MongoDB创建一个索引而性能提升1000倍示例代码
MongoDB 创建索引的语法
1.为普通字段添加索引,并且为索引命名
db.集合名.createIndex( {"字段名": 1 },{"name":'idx_字段名'})
说明: (1)索引命名规范:idx_<构成索引的字段名>。如果字段名字过长,可采用字段缩写。
(2)字段值后面的 1 代表升序;如是 -1 代表 降序。
2.为内嵌字段添加索引
db.集合名.createIndex({"字段名.内嵌字段名":1},{"name":'idx_字段名_内嵌字段名'})
3.通过后台创建索引
db.集合名.createIndex({"字段名":1},{"name":'idx_字段名',background:true})
4:组合索引
db.集合名.createIndex({"字段名1":-1,"字段名2":1},{"name":'idx_字段名1_字段名2',background:true})
5.设置TTL 索引
db.集合名.createIndex( { "字段名": 1 },{ "name":'idx_字段名',expireAfterSeconds: 定义的时间,background:true} )
说明 :expireAfterSeconds为过期时间(单位秒)
MongoDB创建索引性能提升1000倍
上面我们介绍了MongoDB的常见索引的创建语法。部分同学还想看看MongoDB的威力到底有多大,所以,在这儿追加一个例子,感受一下索引的性能。
通过在某一字段上创建索引,从优化前的执行15.15S到优化后降至0.013S,性能提升了1000多倍。
此为实际生产中的一个真实案例,我们有一个集合QQStatements,其数据量为2604W,如下图所示。

系统需要查询此表最近的变动情况,即需要抓取新增数据量和修改的数据量。
查询语句如下:
db.QQStatements.find({
$or:
[
{Rec_CreateTime:{$gt: ISODate("2019-01-07 16")}}
,{Rec_ModifyTime:{$gt: ISODate("2019-01-07 16")}}
]
} )
但此查询语句不理想,有时耗时25S,多次执行有缓存后也要15S左右,如下图:
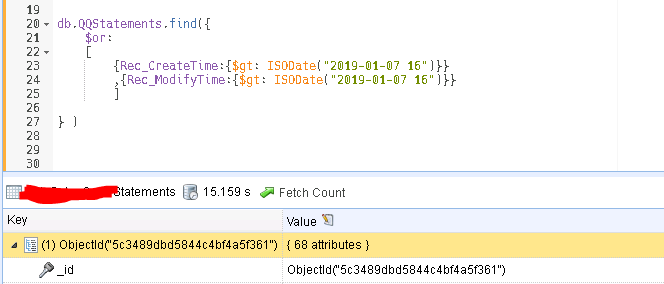
查看此表,发现Rec_CreateTime字段建有索引,单独执行符合Rec_CreateTime 条件的语句,很快 0.1 S 内就执行完成。

而Rec_ModifyTime字段没有索引,单独执行符合Rec_ModifyTime条件的语句较慢,需要15S左右。

到这儿,就可以判读出问题是缺失索引,和开发同学确认后,此场景时常用,此字段需要添加索引。
执行添加索引的命令:
db.QQStatements.createIndex({"Rec_ModifyTime":1},{"name":'idx_Rec_ModifyTime',background:true})
Rec_ModifyTime字段添加索引后,整个语句执行降至0.013S(20S-->0.02S )
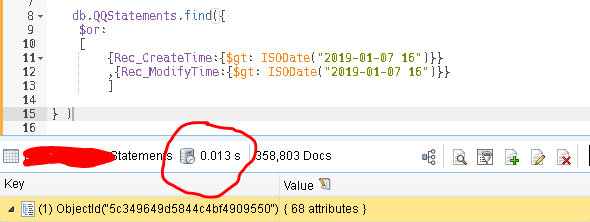
从上面可以看出在MongoDB数据库中索引很有必要,性能可以优化数百倍。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
相关推荐
-
mongodb实现数组对象求和方法实例
前言 mongodb在计算集合数组值时候,我们通常会想到使用$group与$sum,但是如果是数组里面多个json对象,并且还需要根据条件过滤多个对象的内容该如何处理? 现在让我们来实现它,假设mongodb中有个user集合,其数据内容如下: /* 1 */ { "_id" : ObjectId("5c414a6a0847e00385143003"), "date" : "2019-01-18 09", "data
-
Docker容器化部署尝试——多容器通信(node+mongoDB+nginx)
原因是这样的 想要部署一个mocker平台,就在朋友的推荐下选择了 api-mocker 这个现成的项目 该项目分为服务端node.客户端vue.以及数据库mongoDB 在尝试直接部署的时候发现需要装一大堆的环境,node.mongo.nginx啊,特别的麻烦,之前简单的使用过docker,就在想能不能用docker免环境直接部署呢?于是就有了这次的尝试 多容器通信 该项目分为3个部分,于是就要建立3个容器(node.mongo.nginx) 那容器之间怎么实现通信呢? # 通过link指令建
-

MongoDB特点与体系结构等简介
1.1什么是MongoDB MongoDB 是一个跨平台的,面向文档的数据库,是当前 NoSQL 数据库产品中最热门的一种.它介于关系数据库和非关系数据库之间,是非关系数据库当中功能最丰富,最像关系数据库的产品.它支持的数据结构非常松散,是类似JSON 的 BSON 格式,因此可以存储比较复杂的数据类型. MongoDB 的官方网站地址是:http://www.mongodb.org/ 1.2 MongoDB特点 MongoDB 最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查
-
如何优雅的在一台vps(云主机)上面部署vue+mongodb+express项目
项目: vue + express + mongodb 项目前后分离部署在一台服务器上面 express端口:3000 mongodb端口:27017 vue端口:本地是8080 服务端是:80 本地开发配置 本地开发基于vue cli 端口是 8080如果请求api的时候在前缀加上localhost:3000会提示跨域问题,我们可以使用下面方式来解决这个问题 在vue项目路径找到这个文件 /vue-item/config/index.js 找到这行代码: proxyTable: {} 添加如下
-
MongoDB中唯一索引(Unique)的那些事
写在前面 MongoDB支持的索引种类很多,诸如单键索引,复合索引,多键索引,TTL索引,文本索引,空间地理索引等.同时索引的属性可以具有唯一性,即唯一索引.唯一索引用于确保索引字段不存储重复的值,即强制索引字段的唯一性.缺省情况下,MongoDB的_id字段在创建集合的时候会自动创建一个唯一索引.本文主要描述唯一索引的用法. 关于什么是索引以及唯一索引这里就不做说明了,不清楚的可以自行谷歌或者百度.是什么引起我写这篇文章呢,这来自于之前项目中的一个问题. 我们用的是MongoDB数据存储用户信
-
c#操作mongodb插入数据效率
mongodb的数据插入速度是其一个亮点,同样的10000条数据,插入的速度要比Mysql和sqlserver都要快,当然这也是要看使用者怎么个使用法,你代码如果10000次写入使用10000次连接,那也是比不过其他数据库使用事务一次性提交的速度的. 同样,mongo也提供的一次性插入巨量数据的方法,因为mongodb没有事务这回事,所以在在C#驱动里,具体方法是InsertManyAsync()一次性插入多个文档.与之对应的是InsertOneAsync,这个是一次插入一个文档: Insert
-
mongodb的写操作
使用插入数据命令: >insert 需要注意的是,如果插入一文件(现在理解,nosql 类型的db数据不能说是记录了,它是已文件作为单位,而传统型的关系型数据库,我们说是插入一条记录),如果没有带人_id,那么会自动生成一个唯一的id,这个id好比关系型数据库里的主键一样. 如果是自己指定id,那么必须id是唯一的,这点关系型和nosql型都必须要求的: 数据字段的名字不能包含$ 和. 在敲了一阵发现,擦,我要是再shell里面去编写复杂的插入语句,就shell的这种一行一句,不搞死我去啊.我想
-
mongodb与sql关系型数据比较
摸索了几天,大体也初步算入了mongodb的门,仔细一想,mongodb和传统关系型数据库差别很大了. 传统关系型数据库中,一个数据库有一个或者多个表(Table),表中的数据是称之为记录,一行一行的,每行数据分不同的字段. 举一个容易理解的例子.一个人有姓名,性别,年龄,以及很多张银行卡: 如果使用关系型数据库,我们可能会是使用两张或者更多表来做记录,一张用户表来存用户的基本信息,另一张表通过用户id,和银行卡id,通过多条记录来存此人的多张银行卡对应关系: 那如果是在mongodb中,那就对
-
pyspark操作MongoDB的方法步骤
如何导入数据 数据可能有各种格式,虽然常见的是HDFS,但是因为在Python爬虫中数据库用的比较多的是MongoDB,所以这里会重点说说如何用spark导入MongoDB中的数据. 当然,首先你需要在自己电脑上安装spark环境,简单说下,在这里下载spark,同时需要配置好JAVA,Scala环境. 这里建议使用Jupyter notebook,会比较方便,在环境变量中这样设置 PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS=
-
mongodb使用c#驱动数据插入demo
Mongodb提供了多种开发语言的驱动,java,python,c++,c# 等,这里选用c#驱动作为测试: 首先上mongo官网下载驱动.Ps:官方网站经常连接不顺利. 还不如直接在vs的nuget管理包中搜索mongoDB.driver. 需要引入的命名空间: using MongoDB.Bson; using MongoDB.Driver; Driver是驱动核心,Bson是和数据格式相关的: 定义一个mongo客户端,一个mongodb,一个数据集合: protected staticI