import sys
from sklearn.feature_extraction.text import TfidfVectorizer
sys.path.append("../")
jieba.load_userdict('userdictTest.txt')
STOP_WORDS = set((
"基于", "面向", "研究", "系统", "设计", "综述", "应用", "进展", "技术", "框架", "txt"
))
def getFileList(path):
filelist = []
files = os.listdir(path)
for f in files:
if f[0] == '.':
pass
else:
filelist.append(f)
return filelist, path
def fenci(filename, path, segPath):
# 保存分词结果的文件夹
if not os.path.exists(segPath):
os.mkdir(segPath)
seg_list = jieba.cut(filename)
result = []
for seg in seg_list:
seg = ''.join(seg.split())
if len(seg.strip()) >= 2 and seg.lower() not in STOP_WORDS:
result.append(seg)
# 将分词后的结果用空格隔开,保存至本地
f = open(segPath + "/" + filename + "-seg.txt", "w+")
f.write(' '.join(result))
f.close()
def Tfidf(filelist, sFilePath, path, tfidfw):
corpus = []
for ff in filelist:
fname = path + ff
f = open(fname + "-seg.txt", 'r+')
content = f.read()
f.close()
corpus.append(content)
vectorizer = TfidfVectorizer() # 该类实现词向量化和Tf-idf权重计算
tfidf = vectorizer.fit_transform(corpus)
word = vectorizer.get_feature_names()
weight = tfidf.toarray()
if not os.path.exists(sFilePath):
os.mkdir(sFilePath)
for i in range(len(weight)):
print('----------writing all the tf-idf in the ', i, 'file into ', sFilePath + '/', i, ".txt----------")
f = open(sFilePath + "/" + str(i) + ".txt", 'w+')
result = {}
for j in range(len(word)):
if weight[i][j] >= tfidfw:
result[word[j]] = weight[i][j]
resultsort = sorted(result.items(), key=lambda item: item[1], reverse=True)
for z in range(len(resultsort)):
f.write(resultsort[z][0] + " " + str(resultsort[z][1]) + '\r\n')
print(resultsort[z][0] + " " + str(resultsort[z][1]))
f.close()
TfidfVectorizer( ) 类 实现了词向量化和Tf-idf权重的计算
词向量化:vectorizer.fit_transform是将corpus中保存的切分后的单词转为词频矩阵,其过程为先将所有标题切分的单词形成feature特征和列索引,并在dictionary中保存了{‘特征':索引,……},如{‘农业':0,‘大数据':1,……},在csc_matric中为每个标题保存了 (标题下标,特征索引) 词频tf……,然后对dictionary中的单词进行排序重新编号,并对应更改csc_matric中的特征索引,以便形成一个特征向量词频矩阵,接着计算每个feature的idf权重,其计算公式为 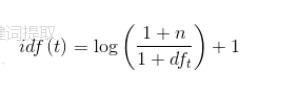 其中是所有文档数量,是包含该单词的文档数。最后计算tf*idf并进行正则化,得到关键词权重。
其中是所有文档数量,是包含该单词的文档数。最后计算tf*idf并进行正则化,得到关键词权重。
以下面六个文章标题为例进行关键词提取

Using jieba on 农业大数据研究与应用进展综述.txt
Using jieba on 基于Hadoop的分布式并行增量爬虫技术研究.txt
Using jieba on 基于RPA的财务共享服务中心账表核对流程优化.txt
Using jieba on 基于大数据的特征趋势统计系统设计.txt
Using jieba on 网络大数据平台异常风险监测系统设计.txt
Using jieba on 面向数据中心的多源异构数据统一访问框架.txt
----------writing all the tf-idf in the 0 file into ./keywords/ 0 .txt----------
农业 0.773262366783
大数据 0.634086202434
----------writing all the tf-idf in the 1 file into ./keywords/ 1 .txt----------
hadoop 0.5
分布式 0.5
并行增量 0.5
爬虫 0.5
----------writing all the tf-idf in the 2 file into ./keywords/ 2 .txt----------
rpa 0.408248290464
优化 0.408248290464
服务中心 0.408248290464
流程 0.408248290464
财务共享 0.408248290464
账表核对 0.408248290464
----------writing all the tf-idf in the 3 file into ./keywords/ 3 .txt----------
特征 0.521823488025
统计 0.521823488025
趋势 0.521823488025
大数据 0.427902724969
----------writing all the tf-idf in the 4 file into ./keywords/ 4 .txt----------
大数据平台 0.4472135955
异常 0.4472135955
监测 0.4472135955
网络 0.4472135955
风险 0.4472135955
----------writing all the tf-idf in the 5 file into ./keywords/ 5 .txt----------
多源异构数据 0.57735026919
数据中心 0.57735026919
统一访问 0.57735026919
以上这篇Python3 文章标题关键字提取的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python实现提取文章摘要的方法
本文实例讲述了Python实现提取文章摘要的方法.分享给大家供大家参考.具体如下: 一.概述 在博客系统的文章列表中,为了更有效地呈现文章内容,从而让读者更有针对性地选择阅读,通常会同时提供文章的标题和摘要. 一篇文章的内容可以是纯文本格式的,但在网络盛行的当今,更多是HTML格式的.无论是哪种格式,摘要 一般都是文章 开头部分 的内容,可以按照指定的 字数 来提取. 二.纯文本摘要 纯文本文档 就是一个长字符串,很容易实现对它的摘要提取: #!/usr/bin/env python # -*-
-
用python3教你任意Html主内容提取功能
本文将和大家分享一些从互联网上爬取语料的经验. 0x1 工具准备 工欲善其事必先利其器,爬取语料的根基便是基于python. 我们基于python3进行开发,主要使用以下几个模块:requests.lxml.json. 简单介绍一个各模块的功能 01|requests requests是一个Python第三方库,处理URL资源特别方便.它的官方文档上写着大大口号:HTTP for Humans(为人类使用HTTP而生).相比python自带的urllib使用体验,笔者认为requests的使用体
-
python提取内容关键词的方法
本文实例讲述了python提取内容关键词的方法.分享给大家供大家参考.具体分析如下: 一个非常高效的提取内容关键词的python代码,这段代码只能用于英文文章内容,中文因为要分词,这段代码就无能为力了,不过要加上分词功能,效果和英文是一样的. 复制代码 代码如下: # coding=UTF-8 import nltk from nltk.corpus import brown # This is a fast and simple noun phrase extractor (based on
-
Python3 文章标题关键字提取的例子
思路: 1.读取所有文章标题: 2.用"结巴分词"的工具包进行文章标题的词语分割: 3.用"sklearn"的工具包计算Tf-idf(词频-逆文档率); 4.得到满足关键词权重阈值的词 结巴分词详见:结巴分词Github sklearn详见:文本特征提取--4.2.3.4 Tf-idf项加权 import os import jieba import sys from sklearn.feature_extraction.text import TfidfVecto
-

Python3实现爬取简书首页文章标题和文章链接的方法【测试可用】
本文实例讲述了Python3实现爬取简书首页文章标题和文章链接的方法.分享给大家供大家参考,具体如下: from urllib import request from bs4 import BeautifulSoup #Beautiful Soup是一个可以从HTML或XML文件中提取结构化数据的Python库 #构造头文件,模拟浏览器访问 url="http://www.jianshu.com" headers = {'User-Agent':'Mozilla/5.0 (Window
-
去掉destoon资讯内容页keywords关键字自带的文章标题的方法
本文实例讲述了去掉destoon资讯内容页keywords关键字自带的文章标题的方法,具体实现方法如下: 在\module\article目录下的article.class.php文件中的大约158行找到: $keyword = $item['title'].','.($item['tag'] ? str_replace(' ', ',', trim($item['tag'])).',' : '').strip_tags(cat_pos(get_cat($item['catid']), ',')
-
Java编程实现提取文章中关键字的方法
本文实例讲述了Java编程实现提取文章中关键字的方法.分享给大家供大家参考,具体如下: 实现代码: /** * 相关的jar包 * lucene-core-3.6.2.jar,lucene-memory-3.6.2.jar, * lucene-highlighter-3.6.2.jar,lucene-analyzers-3.6.2.jar * IKAnalyzer2012.jar * * 截取一片文章中频繁出现的关键字,并给予分组排序(倒叙),以数组格式返回n个关键字 * * 并该类内部含有一个
-
python根据文章标题内容自动生成摘要的实例
text.py title = '智能金融起锚:文因.数库.通联瞄准的kensho革命' text = '''2015年9月13日,39岁的鲍捷乘上从硅谷至北京的飞机,开启了他心中的金融梦想. 鲍捷,人工智能博士后,如今他是文因互联公司创始人兼CEO.和鲍捷一样,越来越多的硅谷以及华尔街的金融和科技人才已经踏上了归国创业征程. 在硅谷和华尔街,已涌现出Alphasense.Kensho等智能金融公司. 如今,这些公司已经成长为独角兽. 大数据.算法驱动的人工智能已经进入到金融领域.人工智能有望在
-
python数据分析:关键字提取方式
TF-IDF TF-IDF(Term Frequencey-Inverse Document Frequency)指词频-逆文档频率,它属于数值统计的范畴.使用TF-IDF,我们能够学习一个词对于数据集中的一个文档的重要性. TF-IDF的概念 TF-IDF有两部分,词频和逆文档频率.首先介绍词频,这个词很直观,词频表示每个词在文档或数据集中出现的频率.等式如下: TF(t)=词t在一篇文档中出现的次数/这篇文档的总词数 第二部分--逆文档频率实际上告诉了我们一个单词对文档的重要性.这是因为当计
-
利用原生JS自动生成文章标题树的实例
实现原理很简单,就是循环文章模块,并抽取其中的h2.h3标签,将其中的内容赋予给新建的title树. 代码如下: HTML代码: <div class="contextBox"> <div id="article"> <h2>二级标题</h2> <h3>三级标题</h3> <p>hello hello hello hello hello hello hello hello hello
-
javascript + jquery实现定时修改文章标题
用javascript+jquery写的一个定时器,定时修改文章标题. 复制代码 代码如下: <!DOCTYPE html> <html> <head> <title>TODO supply a title</title> <meta charset="GB2312"> <meta name="viewport" content="width=device-width"
-
Python3 chardet模块查看编码格式的例子
如下所示: 需要注意的是,如果遇到GBK2312等编码的,在decode和encode时,一律使用GBK进行编码或者解码,这是因为GBK是其他GBK编码的超集,向下兼容所有的GBK编码. 下面是一个例子: #coding=utf-8 import urllib.request import chardet url = 'http://www.baidu.com' a = urllib.request.urlopen(url) ''' chardet模块 使用该模块可以查看字符串的编码格式:cha
-
python3调用windows dos命令的例子
最近游戏项目在多个国家上线,每个国家都对应两份儿svn目录(一份是本地策划目录,一份是线上目录).于是乎维护变得很烦躁.需要先更新本地策划svn目录,然后把更新的文件拷贝到对应的线上目录,然后提交线上svn目录,然后维护服务器.多个国家就要重复多次类似的更新,拷贝,提交的操作,还要格外注意不能手抖,出现少复制的错误.这种重复的操作很适合写一个工具来完成. 于是考虑使用python来写这个工具,最基本的操作就是使用python调用svn命令.因为windows安装svn后是没有svn命令行的,所以