Linux内核如何输出中文字符的方法示例
你在Windows/MacOS的登录Linux的SSH终端上很容易输入中文并且获得中文输出,比如下面这样:
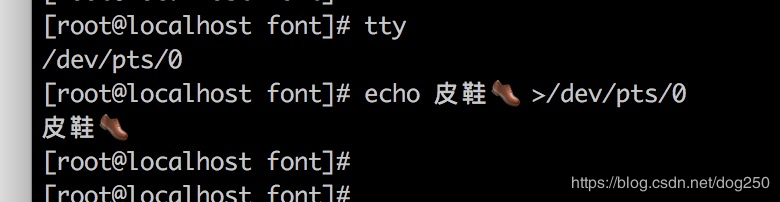
但是却几乎不可能将中文显示在Linux自身的 虚拟终端 上:
[root@localhost font]# echo 皮鞋 >/dev/tty2

显示了两个问号,显然Linux内核并不能识别中文。
为什么说是Linux内核不能识别中文呢?这里需要理清一个关系:
- 你在远程SSH终端上的输入和显示输出的行为,都是SSH终端的宿主机完成的,比如Windows,MacOS,和Linux无关。
- 你在Linux本地虚拟终端,比如/dev/tty1上的输入和显示输出行为,则是由Linux内核自己处理的。
比如,我在MacOS用iTerm SSH连接到了一个远程CentOS Linux,iTerm上的所有的键盘输入,显示器输出行为都是iTerm的这台MacOS宿主机完成的。
相反,如果你直接在这台CentOS Linux的虚拟终端上输入并且企图获得输出,那么这个输入输出则必须由Linux内核自身来处理。
基本上就这些。至于说为什么Linux内核不支持中文,那要了解Linux内核处理虚拟终端输入输出时是如何对待unicode的逻辑,这要涉及一大堆的理论知识,非常烦人。
反正我这里就是无法输出中文,我也不是做这个的,显然这不是一个必然要完成的工作任务,所以,我只是玩玩。
本文的目标就是要让Linux的虚拟终端可以输出中文。
仅仅是输出中文,哪怕是一个中文汉字也好。具体来讲,就是 当我在键盘敲入'A'字符时,显示器回显出来的是一个汉字。
所以说,本文并不打算 让Linux内核大规模完备地支持中文 ,这种事已经有很多人和社区做了,但是可玩性并不高,毕竟这种事是可以当私活儿赚钱的,只要是赚钱的活儿,可玩性就不高,因为要快嘛。
不需要懂冗长枯燥的unicode编码,不需要懂枯燥的font字体格式,看看怎么玩。
先展示效果吧,下面是一个8×168\times 168×16的点阵例子:
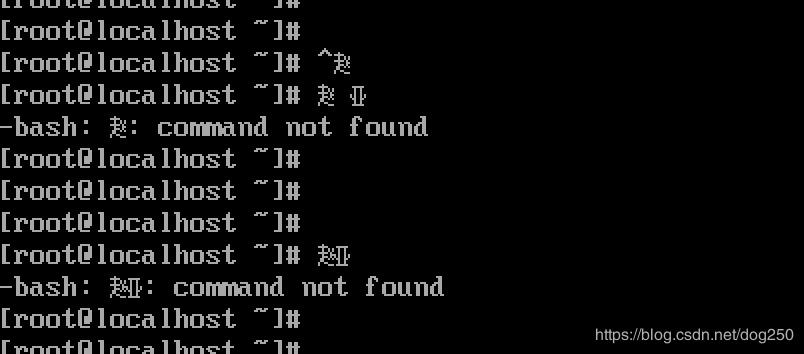
不是很好看,于是就做了下面一个28×1628\times 1628×16的点阵:
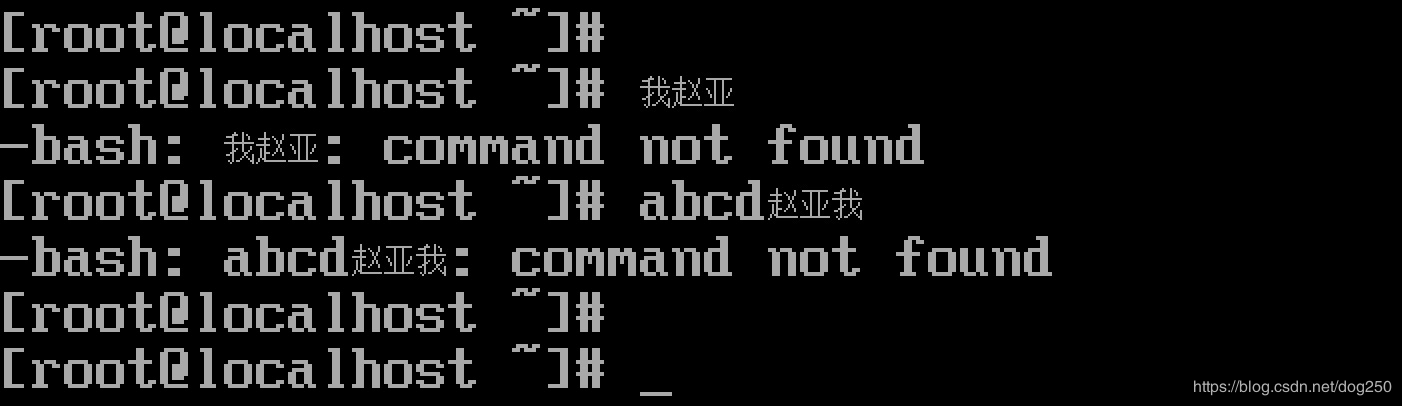
下面说一下这是如何实现的。
从你敲键盘的某个按键开始,到某个字符最终显示在虚拟终端的显示器上,这期间其实有两个映射:
键盘和字符集的映射
将某个按键事件转换为某个字符集里的某个码,比如当按下'A'键时,将其映射到0x41。
字符集和字体的映射
将某个字符集的码字映射到某个点阵用来显示。比如将0x41映射到能让人看出来是一个字符'A'的样子的8×168\times 168×16点阵。
Linux的console并不能识别超过0x00ff的字符集码字,因此就不能处理码字超过0x00ff的unicode,如果希望它能做到,这就要改内核代码了。
刚才说了,修改内核代码大规模全面支持中文,这是可以赚钱的事,不但没意思,也没人会分享。
所以我尝试去修改上面的两个映射来解决问题。由于只是显示,所以我不会去修改 键盘和字符集的映射 ,因为那样仍然会碰到字符集码字超过0x00ff的处理问题。
这意味着要想显示中文,只剩下一条路,那就是修改 字符集和字体的映射 !
这个映射肯定是保存在内核内存或者文件系统的某个地方。我可以在当前内核的config文件里找到如下的信息:
[root@localhost font]# cat /boot/config-3.10.0-862.11.6.el7.x86_64 |grep FONT # CONFIG_FONTS is not set CONFIG_FONT_8x8=y CONFIG_FONT_8x16=y
再去看/proc/kallsyms里有什么:
[root@localhost font]# cat /proc/kallsyms |grep font.*8x ffffffffb006a3e0 R font_vga_8x8 ffffffffb006a420 r fontdata_8x8 ffffffffb006ac20 R font_vga_8x16 ffffffffb006ac60 r fontdata_8x16 ffffffffb0307a10 r __ksymtab_font_vga_8x16 ffffffffb03234b8 r __kcrctab_font_vga_8x16 ffffffffb034246e r __kstrtab_font_vga_8x16
嗯,这就是内核里保存的字体:
[root@localhost rh]# ll ./drivers/video/console/font_8x* -rw-r--r--. 1 root root 95976 Sep 17 2018 ./drivers/video/console/font_8x16.c -rw-r--r--. 1 root root 50858 Sep 17 2018 ./drivers/video/console/font_8x8.c
这里不再分析这两个文件。这里仅仅是确认了一个事实, 内核在初始化的时候会使用自己的字体 ,这个时候毕竟除了内核本身,什么都没有。
问题是到了用户态,这个字体是可以被改变的,可以被改的花里胡哨的,这些个字体可不是仅仅两个8x8和8x16就能hold住的…
这个时候就需要找我们安装在发行版里面的字体文件了。我们要找到它,然后改掉里面的某个字体的形状,将其变成中文!就这么简单。
不必去搜这个字体文件安装保存在什么地方,通过执行strace setfont命令就能找到它。
[root@localhost ~]# strace -F -e trace=open setfont
...
strace: Process 6276 attached
[pid 6276] open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 4
...
[pid 6276] open("/lib/kbd/consolefonts/default8x16.psfu.gz", O_RDONLY|O_NOCTTY|O_NONBLOCK) = 4
[pid 6276] +++ exited with 0 +++
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=6276, si_uid=0, si_status=0, si_utime=0, si_stime=0} ---
+++ exited with 0 +++
就是它了, /lib/kbd/consolefonts/default8x16.psfu.gz
也不必去搜psfu格式的字体的format,通过模式识别就能找到特定的字符。
我准备先找到 ‘A',然后把它后面的'B'和'C'改成我的名字“赵”和“亚”。
首先我要把“赵”和“亚”字做出来,形成一个点阵。以下是我的作品“赵”:
00000000 00000000 00100000 11111000 00100101 00100101 11111010 00100011 00111010 01100101 01100000 10011000 10000111 00000000 00000000 00000000

下面就要用这个点阵替换'B'的点阵,同时制作一个“亚”字,替换'C'的点阵,
在下面的站点可以找到该default font的对应点阵图解:
https://www.zap.org.au/software/fonts/console-fonts-distributed/psftx-centos-7.5/default8x16.psfu.large.pdf

我们就可以得到该'A'字符的点阵数组,然后在default8x16.psfu文件里匹配这个数组就可以了。代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <linux/fb.h>
#include <string.h>
unsigned char zhaoya[32] = {
// 第一行为“赵”
0x00, 0x00, 0x20, 0xf8, 0x25, 0x25, 0xfa, 0x23, 0x3a, 0x65, 0x60, 0x98, 0x87, 0x00, 0x00, 0x00,
// 第二行为亚
0x00, 0x00, 0x00, 0x7e, 0x24, 0x24, 0x24, 0xa5, 0xa5, 0x66, 0x24, 0x24, 0x7e, 0x00, 0x00, 0x00
};
int main(int argc, char **argv)
{
int i = 0;
unsigned char buf[16];
off_t offset = 0;
int s = 0;
int fd = open("default8x16.psfu", O_RDWR);
i = pread(fd, buf, 8, offset);
while (1) {
i = pread(fd, buf, 16, offset);
if (s == 2) { // 替换'C'
memcpy (buf, &zhaoya[16], 16);
i = pwrite(fd, buf, 16, offset);
break;
}
if (s == 1) { // 替换'B'
memcpy (buf, &zhaoya[0], 16);
pwrite(fd, buf, 16, offset);
s = 2;
}
// 简易的方法识别到'A'
if (buf[0] == 0x00 && buf[1] == 0x00 &&
buf[2] == 0x10 && buf[3] == 0x38) {
printf("A found at %d !\n", offset);
s = 1;
}
offset += 16;
}
}
直接编译执行,然后将这个default8x16.psfu作为参数set到内核即可:
[root@localhost font]# setfont ./default8x16.psfu
此时进入Linux的虚拟终端tty2,当敲键盘的大写'B'时,就会出现一个“赵”字。
虽然16×816\times 816×8甚至8×88\times 88×8也能做出复杂的中文点阵,但是这也太难看了。
于是我要找一个更高分辨率的font。我在Ubuntu上找到了一个高分辨率的28×1628\times 1628×16点阵 Arabic-VGA28x16.psf.gz 。修改它的方法和前面这个完全一样,它的点阵图如下:
https://www.zap.org.au/software/fonts/console-fonts-distributed/psftx-debian-9.4/Lat7-VGA28x16.psf.pdf
我不需要自己做28×1628\times 1628×16的点阵了,我只要用GNU uifont的现成的即可。直接在 unifont_sample-12.1.01.hex 里面按照“赵”和“亚”的unicode码字就能索引到点阵。关于任意字符的unicode码字的查询,可以参见:
https://graphemica.com/
替换font的代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <string.h>
#include "zhao"
#define L 28*2
int fd;
int main(int argc, char **argv)
{
unsigned char buf[L];
off_t offset = 0;
// 这个0x0e60 就是模式匹配获得的偏移。
offset += 0x0e60;
fd = open("Lat7-VGA28x16.psf", O_RDWR);
pread(fd, buf, L, offset);
memset(buf, 0, L);
memcpy(buf+8, &code[0], 32);
pwrite(fd, buf, L, offset);
offset += L;
pread(fd, buf, L, offset);
memset(buf, 0, L);
memcpy(buf+8, &code[32], 32);
pwrite(fd, buf, L, offset);
offset += L;
pread(fd, buf, L, offset);
memset(buf, 0, L);
memcpy(buf+8, &code[64], 32);
pwrite(fd, buf, L, offset);
}
然后它的效果就是:

还不错。
其实本文的内容仅仅就是:
- 做一个蹩脚的点阵;
- keyboard,ascii/unicode,font之间的映射关系;
- 什么细节都不懂的情况下定位分析问题的方法;
- 越简单越好,越复杂越糟糕。
嗯,其实第三点和第四点是最重要的。
最后,如果你想知道你当前的虚拟终端支持那些字体,输入:
[root@localhost font]# showconsolefont
就会显示:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Linux内核启动参数详解
1.环境: Ubuntu 16.04 Linux linuxidc 4.4.0-89-generic #112-Ubuntu SMP Mon Jul 31 19:38:41 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux 2.查看当前linux内核的启动参数: cat /proc/cmdline 笔者的输出内容如下: BOOT_IMAGE=/boot/vmlinuz-4.4.0-89-generic root=UUID=bef418fa-4202-4513-b39
-
Linux内核链表实现过程
关于双链表实现,一般教科书上定义一个双向链表节点的方法如下: 复制代码 代码如下: struct list_node{stuct list_node *pre;stuct list_node *next;ElemType data; } 即一个链表节点包含:一个指向前向节点的指针.一个指向后续节点的指针,以及数据域共三部分.但查看linux内核代码中的list实现时,会发现其与教科书上的方法有很大的差别.来看看linux是如何实现双链表.双链表节点定义 复制代码 代码如下: struct lis
-

Linux内核中红黑树算法的实现详解
一.简介 平衡二叉树(BalancedBinary Tree或Height-Balanced Tree) 又称AVL树.它或者是一棵空树,或者是具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1.若将二叉树上结点的平衡因子BF(BalanceFactor)定义为该结点的左子树的深度减去它的右子树的深度,则平衡二叉树上所有结点的平衡因子只可能是-1.0和1.(此段定义来自严蔚敏的<数据结构(C语言版)>) 红黑树 R-B Tree,全称是Red-B
-
Linux内核参数调整方法
ulimit设置 ulimit -n 要调整为100000甚至更大. 命令行下执行 ulimit -n 100000即可修改.如果不能修改,需要设置 /etc/security/limits.conf,加入 * soft nofile 262140 * hard nofile 262140 root soft nofile 262140 root hard nofile 262140 * soft core unlimited * hard core unlimited root soft co
-
简单谈谈Linux内核定时器
软件意义上的定时器最终依赖硬件定时器来实现, 内核在时钟中断发生后检测各定时器是否到期 , 到期后的定时器处理函数将作为软中断在底半部执行 .实质上,时钟中断处理程序会 换起TIMER_SOFTIRQ软中断 ,运行当前处理器上到期的所有定时器. 总结起来还是软中断的流程 a.注册软中断处理函数 /*/linux/kernel.timer.c*/ void __init init_timers(void) -->open_softirq(TIMER_SOFTIRQ, run_timer_softi
-
Linux内核模块和驱动的编写
Linux内核是一个整体是结构,因此向内核添加任何东西,或者删除某些功能,都十分困难.为了解决这个问题引入了内核机制.从而可以动态的想内核中添加或者删除模块. 模块不被编译在内核中,因而控制了内核的大小.然而模块一旦被插入内核,他就和内核其他部分一样.这样一来就会曾家一部分系统开销.同时,如果模块出现问题,也许会带来系统的崩溃. 模块的实现机制: 启动时,由函数 void inti_modules() 来初始化模块,因为启动事很多时候没有模块.这个函数往往把内核自身当作一个虚模块. 如由系统需要
-
浅谈Linux内核创建新进程的全过程
进程描述 进程描述符(task_struct) 用来描述进程的数据结构,可以理解为进程的属性.比如进程的状态.进程的标识(PID)等,都被封装在了进程描述符这个数据结构中,该数据结构被定义为task_struct 进程控制块(PCB) 是操作系统核心中一种数据结构,主要表示进程状态. 进程状态 fork() fork()在父.子进程各返回一次.在父进程中返回子进程的 pid,在子进程中返回0. fork一个子进程的代码 #include <stdio.h> #include <stdli
-
Linux操作系统内核编译详解
内核简介 内核,是一个操作系统的核心.它负责管理系统的进程.内存.设备驱动程序.文件和网络系统,决定着系统的性能和稳定性. Linux的一个重要的特点就是其源代码的公开性,所有的内核源程序都可以在/usr/src/linux下找到,大部分应用软件也都是遵循GPL而设计的,你都可以获取相应的源程序代码.全世界任何一个软件工程师都可以将自己认为优秀的代码加入到其中,由此引发的一个明显的好处就是Linux修补漏洞的快速以及对最新软件技术的利用.而Linux的内核则是这些特点的最直接的代表.
-
一张图看尽Linux内核运行原理
众所周知的是,几乎整个互联网都运行在 Linux 上,从网络协议,到服务器,到你平常访问的绝大多数网站,都能看到它的身影.Linux 内核就是最复杂最流行的开源项目之一.如果你希望学习内核知识,在网上可以搜到无数的资料,但是 Linux 内核还是一个非常难弄明白的项目. 俗话说:一图胜千言,今天我们就为大家介绍一张完整的 Linux 内核运行原理图,通过这张图,你可以很方便地学习内核知识. 在 Linux 内核中,有许多层次.模块.功能调用和函数:要把其中的每一块儿都弄明白很不容易,不过 Mak
-
Linux 内核空间与用户空间实现与分析
本文以 32 位系统为例介绍内核空间(kernel space)和用户空间(user space). 内核空间和用户空间 对 32 位操作系统而言,它的寻址空间(虚拟地址空间,或叫线性地址空间)为 4G(2的32次方).也就是说一个进程的最大地址空间为 4G.操作系统的核心是内核(kernel),它独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限.为了保证内核的安全,现在的操作系统一般都强制用户进程不能直接操作内核.具体的实现方式基本都是由操作系统将虚拟地址空间划分
-
Linux内核漏洞浅析
与Windows相比,Linux被认为具有更好的安全性和其他扩展性能.这些特性使得Linux在操作系统领域异军突起,得到越来越多的重视.随着Linux应用量的增加,其安全性也逐渐受到了公众甚或黑客的关注.那么,Linux是否真的如其支持厂商们所宣称的那样安全呢?本期我们请到了启明星辰信息技术有限公司积极防御实验室工程师赵伟,对Linux进行专业的漏洞技术分析. Linux内核精短.稳定性高.可扩展性好.硬件需求低.免费.网络功能丰富.适用于多种cpu等特性,使之在操作系统领域异军突起.其独特的魅