解决Python3中的中文字符编码的问题
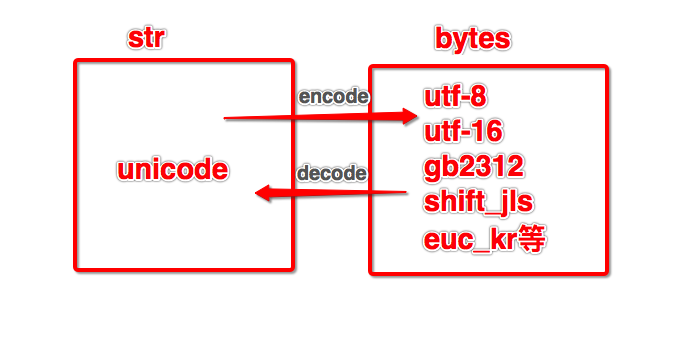
python3中str默认为Unicode的编码格式
Unicode是一32位编码格式,不适合用来传输和存储,所以必须转换成utf-8,gbk等等
所以在Python3中必须将str类型转换成bytes类型的
在Python中使用encode的方式可以进行字符的编码
实际用法:
>>>a = "中国"
>>> a.encode("utf-8")
b'\xe4\xb8\xad\xe5\x9b\xbd'
>>> a.encode("gbk")
b'\xd6\xd0\xb9\xfa'

总结:
- Python中str类型转bytes类型,相当与Unicode转gbk,utf-8。。。类型
- b'代表字符编码格式为bytes,
- utf-8默认24位占3个8位16进制数
- gbk中国编码默认占16位2个8位16进制数字
以上所述是小编给大家介绍的解决Python3中的中文字符编码的问题,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
解决python写入带有中文的字符到文件错误的问题
在python写脚本过程中需要将带有中文的字符串内容写入文件,出现了报错的现象. ---------------------------- UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) ---------------------------- 经过网上搜索出错原因得到结果: python中如果使用系统默认的open方法打开的文件只能写入asc
-

完美解决Python2操作中文名文件乱码的问题
Python2默认是不支持中文的,一般我们在程序的开头加上#-*-coding:utf-8-*-来解决这个问题,但是在我用open()方法打开文件时,中文名字却显示成了乱码. 我先给大家说说Python中的编码问题,Python中的字符串的大概分为为str和Unicode两种形式,其中str常用的编码类型为utf-8,gb2312,gbk等等,Python使用Unicode作为编码的基础类型.str记录的是字节数组,只是某种编码的存储格式,终于输出到文件或是打印出来是什么格式,完全取决于其解码的
-
python中文编码与json中文输出问题详解
前言 python2.x版本的字符编码有时让人很头疼,遇到问题,网上方法可以解决错误,但对原理还是一知半解,本文主要介绍 python 中字符串处理的原理,附带解决 json 文件输出时,显示中文而非 unicode 问题.首先简要介绍字符串编码的历史,其次,讲解 python 对于字符串的处理,及编码的检测与转换,最后,介绍 python 爬虫采取的 json 数据存入文件时中文输出的问题. 参考书籍:Python网络爬虫从入门到实践 by唐松 在python 2或者3 ,字符串编码只有两类
-
Python之pandas读写文件乱码的解决方法
python读写文件有时候会出现 'XXX'编码不能打开XXX什么的,用记事本打开要读取的文件,另存为UTF-8编码,然后再用py去读应该可以了.如果还不行,那么尝试使用文件原有的编码方式读取,参考之前的文章 在pandas中读写csv时候通过制定encoding可以有效防止excel打开或者写入中文乱码 data.to_csv(f_out,index=False,encoding='gb2312') 以上这篇Python之pandas读写文件乱码的解决方法就是小编分享给大家的全部内容了,希
-
在Python中关于中文编码问题的处理建议
字符串是Python中最常用的数据类型,而且很多时候你会用到一些不属于标准ASCII字符集的字符,这时候代码就很可能抛出UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 10: ordinal not in range(128)异常.这种异常在Python中很容易遇到,尤其是在Python2.x中,是一个很让初学者费解头疼的问题.不过,如果你理解了Python的Unicode,并在编码中遵循一定的原则,这种编
-
解决python使用open打开文件中文乱码的问题
代码如下: 先在D盘下新建一个html文档,然后在里面输入含有中文的Html字符如下图,然后我们首先使用中文格式对读取的字符进行解码再用utf-8的模式对字符进行进行编码,然后就能正确输出中文字符 # -*- coding: UTF-8 -*- file1 = open("D:/1.html", mode='rb+') data = file1.read().decode('gbk').encode('utf-8') print data 以上这篇解决python使用open打开文件中
-
python写入中英文字符串到文件的方法
本文实例讲述了python写入中英文字符串到文件的方法.分享给大家供大家参考.具体分析如下: python中如果使用系统默认的open方法打开的文件只能写入ascii吗,如果要写入中文需要用到codecs模块,下面的代码向 c:/1.txt文件写入 "你好,我们 jb51.net"中文字符串 # -*- coding: utf-8 -*- import codecs content = u'你好,我们 jb51.net' f = codecs.open('c:/1.txt','w','
-
解决Python下json.loads()中文字符出错的问题
Python:2.7 IDE:Pycharm5.0.3 今天遇到一个问题,就是在使用json.load()时,中文字符被转化为Unicode码的问题,解决方案找了半天,无解.全部代码贴出,很简单的一个入门程序,抓的是有道翻译的,跟着小甲鱼的视频做的,但是他的版本是python3.4,所以有些地方还需要自己改,不多说,程序如下: import urllib#python2.7才需要两个urllib url="http://fanyi.youdao.com/translate?smartresult
-
解决Python3中的中文字符编码的问题
python3中str默认为Unicode的编码格式 Unicode是一32位编码格式,不适合用来传输和存储,所以必须转换成utf-8,gbk等等 所以在Python3中必须将str类型转换成bytes类型的 在Python中使用encode的方式可以进行字符的编码 实际用法: >>>a = "中国" >>> a.encode("utf-8") b'\xe4\xb8\xad\xe5\x9b\xbd' >>> a.
-
解决python3 中的np.load编码问题
由于在Python2 中的默认编码为ASCII,但是在Python3中的默认编码为UTF-8. 问题: 所以在使用np.load(det.npy)的时候会出现错误提示: you may need to pass the encoding= option to numpy.load 解决方法: 当遇到这种情况的时候,用np.load(det.npy,encoding="latin1")就可以了. 补充:python解决numpy导入乱码问题------已解决 使用numpy的loadtx
-
解决python3中的requests解析中文页面出现乱码问题
第一部分 关于requests库 (1) requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到. (2) 其中的Request对象在访问服务器后会返回一个Response对象,这个对象将返回的Http响应字节码保存到content属性中. (3) 但是如果你访问另一个属性text时,会返回一个unicode对象,乱码问题就会常常发成在这里. (4) 因为Response对象会通过另一个属性encoding来将字节码编码成unicode,而这个en
-
解决python3中cv2读取中文路径的问题
如下所示: python3: img_path = ' ' im = cv2.imdecode(np.fromfile(img_path,dtype = np.uint8),-1) save_path = ' ' cv2.imencode('.jpg',im)[1].tofile(save_path) python2.7: img_path = ' ' im = cv2.imread(img_path.decode('utf-8')) 以上这篇解决python3中cv2读取中文路径的问题就是
-
解决django 向mysql中写入中文字符出错的问题
之前使用django+mysql建立的一个站点,发现向数据库中写入中文字符时总会报错,尝试了修改settings文件和更改数据表的字符集后仍不起作用.最后发现,在更改mysql的字符集后,需要重建数据库,才能起作用. 这里完整记录一下解决方案 首先更改mysql的字符集 ubuntu下找到/etc/mysql/my.cnf 在最后添加 [mysqld] character-set-server=utf8 [client] default-character-set=utf8 [mysql]
-
解决python3中os.popen()出错的问题
使用程序难免会有出错的时候,如何从大篇代码中找出错误,不仅考验能力,还要考验小伙们的耐心.辛辛苦苦敲出的代码运行不出结果,非常着急是可以理解的.那么我们在python3中使用os.popen()出错该怎么办?本篇文章小编同样以错误的操作方法为大家进行讲解,一起找寻不对的地方吧. 在当前 desktop 目录下,有如下内容: desktop $ls client.py server.py 中文测试 arcpy.txt codetest.py test.py 如上所示:有一个中文命名的文件 ----
-
解决python3中解压zip文件是文件名乱码的问题
在zip标准中,对文件名的 encoding 用的不是 unicode,而可能是各种软件根据系统的默认字符集来采用(此为猜测),因此zipfile中根据文件 flag 检测的时候,只支持 cp437 和 utf-8. 具体就是查找 zipfile.py 源代码找到下面的代码: 1: if flags & 0x800: 2: # UTF-8 file names extension 3: filename = filename.decode('utf-8') 4: else: 5: # Histo
-
解决python3 HTMLTestRunner测试报告中文乱码的问题
使用HTMLTestRunner输出的测试报告中,标题和错误说明的中文乱码. 环境: python v3.6 HTMLTestRunner v0.8.2 定位问题 刚开始以为是python3对HTMLTestRunner文件兼容的问题.网上搜了一些解决办法基本都是说python2的,对比看了一下,我这边兼容性是可以的. 接下来,查看HTMLTestRunner文件输出,倒着去找,最后问题定位到: self.stream.write(output) 这一行,print(output)是正常输出中文
-
解决git 提交后中文字符会乱码的问题
最近发生那了一件怪事,当然菜鸡经常碰见怪事 本来一个.properties文件在idea里面commit的时候看了一下diff,没发现异常,但是提交到gitlab上发现.properties的所有中文字符都变成了 \xxxx 的ascii的编码. 然后我在idea的show history中查看和上一版本的差异,发现这些中文字符没问题??!! 然后就是一顿的百度,bing 最后发现设置里面 transparent native-to-ascii conversion是选中的 然后网上有人这样解释
-
PHP中实现中文字符进制转换原理分析
一,中文字符转十进制原理分析 GBK编码中一个汉字由二个字符组成,获取汉字字符串的方法如下 复制代码 代码如下: $string = "不要迷恋哥"; $length = strlen($string); for($i=0;$i<$length;$i++){ if(ord($string[$i])>127){ $result[] = ord($string[$i]).' '.ord($string[++$i]); } } var_dump($result); 由于一个汉字为