分析MySQL复制以及调优原理和方法
一. 简介
MySQL自带复制方案,带来好处有:
数据备份。
负载均衡。
分布式数据。
概念介绍:
主机(master):被复制的数据库。
从机(slave):复制主机数据的数据库。
复制步骤:
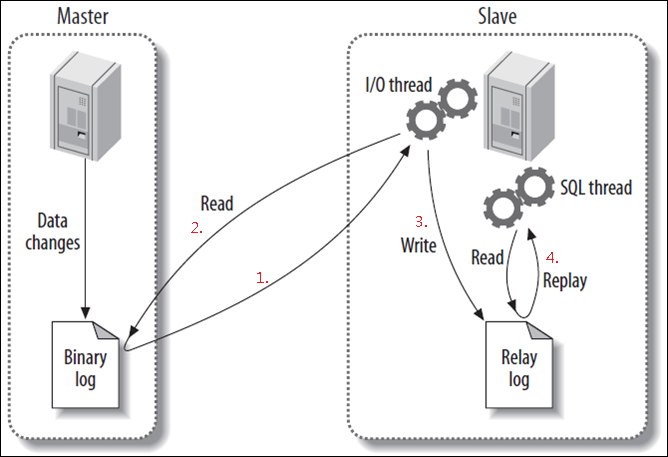
(1). master记录更改的明细,存入到二进制日志(binary log)。
(2). master发送同步消息给slave。
(3). slave收到消息后,将master的二进制日志复制到本地的中继日志(relay log)。
(4). slave重现中继日志中的消息,从而改变数据库的数据。
下面放一张经典的图片来说明这一过程:
二. 实现复制
实现复制有以下步骤:
1.设置MySQL主库的二进制日志以及server-id
MySQL配置文件一般存放在/etc/my.cnf
# 在[mysqld]下面添加配置选项 [mysqld] server-id=1 log-bin=mysql-bin.log
server-id是数据库在整个数据库集群中的唯一标示,必须保持唯一。
重启MySQL。
注:如果MySQL配置文件中已经配置过此文件,则可以跳过此步。
2.新建复制账号
在主库里面新建用于从库复制主库数据的账号,并授予复制权限。
mysql> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO user_name@'host' IDENTIFIED BY 'password';
3.设置MySQL主库server-id
和第二步配置一样,要注意的地方有两点:
如果不需要从库作为别的从库的主库的话,则不需要配置二进制日志。很多时候复制并不需要复制主库的全部数据库(特别是mysql的信息配置库)。因此可以配置replicate_do_db来指定复制的数据库 4.从库初始化主库的数据
如果数据量不算大的情况下,可以使用mysqldump工具导出主库数据,然后导入到从库里面。
mysqldump --single-transaction --triggers --master-data databasename > data.sql
如果数据量大的情况下应该使用Xtrabackup去进行数据库的导出,此处不做介绍。
可能会有同学问,为什么不直接使用二进制日志进行初始化呢?
如果我们主库运行了比较长的一段时间,并不太适合使用从库根据二进制日志进行复制数据,直接使用二进制日志去初始化从库会比较耗费时间和性能。更多的情况下,主库的二进制日志的配置项没有打开,因此也就不存在以前操作的二进制日志。 5.开启复制
从库执行下面命令
mysql> CHANGE MASTER TO MASTER_HOST='host', -> MASTER_USER='user', -> MASTER_PASSWORD='password', -> MASTER_LOG_FILE='mysql-bin.000001', -> MASTER_LOG_POS=0;
注意最后的两个命令:MASTER_LOG_FILE和MASTER_LOG_POS,表示从库的从哪个二进制文件开始读取,偏移量从那里开始,这两个参数可以从我们导入的SQL里面找到。

开启复制
start slave;
这时候就完成了复制,在主库更新一个数据或者新增数据在从库都可以查询到结果。

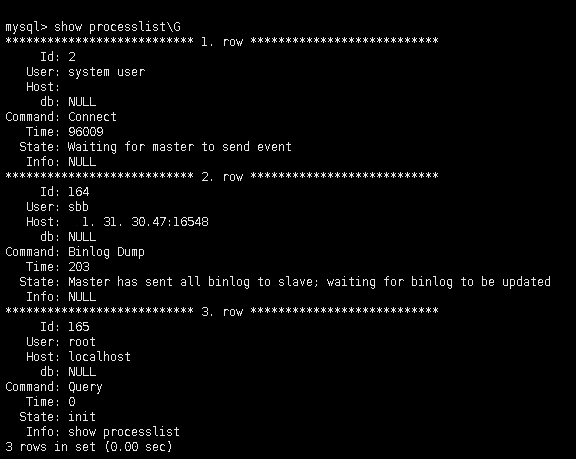
在主库上也可以查询的到复制线程的状态。
三. 复制的日志格式
MySQL复制的日志格式有三种,根据主库存放数据的方式不同有以下三种:
| 复制方式 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| row | 基于行的格式复制,记录需要修改的每行的数据信息。 如果一个SQL修改了2w行的数据,那么就会记录2w行的日志格式 | 保证了数据的强一致性,且由于记录的是执行后的结果,在从库上执行还原也会比较快 | 日志记录数量很多,主从之间的传输需要更多的时间。 |
| statement | 基于段的日志格式复制,也就是记录下更改的SQL记录,而不是更改的行的记录。 | 日志记录量最小。 | 对于一些输出结果不确定的函数,在从库上执行一遍很可能会出现问题,如uuid,从库根据日志还原主库数据的时候需要执行一遍SQL,时间相对较慢。 |
| mixed | 混合上面两种日志格式记录记录日志,至于什么时候使用哪种日志方式由MySQL本身决定。 | 可以平衡上面两种日志格式的优缺点。 |
mysql5.7以前默认使用statement格式。
设置方式,可以在配置文件设置(首选):
binlog_format=ROW
或临时设置全局变量(当前mysql连接有效):
查看日志格式 mysql > show variables like 'binlog_format'; 设置日志格式 mysql > set binlog_format='row';
由于两个主从服务器一般都会放在同一个机房里面,两者之间同步的速度会会比较快,为保证强一致性,应该首选行的日志格式记录(row),保证传输素速度可以选择混合方式(mixed)。
而行的日志格式有下面三种记录方式:
| 记录方式 | 特点 |
|---|---|
| minimal | 只记录被修改列的数据 |
| full | 记录被修改的行的全部列的数据 |
| noblob | 特点同上,只是如果没有修改blob和text类型的列的情况下,不会记录这些列的数据(也就是大数据列) |
mysql默认是full,最好修改成minimal。
binlog_row_image=minimal
四. 主从复制延迟
由于主库和从库之间不在同一个主机上,数据同步之间不可以避免地具有延迟,解决的方法有添加缓存,业务层的跳转等待,如果非得从数据库层面去减缓延迟问题,可以从复制时候的三大步骤(主库产生日志,主从传输日志,从库还原日志内容)入手:
1.主库写入到日志的速度
控制主库的事务大小,分割大事务为多个小事务。
如插入20w的数据,改成插入多次5000行(可以利用分页的思路)
2.二进制日志在主从之间传输时间
主从之间尽量在同一个机房或地域。
日志格式改用MIXED,且设置行的日志格式未minimal,原理详见上面的日志格式介绍。
3.减少从库还原日志的时间
在MySQL5.7版本后可以利用逻辑时钟方式分配SQL多线程。
设置逻辑时钟:slave_parallel_type=‘logical_clock';
设置复制线程个数:slave_parallel_workers=4;
五. 需要注意的地方
重启MySQL最好切换未MySQL用户再进行操作,不然文件启动后会有权限问题。搭建好MySQL的环境后就设置好配置里的log-bin选项,这样以后如果数据库需要从库的复制,就不需要重启数据库,打断业务的进行。需要打开主库的防火墙的对应的mysql端口。由于从库同步主库的方式,监听主库发送的信息,而不是轮询,因此如果出现通信出现了故障,重新连接后如果主库没有进行数据更改的操作,从库不会同步数据,因此可以通过插入空事务的方式同步数据。
以上就是小编本次整理的全部内容,感谢你对我们的支持。
您可能感兴趣的文章:
- Mysql安装与配置调优及修改root密码的方法
- mysql sql语句性能调优简单实例
- 10个MySQL性能调优的方法
- Mysql优化调优中两个重要参数table_cache和key_buffer
- MySQL慢查询查找和调优测试
- mysql 性能的检查和调优方法
相关推荐
-
mysql 性能的检查和调优方法
在遇到严重性能问题时,一般都有这么几种可能:1.索引没有建好; 2.sql写法过于复杂; 3.配置错误; 4.机器实在负荷不了; 1.索引没有建好 如果看到mysql消耗的cpu很大,可以用mysql的client工具来检查. 在linux下执行 /usr/local/mysql/bin/mysql -hlocalhost -uroot -p 输入密码,如果没有密码,则不用-p参数就可以进到客户端界面中. 看看当前的运行情况 show full processlist 可以多运行几次 这个命令可
-
Mysql安装与配置调优及修改root密码的方法
一.安装 apt-get install mysql-server 需要设置账号密码 apt-get isntall mysql-client apt-get libmysqlclient-dev 2.sudo netstat -tap | grep mysql 查看是否安装成功 root@xyz:~# netstat -tap | grep mysql tcp6 0 0 [::]:mysql [::]:* LISTEN 7510/mysqld -->安装成功 二.设置mysql远程访问 1.
-
Mysql优化调优中两个重要参数table_cache和key_buffer
本文根据作者的一点经验,讨论了Mysql服务器优化中两个非常重要的参数,分别是table_cache,key_buffer_size. table_cache指示表高速缓存的大小.当Mysql访问一个表时,如果在Mysql表缓冲区中还有空间,那么这个表就被打开并放入表缓冲区,这样做的好处是可以更快速地访问表中的内容.一般来说,可以通过查看数据库运行峰值时间的状态值Open_tables和Opened_tables,用以判断是否需要增加table_cache的值,即如果open_tables接近t
-
MySQL慢查询查找和调优测试
编辑 my.cnf或者my.ini文件,去除下面这几行代码的注释: 复制代码 代码如下: log_slow_queries = /var/log/mysql/mysql-slow.log long_query_time = 2 log-queries-not-using-indexes 这将使得慢查询和没有使用索引的查询被记录下来. 这样做之后,对mysql-slow.log文件执行tail -f命令,将能看到其中记录的慢查询和未使用索引的查询. 随便提取一个慢查询,执行explain: 复制代
-

mysql sql语句性能调优简单实例
mysql sql语句性能调优简单实例 在做服务器开发时,有时候对并发量有一定的要求,有时候影响速度的是某个sql语句,比如某个存储过程.现在假设服务器代码执行过程中,某个sql执行比较缓慢,那如何进行优化呢? 假如现在服务器代码执行如下sql存储过程特别缓慢: call sp_wplogin_register(1, 1, 1, '830000', '222222'); 可以按如下方法来进行调试: 1. 打开mysql profiling: 2. 然后执行需要调优的sql,我们这里执行两条sq
-
10个MySQL性能调优的方法
MYSQL 应该是最流行了 WEB 后端数据库.WEB 开发语言最近发展很快,PHP, Ruby, Python, Java 各有特点,虽然 NOSQL 最近越來越多的被提到,但是相信大部分架构师还是会选择 MYSQL 来做数据存储. MYSQL 如此方便和稳定,以至于我们在开发 WEB 程序的时候很少想到它.即使想到优化也是程序级别的,比如,不要写过于消耗资源的 SQL 语句.但是除此之外,在整个系统上仍然有很多可以优化的地方. 1. 选择合适的存储引擎: InnoDB 除非你的数据表使用来做
-
分析MySQL复制以及调优原理和方法
一. 简介 MySQL自带复制方案,带来好处有: 数据备份. 负载均衡. 分布式数据. 概念介绍: 主机(master):被复制的数据库. 从机(slave):复制主机数据的数据库. 复制步骤: (1). master记录更改的明细,存入到二进制日志(binary log). (2). master发送同步消息给slave. (3). slave收到消息后,将master的二进制日志复制到本地的中继日志(relay log). (4). slave重现中继日志中的消息,从而改变数据库的数据. 下
-
分析MySQL并发下的问题及解决方法
1.背景 对于数据库系统来说在多用户并发条件下提高并发性的同时又要保证数据的一致性一直是数据库系统追求的目标,既要满足大量并发访问的需求又必须保证在此条件下数据的安全,为了满足这一目标大多数数据库通过锁和事务机制来实现,MySQL数据库也不例外.尽管如此我们仍然会在业务开发过程中遇到各种各样的疑难问题,本文将以案例的方式演示常见的并发问题并分析解决思路. 2.表锁导致的慢查询的问题 首先我们看一个简单案例,根据ID查询一条用户信息: mysql> select * from user where
-
MySQL复制出错 Last_SQL_Errno:1146的解决方法
背景:我们在做数据迁移或者拆分的时候,使用Tablespace transcation 这种解决方案时,很有可能就会遇到 从库复制出错,报: Last_SQL_Errno: 1146 那么具体错误内容可能会有如下: Last_SQL_Error: Error 'Table 'spider.tb_city_population_rank' doesn't exist' on query. Default database: 'spider'. Query: 'alter table tb_city
-
web性能优化之javascript性能调优
JavaScript 是一个比较完善的前端开发语言,在现今的 web 开发中应用非常广泛,尤其是对 Web 2.0 的应用.随着 Web 2.0 越来越流行的今天,我们会发现:在我们的 web 应用项目中,会有大量的 JavaScript 代码,并且以后会越来越多.JavaScript 作为一个解释执行的语言,以及它的单线程机制,决定了性能问题是 JavaScript 的软肋,也是 web 软件工程师们在写 JavaScript 需要高度重视的一个问题,尤其是针对 Web 2.0 的应用.绝大多
-
jvm垃圾回收GC调优基础原理分析
目录 核心概念(Core Concepts) Latency(延迟) Throughput(吞吐量) Capacity(系统容量) 相关示例 Tuning for Latency(调优延迟指标) Tuning for Throughput(吞吐量调优) Tuning for Capacity(调优系统容量) 说明: Capacity: 性能,能力,系统容量; 文中翻译为”系统容量“; 意为硬件配置. GC调优(Tuning Garbage Collection)和其他性能调优是同样的原理.初学者
-
Sklearn调优之网格搜索与随机搜索原理详细分析
目录 前言 网格搜索(Grid Search) 随机搜索(Randomized Search) 前言 超参调优是“模型调优”(Model Tuning)阶段最主要的工作,是直接影响模型最终效果的关键步骤,然而,超参调优本身却是一项非常低级且枯燥的工作,因为它的策略就是:不断变换参数值,一轮一轮地去“试”,直到找出结果最好的一组参数.显然,这个过程是可以通过编程封装成自动化的工作,而不是靠蛮力手动去一遍一遍的测试.为此,Sklearn提供了多种(自动化)超参调优方法(官方文档),其中网格搜索(Gr
-
Java JVM原理与调优_动力节点Java学院整理
JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的.Java虚拟机包括一套字节码指令集.一组寄存器.一个栈.一个垃圾回收堆和一个存储方法域. JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行.是运行Java应用最底层部分. JDK(Java Development kit) 整个Java的核心,包括了Java运行环境(Java Runtime E
-
Android性能调优利器StrictMode应用分析
作为Android开发,日常的开发工作中或多或少要接触到性能问题,比如我的Android程序运行缓慢卡顿,并且常常出现ANR对话框等等问题.既然有性能问题,就需要进行性能优化.正所谓工欲善其事,必先利其器.一个好的工具,可以帮助我们发现并定位问题,进而有的放矢进行解决.本文主要介绍StrictMode 在Android 应用开发中的应用和一些问题. 什么是StrictMode StrictMode意思为严格模式,是用来检测程序中违例情况的开发者工具.最常用的场景就是检测主线程中本地磁盘和网络读写
-
关于MySQL性能调优你必须了解的15个重要变量(小结)
前言: MYSQL 应该是最流行了 WEB 后端数据库.虽然 NOSQL 最近越来越多的被提到,但是相信大部分架构师还是会选择 MYSQL 来做数据存储.本文作者总结梳理MySQL性能调优的15个重要变量,又不足需要补充的还望大佬指出. 1.DEFAULT_STORAGE_ENGINE 如果你已经在用MySQL 5.6或者5.7,并且你的数据表都是InnoDB,那么表示你已经设置好了.如果没有,确保把你的表转换为InnoDB并且设置default_storage_engine为InnoDB. 为