python常用库之NumPy和sklearn入门
Numpy 和 scikit-learn 都是python常用的第三方库。numpy库可以用来存储和处理大型矩阵,并且在一定程度上弥补了python在运算效率上的不足,正是因为numpy的存在使得python成为数值计算领域的一大利器;sklearn是python著名的机器学习库,它其中封装了大量的机器学习算法,内置了大量的公开数据集,并且拥有完善的文档,因此成为目前最受欢迎的机器学习学习与实践的工具。
1. NumPy库
首先导入Numpy库
import numpy as np
1.1 numpy.array 与 list
a = [1,2,3,4,5,6] # python内置数组结构 b = np.array(a) # numpy数组结构
python有内置数组结构(list),我们为什么还要使用numpy的数组结构呢?为了回答这个问题,我们先来看看python内置的数组结构有什么样的特点。我们在使用list的时候会发现,list数组中保存的数据类型是不用相同的,可以是字符串、可以是整型数据、甚至可以是个类实例。这种存储方式很使用,为我们使用带来了很多遍历,但是它也承担了消耗大量内存的缺陷或不足。为什么这么说呢?实际上list数组中的每个元素的存储都需要1个指针和1个数据,也就是说list中保存的其实是数据的存放地址(指针),它比原生态的数组多了一个存放指针的内存消耗。因此,当我们想去减少内存消耗时,不妨将list替换成np.array,这样会节省不少的空间,并且Numpy数组是执行更快数值计算的优秀容器。
1.2 numpy常用操作
创建数组
np.array([1,2,3]) # 创建一维数组 np.asarray([1,2,3]) np.array([1,2,3], [4,5,6]) # 创建多维数组 np.zeros((3, 2)) # 3行2列 全0矩阵 np.ones((3, 2)) #全1矩阵 np.full((3, 2), 5) # 3行2列全部填充5
np.array 和 np.asarray 的区别:
def asarray(a, dtype=None, order=None): return array(a, dtype, copy=False, order=order)
可见,它们区别主要在于: array会复制出一个新的对象,占用一份新的内存空间,而asarray不会执行这一操作。array类似深拷贝,asarray类似浅拷贝。
数值计算
基础计算
arr1 = np.array([[1,2,3], [4,5,6]]) arr2 = np.array([[6,5], [4,3], [2,1]]) # 查看arr维度 print(arr1.shape) # (2, 3) #切片 np.array([1,2,3,4,5,6])[:3] #array([1,2,3]) arr1[0:2,0:2] # 二维切片 #乘法 np.array([1,2,3]) * np.array([2,3,4]) # 对应元素相乘 array([2,6, 12]) arr1.dot(b) # 矩阵乘法 #矩阵求和 np.sum(arr1) # 所有元素之和 21 np.sum(arr1, axis=0) #列求和 array([5, 7, 9]) np.sum(arr1, axis=1) # 行求和 array([ 6, 15]) # 最大最小 np.max(arr1, axis=0/1) np.min(a, axis=0/1)
进阶计算
arr = np.array([[1,2], [3,4], [5,6]]) #布尔型数组访问方式 print((arr>2)) """ [[False False] [ True True] [ True True]] """ print(arr[arr>2]) # [3 4 5 6] #修改形状 arr.reshape(2,3) """ array([[1, 2, 3], [4, 5, 6]]) """ arr.flatten() # 摊平 array([1, 2, 3, 4, 5, 6]) arr.T # 转置
2. sklearn库
若你想快速使用sklearn,我的另一篇博客应该可以满足您的需求,点击跳转:《ML神器:sklearn的快速使用》
是python的重要机器学习库,其中封装了大量的机器学习算法,如:分类、回归、降维以及聚类;还包含了监督学习、非监督学习、数据变换三大模块。sklearn拥有完善的文档,使得它具有了上手容易的优势;并它内置了大量的数据集,节省了获取和整理数据集的时间。因而,使其成为了广泛应用的重要的机器学习库。下面简单介绍一下sklearn下的常用方法。
监督学习
sklearn.neighbors #近邻算法 sklearn.svm #支持向量机 sklearn.kernel_ridge #核-岭回归 sklearn.discriminant_analysis #判别分析 sklearn.linear_model #广义线性模型 sklearn.ensemble #集成学习 sklearn.tree #决策树 sklearn.naive_bayes #朴素贝叶斯 sklearn.cross_decomposition #交叉分解 sklearn.gaussian_process #高斯过程 sklearn.neural_network #神经网络 sklearn.calibration #概率校准 sklearn.isotonic #保守回归 sklearn.feature_selection #特征选择 sklearn.multiclass #多类多标签算法
以上的每个模型都包含多个算法,在调用时直接import即可,譬如:
from sklearn.linear_model import LogisticRefression lr_model = LogisticRegression()
无监督学习
sklearn.decomposition #矩阵因子分解 sklearn.cluster # 聚类 sklearn.manifold # 流形学习 sklearn.mixture # 高斯混合模型 sklearn.neural_network # 无监督神经网络 sklearn.covariance # 协方差估计
数据变换
sklearn.feature_extraction # 特征提取 sklearn.feature_selection # 特征选择 sklearn.preprocessing # 预处理 sklearn.random_projection # 随机投影 sklearn.kernel_approximation # 核逼近
数据集
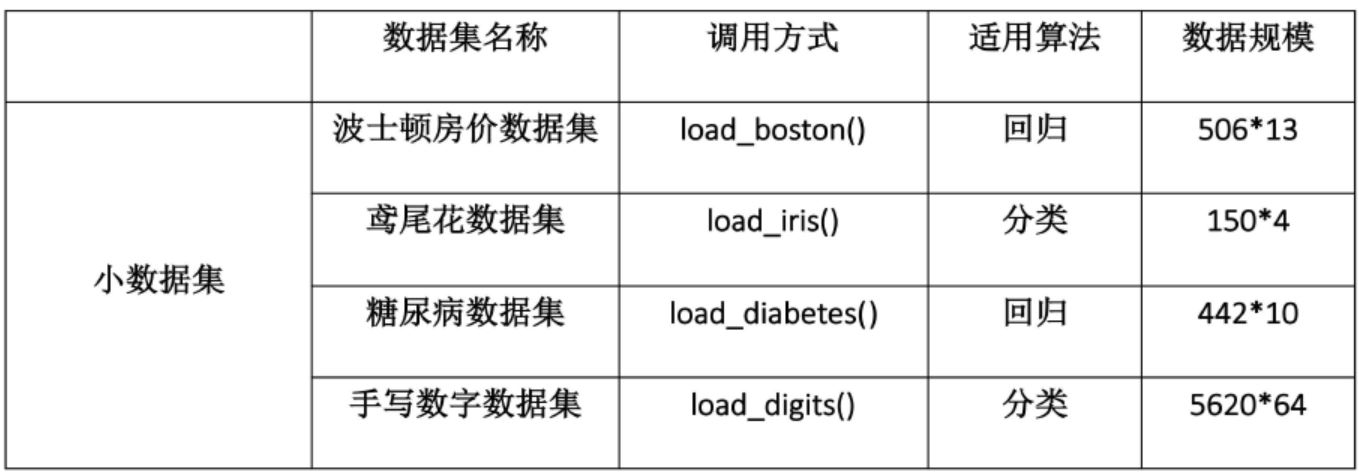
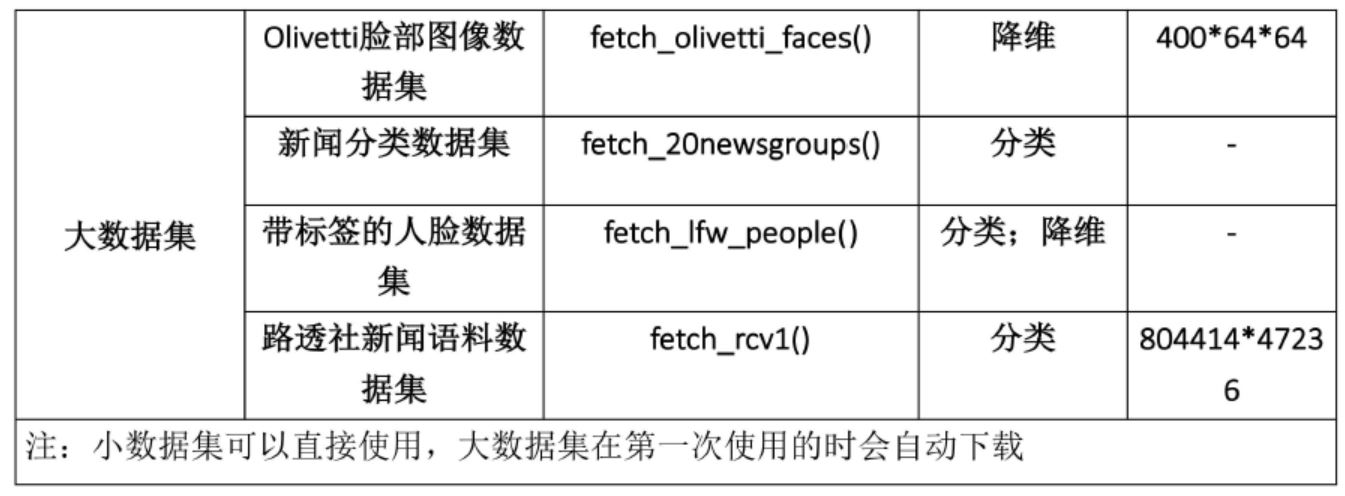
此外,sklearn还有统一的API接口,我们通常可以通过使用完全相同的接口来实现不同的机器学习算法,一般实现流程:
step1. 数据加载和预处理
step2. 定义分类器, 比如: lr_model = LogisticRegression()
step3. 使用训练集训练模型 : lr_model.fit(X,Y)
step4. 使用训练好的模型进行预测: y_pred = lr_model.predict(X_test)
step5. 对模型进行性能评估:lr_model.score(X_test, y_test)
常见命令:
1. 数据集分割
# 作用:将数据集划分为 训练集和测试集 # 格式:train_test_split(*arrays, **options) from sklearn.mode_selection import train_test_split X, y = np.arange(10).reshape((5, 2)), range(5) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) """ 参数 --- arrays:样本数组,包含特征向量和标签 test_size: float-获得多大比重的测试样本 (默认:0.25) int - 获得多少个测试样本 train_size: 同test_size random_state: int - 随机种子(种子固定,实验可复现) shuffle - 是否在分割之前对数据进行洗牌(默认True) 返回 --- 分割后的列表,长度=2*len(arrays), (train-test split) """
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python科学计算之NumPy入门教程
前言 NumPy是Python用于处理大型矩阵的一个速度极快的数学库.它允许你在Python中做向量和矩阵的运算,而且很多底层的函数都是用C写的,你将获得在普通Python中无法达到的运行速度.这是由于矩阵中每个元素的数据类型都是一样的,这也就减少了运算过程中的类型检测. 矩阵基础 在 numpy 包中我们用数组来表示向量,矩阵和高阶数据结构.他们就由数组构成,一维就用一个数组表示,二维就是数组中包含数组表示. 创建 # coding: utf-8 import numpy as np a =
-
Python 机器学习库 NumPy入门教程
NumPy是一个Python语言的软件包,它非常适合于科学计算.在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础库. 本文是对它的一个入门教程. 介绍 NumPy是一个用于科技计算的基础软件包,它是Python语言实现的.它包含了: 强大的N维数组结构 精密复杂的函数 可集成到C/C++和Fortran代码的工具 线性代数,傅里叶变换以及随机数能力 除了科学计算的用途以外,NumPy也可被用作高效的通用数据的多维容器.由于它适用于任意类型的数据,这使得NumPy可以无缝和
-
Python中的Numpy入门教程
1.Numpy是什么 很简单,Numpy是Python的一个科学计算的库,提供了矩阵运算的功能,其一般与Scipy.matplotlib一起使用.其实,list已经提供了类似于矩阵的表示形式,不过numpy为我们提供了更多的函数.如果接触过matlab.scilab,那么numpy很好入手. 在以下的代码示例中,总是先导入了numpy: 复制代码 代码如下: >>> import numpy as np>>> print np.version.version1.6.2
-
python常用库之NumPy和sklearn入门
Numpy 和 scikit-learn 都是python常用的第三方库.numpy库可以用来存储和处理大型矩阵,并且在一定程度上弥补了python在运算效率上的不足,正是因为numpy的存在使得python成为数值计算领域的一大利器:sklearn是python著名的机器学习库,它其中封装了大量的机器学习算法,内置了大量的公开数据集,并且拥有完善的文档,因此成为目前最受欢迎的机器学习学习与实践的工具. 1. NumPy库 首先导入Numpy库 import numpy as np 1.1 nu
-
Python常用库Numpy进行矩阵运算详解
Numpy支持大量的维度数组和矩阵运算,对数组运算提供了大量的数学函数库! Numpy比Python列表更具优势,其中一个优势便是速度.在对大型数组执行操作时,Numpy的速度比Python列表的速度快了好几百.因为Numpy数组本身能节省内存,并且Numpy在执行算术.统计和线性代数运算时采用了优化算法. Numpy的另一个强大功能是具有可以表示向量和矩阵的多维数组数据结构.Numpy对矩阵运算进行了优化,使我们能够高效地执行线性代数运算,使其非常适合解决机器学习问题. 与Python列表相比
-
关于Python常用函数中NumPy的使用
目录 1. txt文件 2. CSV文件 3.成交量加权平均价格 = average()函数 4. 算数平均值函数 = mean()函数 5. 时间加权平均价格 6. 最大值和最小值 7. 统计分析 8. 股票收益率 1. txt文件 (1) 单位矩阵 即主对角线上的元素均为1,其余元素均为0的正方形矩阵. 在NumPy中可以用eye函数创建一个这样的二维数组,我们只需要给定一个参数,用于指定矩阵中1的元素个数. 例如,创建3×3的数组: import numpy as np I2 = np.e
-
Python常用库大全及简要说明
环境管理 管理 Python 版本和环境的工具 p:非常简单的交互式 python 版本管理工具.官网 pyenv:简单的 Python 版本管理工具.官网 Vex:可以在虚拟环境中执行命令.官网 virtualenv:创建独立 Python 环境的工具.官网 virtualenvwrapper:virtualenv 的一组扩展.官网 buildout:在隔离环境初始化后使用声明性配置管理.官网 包管理 管理包和依赖的工具. pip:Python 包和依赖关系管理工具.官网 pip-tools:
-
Python常用库推荐
IPython + ptpython,完美体验 首先是安装 pip install ipython ptpython 然后使用 ptipython 有什么好处 1. IPython 是非常强大的 Python 增强工具 2. ptpython 提供了类似 IDE 的自动补全功能 3. 当你在命令行输入 pyipython 时,便结合了这两者的功能,无比强大! virtualenv + virtualenvwrapper,轻松创建隔离环境 首先安装 pip install virtualenvwr
-
常用python爬虫库介绍与简要说明
这个列表包含与网页抓取和数据处理的Python库 python网络库 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pycurl). pycurl – 网络库(绑定libcurl). urllib3 – Python HTTP库,安全连接池.支持文件post.可用性高. httplib2 – 网络库. RoboBrowser – 一个简单的.极具Python风格的Python库,无需独立的浏览器即可浏览网页. MechanicalSoup
-

Python爬虫常用库的安装及其环境配置
Python常用库的安装 urllib.re 这两个库是Python的内置库,直接使用方法import导入即可. 在python中输入如下代码: import urllib import urllib.request response=urllib.request.urlopen("http://www.baidu.com") print(response) 返回结果为HTTPResponse的对象: <http.client.HTTPResponse object at 0x0
-
Python基础之常用库常用方法整理
一.os __file__ 获取当前运行的.py文件所在的路径(D:\PycharmProjects\My_WEB_UI\ConfigFiles\ConfigPath.py) os.path.dirname(__file__) 上面正在运行的.py文件的上一级(D:\PycharmProjects\My_WEB_UI\ConfigFiles) os.path.join(xxx,u'ConfigFiles\elementLocation.ini') 在已获得的路径xxx上加上\ConfigFile
-
使用Python第三方库发送电子邮件的示例代码
目录 1. 安装 yagmail 第三方库 2. 开启 POP3.IMAP 和 SMTP 服务 2.1 POP3.IMAP 和 SMTP 简介 2.2 开启 POP3.IMAP.和 SMTP 协议 3. 发送邮件 3.1 发送第一封电子邮件 3.2 群发邮件 3.3 给邮件添加附件 3.4 设置定时器 4. 总结 Python 作为当前最热门的编程语言之一,不仅仅是因为它的学习成本低.入门容易,还因为它具有丰富的生态环境,包括内置的模块以及第三方的库,使用它能够做很多事情.例如,办公自动化也是