python遍历文件目录、批量处理同类文件
本文实例为大家分享了python遍历文件目录、批量处理同类文件的具体代码,供大家参考,具体内容如下
目录操作
1、获取当前目录
import os curr_path=os.path.dirname(__file__) #返回当前文件所在的目录,即当前运行的脚本所在父目录 print curr_path
运行示例

(1)使用os.path.dirname(__file__)时,是针对运行时对所给程序脚本的路径来获取父目录的,即截取你输入的脚本路径的所在目录名称,如上图示例,输入绝对路径时返回绝对路径,输入相对路径时返回相对路径,如果只输入了脚本名称,则返回空。
(注:当从命令行中进入python环境时时,参数__file__不能使用)
(2)当直接使用os.path.dirname(“/home/test_MK/test.py”)时,直接返回“/home/test_MK”
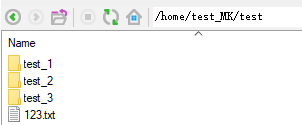
2、获取目录文件列表
file_list=os.listdir("/home/test_MK/test"))
print file_list
运行示例

3、获取该目录下文件夹或者文件列表
path="/home/test_MK/test" objects=os.listdir(path) dir_list=[] #存放目录列表 file_list=[] #存放文件列表 for obj in objects: if os.path.isdir(os.path.join(path, obj)):#判断是否是目录os.path.join()用来将路径拼接 dir_list.append(os.path.join(path, obj))#保存时保存完整路径才能对其进行后续操作 print "dir:",obj else: file_list.append(os.path.join(path, obj)) print "file:",obj print "目录列表:",dir_list print "文件列表:",file_list #如果项判断是否是文件时用os.isfile()
(注:使用os.isdir()与os.isfile()时,参数必须是一个相对路径或者绝对路径,不能光是一个文件名或者目录名称,这也是上面示例代码中使用os.path.join()的原因,否则函数将判断不出正确结果)
运行示例

批量处理目录下同类文件
以处理pcap文件为例
1、获取某一文件夹下所有pcap包路径,过滤掉其它文件
def getPathFile(path):
'''
name:getPathFile
function:获取所给文件夹下所有pcap文件路径
path:所给文件夹路径
'''
Path = []
try:
pathDir = os.listdir(path)
for allDir in pathDir:
child = os.path.join('%s/%s' % (path, allDir))
#跳过文件夹以及非流量包文件,将后缀名改为自己需要的文件类型即可实现自己的过滤
if os.path.isfile(child) and (".pcap" in str(allDir) or (".cap" in str(allDir))):
Path.append(child)
except:
pass
return Path
2、处理函数,打印一个pcap文件中所有数据包的五元组信息{src_ip,src_port,dst_ip,dst_port}
def print_pack_f(file_path): ''' name:print_pack_f function:打印一个pcap文件中所有数据包的五元组信息 file_path:所给pcap文件路径 ''' file_p= open(file_path) pcap = dpkt.pcap.Reader(file_p) if not pcap: return print "\n\n*******file:%s*******\n"% file_path for (ts,buf) in pcap: try: eth = dpkt.ethernet.Ethernet(buf) #解包,物理层 if not isinstance(eth.data, dpkt.ip.IP): #解包,网络层 continue ip = eth.data src_ip="%d.%d.%d.%d"%tuple(map(ord,list(ip.src))) dst_ip="%d.%d.%d.%d"%tuple(map(ord,list(ip.dst))) if (not isinstance(ip.data, dpkt.tcp.TCP)) and (not isinstance(ip.data, dpkt.udp.UDP)): #解包,传输层 continue transf= ip.data print "<",src_ip,":",transf.sport,"-->",dst_ip,":",transf.dport,">" except Exception,err: print "[error] %s" % err
3、调用示例
def main(dir_path): all_file_path=getPathFile(dir_path) #获取目录下所有pcap文件路径 for file in all_file_path: #遍历处理 print_pack_f(file) #单个pcap文件处理,可将本函数替换成自定义的功能,便可实现批量处理 if __name__ == '__main__': opts,args = getopt.getopt(sys.argv[1:], "hi:") #从命令行获取参数 if not opts: #若没有带参数 print "\n\ *******************\n\ warn! please enter related parameters,enter -h for help!\n\n\ *******************\n" sys.exit() input_path='' for op, value in opts: if op == "-i": input_path = value elif op == "-h": usage() #帮助信息,只是简单的一个输出函数,输出内容自定义 sys.exit() main(input_path)
结果展示
测试目录如下
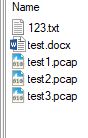
运行结果(python test.py -i ./test)

完毕
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python中遍历文件的3个方法
今天写一个在windows下批量修改文件名的python脚本,用到文件的遍历.用python进行文件遍历有多种方法,这里列举并说明一下. os.path.walk() 这是一个传统的用法. walk(root,callable,args)方法有三个参数:要遍历的目录,回调函数,回调函数的参数(元组形式). 调用的过程是遍历目录下的文件或目录,每遍历一个目录,调用回调函数,并把args作为参数传递给回调函数. 回调函数定义时也有三个参数,比如示例中的func中的三个参数,分别为walk传来的参数.
-
Python实现递归遍历文件夹并删除文件
思路: 遍历文件夹下面的文件夹 如果文件夹名称等于".svn",则修改文件夹的属性(因为".svn"的文件都是只读的,你不能直接删除) 删除此文件夹 如果文件夹名称不等于".svn",则递归上面的方法 Python的实现 代码 import os import shutil import os.path import stat rootdir="F:\\work\\Test" for parent,dirnames,filen
-
python遍历文件夹并删除特定格式文件的示例
复制代码 代码如下: #!/usr/bin/python# -*- coding: utf-8 -*- import os def del_files(path): for root , dirs, files in os.walk(path): for name in files: if name.endswith(".tmp"): os.remove(os.path.join(root, name)) pri
-
Python与C++ 遍历文件夹下的所有图片实现代码
Pyhton与C++ 遍历文件夹下的所有图片实现代码 前言 虽然本文说的是遍历图片,但是遍历其他文件也是可以的. 在进行图像处理的时候,大部分时候只需要处理单张图片.但是一旦把图像处理和机器学习相结合,或者做一些稍大一些的任务的时候,常常需要处理好多图片.而这里面,一个最基本的问题就是如何遍历这些图片. 用OpenCV做过人脸识别的人应该知道,那个项目中并没有进行图片的遍历,而是用了一种辅助方案,生成了一个包含所有图片路径的文件at.txt,然后通过这个路径来读取所有图片.而且这个辅助文件不仅
-
对python遍历文件夹中的所有jpg文件的实例详解
python发现文件夹下所有的jpg文件,并且安装文件排放的顺序输出 glob模块是最简单的模块之一,内容非常少.用它可以查找符合特定规则的文件路径名.跟使用windows下的文件搜索差不多.查找文件只用到三个匹配符:"*", "?", "[]"."*"匹配0个或多个字符:"?"匹配单个字符:"[]"匹配指定范围内的字符,如:[0-9]匹配数字. glob.glob 返回所有匹配的文件路
-

Python遍历文件夹和读写文件的实现方法
需 求 分 析 1.读取指定目录下的所有文件 2.读取指定文件,输出文件内容 3.创建一个文件并保存到指定目录 实 现 过 程 Python写代码简洁高效,实现以上功能仅用了40行左右的代码~ 昨天用Java写了一个写入.创建.复制.重命名文件要将近60行代码: 不过简洁的代价是牺牲了一点点运行速度,但随着硬件性能的提升,运行速度的差异会越来越小,直到人类无法察觉~ #-*- coding: UTF-8 -*- ''' 1.读取指定目录下的所有文件 2.读取指定文件,输出文件内容 3.创建一个文
-
python使用os模块的os.walk遍历文件夹示例
复制代码 代码如下: #-*- coding:utf-8 -*- import os if __name__ == '__main__': try: '''traval and list all files and all dirs''' for root, dirs, files in os.walk('D:' + os.sep + 'Python27'): print '-------------------directory < ' + root + '
-
python遍历文件夹下所有excel文件
大数据处理经常要用到一堆表格,然后需要把数据导入一个list中进行各种算法分析,简单讲一下自己的做法: 1.如何读取excel文件 网上的版本很多,在xlrd模块基础上,找到一些源码: import xdrlib ,sys import xlrd def open_excel(file="C:/Users/flyminer/Desktop/新建 Microsoft Excel 工作表.xlsx"): data = xlrd.open_workbook(file) return data
-
python目录操作之python遍历文件夹后将结果存储为xml
Linux服务器有CentOS.Fedora等,都预先安装了Python,版本从2.4到2.5不等,而Windows类型的服务器也多数安装了Python,因此只要在本机写好一个脚本,上传到对应机器,在运行时修改参数即可. Python操作文件和文件夹使用的是os库,下面的代码中主要用到了几个函数: os.listdir:列出目录下的文件和文件夹os.path.join:拼接得到一个文件/文件夹的全路径os.path.isfile:判断是否是文件os.path.splitext:从名称中取出一个子
-
python遍历文件夹,指定遍历深度与忽略目录的方法
背景 需要在文件夹中搜索某一文件,找到后返回此文件所在目录.用最常规的os.listdir()方式实现了一版,但执行时报错:递归超过最大深度.于是自己添加了点功能,之所有写此函数是为了让它适应不同的项目,因为有项目要找的文件在第一层,有的在第二层. 函数 功能:在文件夹中查找某一文件,找到后返回True与文件所在目录路径. 参数:filepath, 要查找的目录 参数:filename, 要查找的文件 扩展1:find_depth, 查找时指定递归深度: 扩展2:ignore_path, 查找时