Python多项式回归的实现方法
多项式回归是一种线性回归形式,其中自变量x和因变量y之间的关系被建模为n次多项式。多项式回归拟合x的值与y的相应条件均值之间的非线性关系,表示为E(y | x)
为什么多项式回归:
- 研究人员假设的某些关系是曲线的。显然,这种类型的案例将包括多项式项。
- 检查残差。如果我们尝试将线性模型拟合到曲线数据,则预测变量(X轴)上的残差(Y轴)的散点图将在中间具有许多正残差的斑块。因此,在这种情况下,这是不合适的。
- 通常的多元线性回归分析的假设是所有自变量都是独立的。在多项式回归模型中,不满足该假设。
多项式回归的使用:
这些基本上用于定义或描述非线性现象,例如:
- 组织生长速度。
- 疾病流行病的进展
- 湖泊沉积物中碳同位素的分布
回归分析的基本目标是根据自变量x的值来模拟因变量y的期望值。在简单回归中,我们使用以下等式 y = a + bx + e
这里y是因变量,a是y截距,b是斜率,e是误差率。
在许多情况下,这种线性模型将无法解决。例如,如果我们在这种情况下根据合成温度分析化学合成的产生,我们使用二次模型y = a + b1x + b2 ^ 2 + e
这里y是x的因变量,a是y截距,e是误差率。
通常,我们可以将其建模为第n个值。y = a + b1x + b2x ^ 2 + .... + bnx ^ n
由于回归函数在未知变量方面是线性的,因此这些模型从估计的角度来看是线性的。
因此,通过最小二乘技术,让我们计算y的响应值。
Python中的多项式回归:
要获得用于分析多项式回归的数据集,请单击此处。
步骤1:导入库和数据集
导入重要的库和我们用于执行多项式回归的数据集。
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
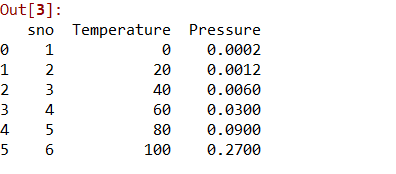
datas = pd.read_csv('data.csv')
datas
第2步:将数据集分为2个组件
将数据集划分为两个组件,即X和yX将包含1到2之间的列.y将包含2列。
X = datas.iloc[:, 1:2].values y = datas.iloc[:, 2].values
第3步:将线性回归拟合到数据集
拟合线性回归模型在两个组件上。
# Fitting Linear Regression to the dataset from sklearn.linear_model import LinearRegression lin = LinearRegression() lin.fit(X, y)
第4步:将多项式回归拟合到数据集
将多项式回归模型拟合到两个分量X和y上。
# Fitting Polynomial Regression to the dataset from sklearn.preprocessing import PolynomialFeatures poly = PolynomialFeatures(degree = 4) X_poly = poly.fit_transform(X) poly.fit(X_poly, y) lin2 = LinearRegression() lin2.fit(X_poly, y)
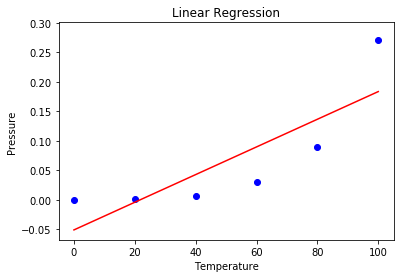
步骤5:在此步骤中,我们使用散点图可视化线性回归结果。
# Visualising the Linear Regression results
plt.scatter(X, y, color = 'blue')
plt.plot(X, lin.predict(X), color = 'red')
plt.title('Linear Regression')
plt.xlabel('Temperature')
plt.ylabel('Pressure')
plt.show()
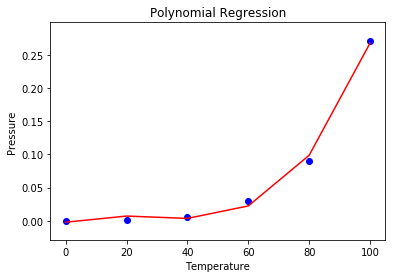
步骤6:使用散点图可视化多项式回归结果。
# Visualising the Polynomial Regression results
plt.scatter(X, y, color = 'blue')
plt.plot(X, lin2.predict(poly.fit_transform(X)), color = 'red')
plt.title('Polynomial Regression')
plt.xlabel('Temperature')
plt.ylabel('Pressure')
plt.show()
步骤7:使用线性和多项式回归预测新结果。
# Predicting a new result with Linear Regression lin.predict(110.0)
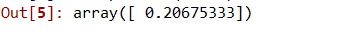
# Predicting a new result with Polynomial Regression lin2.predict(poly.fit_transform(110.0))
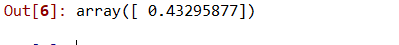
使用多项式回归的优点:
- 广泛的功能可以适应它。
- 多项式基本上适合宽范围的曲率。
- 多项式提供了依赖变量和自变量之间关系的最佳近似。
使用多项式回归的缺点
- 这些对异常值过于敏感。
- 数据中存在一个或两个异常值会严重影响非线性分析的结果。
- 此外,遗憾的是,用于检测非线性回归中的异常值的模型验证工具少于线性回归。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python 确定多项式拟合/回归的阶数实例
通过 1至10 阶来拟合对比 均方误差及R评分,可以确定最优的"最大阶数". import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression,Perceptron from sklearn.metrics import mean_squared_
-

Python多项式回归的实现方法
多项式回归是一种线性回归形式,其中自变量x和因变量y之间的关系被建模为n次多项式.多项式回归拟合x的值与y的相应条件均值之间的非线性关系,表示为E(y | x) 为什么多项式回归: 研究人员假设的某些关系是曲线的.显然,这种类型的案例将包括多项式项. 检查残差.如果我们尝试将线性模型拟合到曲线数据,则预测变量(X轴)上的残差(Y轴)的散点图将在中间具有许多正残差的斑块.因此,在这种情况下,这是不合适的. 通常的多元线性回归分析的假设是所有自变量都是独立的.在多项式回归模型中,不满足该假设. 多项
-
8种用Python实现线性回归的方法对比详解
前言 说到如何用Python执行线性回归,大部分人会立刻想到用sklearn的linear_model,但事实是,Python至少有8种执行线性回归的方法,sklearn并不是最高效的. 今天,让我们来谈谈线性回归.没错,作为数据科学界元老级的模型,线性回归几乎是所有数据科学家的入门必修课.抛开涉及大量数统的模型分析和检验不说,你真的就能熟练应用线性回归了么?未必! 在这篇文章中,文摘菌将介绍8种用Python实现线性回归的方法.了解了这8种方法,就能够根据不同需求,灵活选取最为高效的方法实现线
-
Python中pygame安装方法图文详解
本文实例讲述了Python中pygame安装方法.分享给大家供大家参考,具体如下: 这里主要描述一下我们怎样来安装pygame 可能很多人像我一样,发现了pygame是个好东东,但是就是不知道怎样使用,或者怎样安装,在百度/google上面搜索了一番后,发现没有一篇 详细描述pygame的安装过程的文章.如果你是其中的一员,那么这篇教程可能会帮助到你. 当然,在学习pygame的时候,需要你要有一定的python基础知识的.如果你已经具备了一定的python基础,那么接下来的内容可能对你来说就很
-
使用Python生成XML的方法实例
本文实例讲述了使用Python生成XML的方法.分享给大家供大家参考,具体如下: 1. bookstore.py #encoding:utf-8 ''' 根据一个给定的XML Schema,使用DOM树的形式从空白文件生成一个XML. ''' from xml.dom.minidom import Document doc = Document() #创建DOM文档对象 bookstore = doc.createElement('bookstore') #创建根元素 bookstore.set
-
Python实现栈的方法
本文实例讲述了Python实现栈的方法.分享给大家供大家参考.具体实现方法如下: #!/usr/bin/env python #定义一个列表来模拟栈 stack = [] #进栈,调用列表的append()函数加到列表的末尾,strip()没有参数是去掉首尾的空格 def pushit(): stack.append(raw_input('Enter new string: ').strip()) #出栈,用到了pop()函数 def popit(): if len(stack) == 0: p
-
Windows下安装Redis及使用Python操作Redis的方法
首先说一下在Windows下安装Redis,安装包可以在https://github.com/MSOpenTech/redis/releases中找到,可以下载msi安装文件,也可以下载zip的压缩文件. 下载zip文件之后解压,解压后是这些文件: 里面这个Windows Service Documentation.docx是一个文档,里面有安装指导和使用方法. 也可以直接下载msi安装文件,直接安装,安装之后的安装目录中也是这些文件,可以对redis进行相关的配置. 安装完成之后可以对redi
-
python计算时间差的方法
本文实例讲述了python计算时间差的方法.分享给大家供大家参考.具体分析如下: 1.问题: 给定你两个日期,如何计算这两个日期之间间隔几天,几个星期,几个月,几年? 2.解决方法: 标准模块datetime和第三方包dateutil(特别是dateutil的rrule.count方法)能非常简单迅速的帮你解决这个问题. from dateutil import rrule import datetime def weeks_between(start_date, end_date): week
-
Python三元运算实现方法
本文实例讲述了Python三元运算实现方法.分享给大家供大家参考.具体分析如下: Python中没有像C++和Java等语言中的三元运算符,但是可以用if else语句实现相同的功能: 复制代码 代码如下: >>> condition = True >>> print 'True' if condition else 'False' True >>> condition = False >>> print 'True' if
-
Python实现堆排序的方法详解
本文实例讲述了Python实现堆排序的方法.分享给大家供大家参考,具体如下: 堆排序作是基本排序方法的一种,类似于合并排序而不像插入排序,它的运行时间为O(nlogn),像插入排序而不像合并排序,它是一种原地排序算法,除了输入数组以外只占用常数个元素空间. 堆(定义):(二叉)堆数据结构是一个数组对象,可以视为一棵完全二叉树.如果根结点的值大于(小于)其它所有结点,并且它的左右子树也满足这样的性质,那么这个堆就是大(小)根堆. 我们假设某个堆由数组A表示,A[1]为树的根,给定某个结点的下标i,
-
python复制文件的方法实例详解
本文实例讲述了python复制文件的方法.分享给大家供大家参考.具体分析如下: 这里涉及Python复制文件在实际操作方案中的实际应用以及Python复制文件 的相关代码说明,希望你会有所收获. Python复制文件: import shutil import os import os.path src = " d:\\download\\test\\myfile1.txt " dst = " d:\\download\\test\\myfile2.txt " ds