c语言实现词频统计的简单实例
需求:
1.设计一个词频统计软件,统计给定英文文章的单词频率。
2.文章中包含的标点不计入统计。
3.将统计结果以从大到小的排序方式输出。
设计:
1.因为是跨专业0.0···并不会c++和java,只能用仅学过的C语言进行编写,还是挺费劲的。
2.定义一个包含单词和频率两个成员的结构体来统计词频(进行了动态分配内存,可以处理较大文本)。
3.使用fopen函数读取指定的文档。
4.使用fgetc函数获取字符,再根据取得的字符是否是字母进行不同的处理。
5.采用快速排序法对统计结果进行排序。
5.将整个统计结果循环输出。
部分代码:
结构体定义:
struct fre_word
{
int num;
char a[18];
};
分配初始内存:
struct fre_word *w; w=(struct fre_word *)malloc(100*p*sizeof(struct fre_word));//给结构体分配初始内存
读取文本:
printf("输入读入文件的名字:");
scanf("%s", filename); //输入需要统计词频的文件名
if((fp=fopen(filename, "r"))==NULL)
{
printf("无法打开文件\n");
exit(0);
}
单词匹配:
/****************将单词出现次数设置为1****************************/
for(i=0;i<100;i++)
{
(w+i)->num=1;
}
/****************单词匹配****************************************/
i=0;
while(!feof(fp))//文件尚未读取完毕
{
ch=fgetc(fp);
(w+i)->a[j]='\0';
if(ch>=65&&ch<=90||ch>=97&&ch<=122) //ch若为字母则存入
{
(w+i)->a[j]=ch;
j++;
flag=0; //设标志位判断是否存在连续标点或者空格
}
else if(!(ch>=65&&ch<=90||ch>=97&&ch<=122)&&flag==0) //ch若不是字母且上一个字符为字母
{
i++;
j=0;
flag=1;
for(m=0;m<i-1;m++) //匹配单词,若已存在则num+1
{
if(stricmp((w+m)->a,(w+i-1)->a)==0)
{
(w+m)->num++;
i--;
}
}
}
/****************动态分配内存****************************************/
if(i==(p*100)) //用i判断当前内存已满
{
p++;
w=(struct fre_word*)realloc(w,100*p*(sizeof(struct fre_word)));
for(n=i;n<=100*p;n++) //给新分配内存的结构体赋初值
(w+n)->num=1;
}
}
快速排序:
void quick(struct fre_word *f,int i,int j)
{
int m,n,temp,k;
char b[18];
m=i;
n=j;
k=f[(i+j)/2].num; //选取的参照
do
{
while(f[m].num>k&&m<j) m++; // 从左到右找比k小的元素
while(f[n].num<k&&n>i) n--; // 从右到左找比k大的元素
if(m<=n)
{ //若找到且满足条件,则交换
temp=f[m].num;
strcpy(b,f[m].a);
f[m].num=f[n].num;
strcpy(f[m].a,f[n].a);
f[n].num=temp;
strcpy(f[n].a,b);
m++;
n--;
}
}
while(m<=n);
if(m<j) quick(f,m,j); //运用递归
if(n>i) quick(f,i,n);
}
结果输出:
for(n=0;n<=i;n++)
{
printf("文档中出现的单词:");
printf("%-18s",(w+n)->a);
printf("其出现次数为:");
printf("%d\n",(w+n)->num);
}
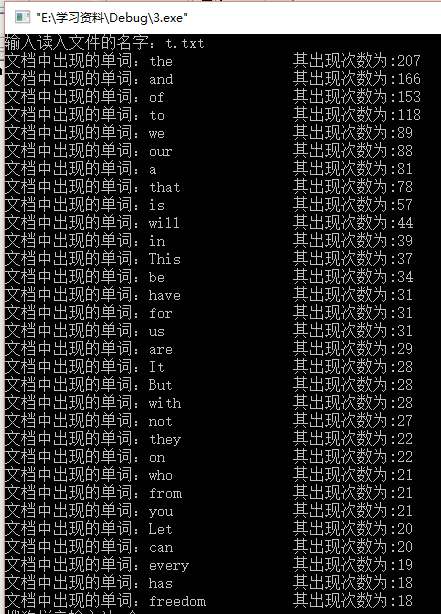
测试用例:
看了之前同学的博客以及老师的评论,就使用了较长的文本进行测试,用的是奥巴马就职演讲稿。

部分测试结果:
以上这篇c语言实现词频统计的简单实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
java 字符串词频统计实例代码
复制代码 代码如下: package com.gpdi.action; import java.util.ArrayList; import java.util.Collections; import java.util.HashMap; import java.util.List; import java.util.Map; public class WordsStatistics { class Obj { int count ; Obj(int count)
-

c语言实现词频统计的简单实例
需求: 1.设计一个词频统计软件,统计给定英文文章的单词频率. 2.文章中包含的标点不计入统计. 3.将统计结果以从大到小的排序方式输出. 设计: 1.因为是跨专业0.0···并不会c++和java,只能用仅学过的C语言进行编写,还是挺费劲的. 2.定义一个包含单词和频率两个成员的结构体来统计词频(进行了动态分配内存,可以处理较大文本). 3.使用fopen函数读取指定的文档. 4.使用fgetc函数获取字符,再根据取得的字符是否是字母进行不同的处理. 5.采用快速排序法对统计结果进行排序. 5
-
JS实现点击事件统计的简单实例
JS实现网站点击事件的统计功能. 点击事件上报,分为立即上报和延时上报,延时上报通过cookie存储. 一.配置参数,主要用于定义上报的一些配置信息.通过在外部定义_clickc对象重置参数. 参数名称 类型 默认值 说明 selector: string '_click_rp' 点击触发的选择器,支持ID.class prefix: string '_rp_'
-
C语言对磁盘文件进行快速排序简单实例
C语言对磁盘文件进行快速排序简单实例 快速排序(quick sort)是由C.A.R.Hoare发明并命名的,这种排序被认为是目前最好的一种排序算法.快速排序基于交换排序,与同样的基于交换排序的冒泡排序法相比,其效果非常明显. 它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 本例中快速排序是通过函数quick_disk(FILE
-
C语言数据结构之循环链表的简单实例
C语言数据结构之循环链表的简单实例 实例代码: # include <stdio.h> # include <stdlib.h> typedef struct node //定义链表中结点的结构 { int code; struct node *next; }NODE,*LinkList; /*错误信息输出函数*/ void Error(char *message) { fprintf(stderr,"Error:%s/n",message); exit(1)
-
c语言读取txt文件内容简单实例
在C语言中,文件操作都是由库函数来完成的. 要读取一个txt文件,首先要使用文件打开函数fopen(). fopen函数用来打开一个文件,其调用的一般形式为: 文件指针名=fopen(文件名,使用文件方式) 其中,"文件指针名"必须是被说明为FILE 类型的指针变量,"文件名"是被打开文件的文件名. "使用文件方式"是指文件的类型和操作要求."文件名"是字符串常量或字符串数组. 其次,使用文件读写函数读取文件. 在C语言中提供
-
c语言 字符串转大写的简单实例
复制代码 代码如下: #include <string.h> #include <stdio.h> #include <ctype.h> #include <stdlib.h> int main(void) { int length, i; char string[20]= "this is a string"; length = strlen(string); for (i=0; i<length; i++)
-
python 统计代码行数简单实例
python 统计代码行数简单实例 送测的时候,发现需要统计代码行数 于是写了个小程序统计自己的代码的行数. #calclate_code_lines.py import os def afileline(f_path): res = 0 f = open(f_path) for lines in f: if lines.split(): res += 1 return res if __name__=='__main__': host = 'E:'+os.sep+'develop'+os.s
-
C语言指针应用简单实例
C语言指针应用简单实例 这次来说交换函数的实现: 1. #include <stdio.h> #include <stdlib.h> void swap(int x, int y) { int temp; temp = x; x = y; y = temp; } int main() { int a = 10, b = 20; printf("交换前:\n a = %d, b = %d\n", a, b); swap(a, b); printf("交换
-
C语言实现去除字符串中空格的简单实例
在网上看了些去除空格的代码,觉得都不是很简洁,就自己写代码实现它本着高效率,不使用额外存储空间的想法实现该功能去除空格一共有三种: 1.去除全部空格: 2.一种是去除左边空格: 3.去除右边空格 想去除左右两边空格,只要先去除左边再去除右边的就行了 以下是实现代码: /*去除字符串中所有空格*/ voidVS_StrTrim(char*pStr) { char *pTmp = pStr; while (*pStr != '/0') { if (*pStr != ' ') { *pTmp++ =
-
C++实现统计代码运行时间计时器的简单实例
C++实现统计代码运行时间计时器的简单实例 一.前言 这里记下从网上找到的一些自己比较常用的C++计时代码 二.Linux下精确至毫秒 #include <sys/time.h> #include <iostream> #include <time.h> double get_wall_time() { struct timeval time ; if (gettimeofday(&time,NULL)){ return 0; } return (double