Python爬虫设置代理IP(图文)
在爬虫的过程中,我们经常会遇见很多网站采取了防爬取技术,或者说因为自己采集网站信息的强度和采集速度太大,给对方服务器带去了太多的压力。
如果你一直用同一个代理ip爬取这个网页,很有可能ip会被禁止访问网页,所以基本上做爬虫的都躲不过去ip的问题。
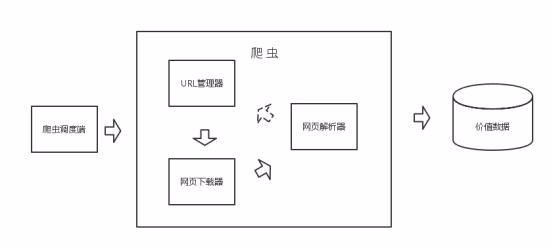
1、我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常爬取数据,一切看起来都是那么美好,然而不久之后可能会出现错误,比如 403 Forbidden,这时候你打开网页一看,可能会看到“您的 IP 访问频率太高”这样的提示。出现这种情况的原因是网站采取了一些反爬虫措施,比如,服务器会检测某个 IP 在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息,这种情况可以称为封 IP。
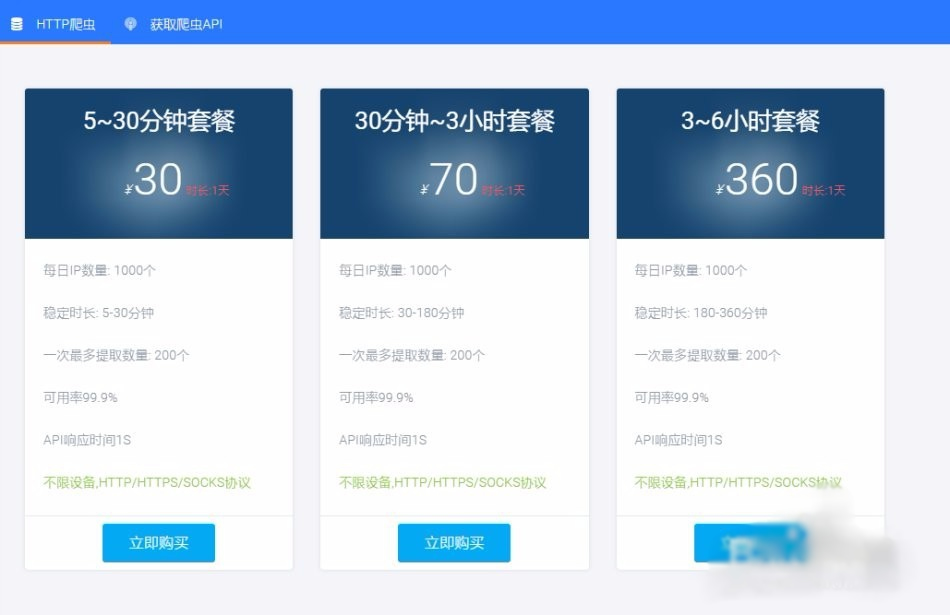
爬虫代理获取
获取IP池其实要找信的过的爬虫代理,我用的就是飞猪爬虫代理 ,优点自然就是使用率高于99%,缺点是没有免费的,0.03元一个IP,一天可以用1000个,一次可以API提取200个 。当然如果你们的用量还不满足可以加!

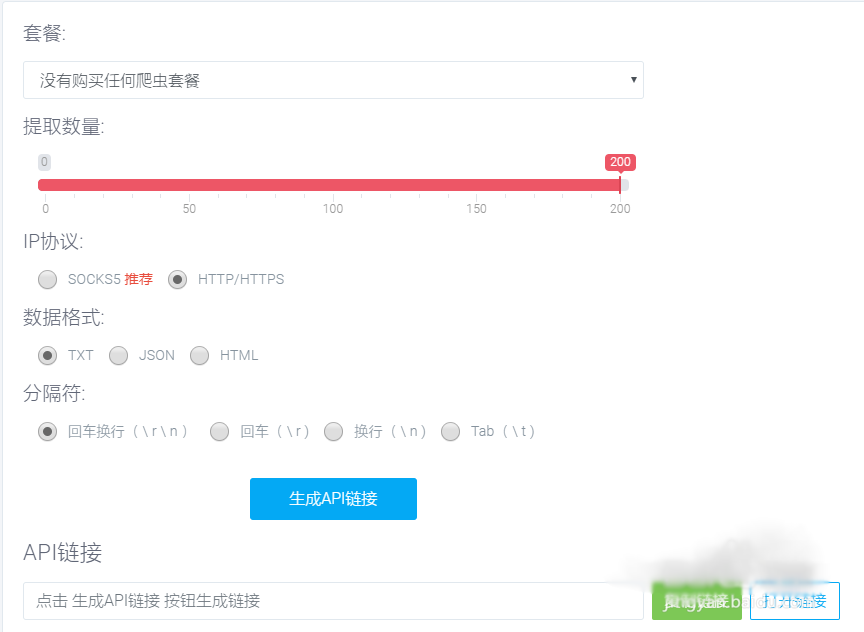
爬虫代理IP的使用
运行上面的代码会得到一个随机的proxies,把它直接传入requests的get方法中即可。


1、测试效果
本次测试得出的结论:飞猪IP爬虫代理,可用率、响应速度、稳定性、价格、安全性、使用频率,还是不错的,值得推荐
总结:以上就是关于python爬虫设置代理IP的步骤内容,感谢大家的阅读和对我们的支持。
相关推荐
-
python3 requests中使用ip代理池随机生成ip的实例
啥也不说了,直接上代码吧! # encoding:utf-8 import requests # 导入requests模块用于访问测试自己的ip import random pro = ['1.119.129.2:8080', '115.174.66.148', '113.200.214.164'] # 在(http://www.xicidaili.com/wt/)上面收集的ip用于测试 # 没有使用字典的原因是 因为字典中的键是唯一的 http 和https 只能存在一个 所以不建议使用字典
-

Python实现的异步代理爬虫及代理池
使用python asyncio实现了一个异步代理池,根据规则爬取代理网站上的免费代理,在验证其有效后存入redis中,定期扩展代理的数量并检验池中代理的有效性,移除失效的代理.同时用aiohttp实现了一个server,其他的程序可以通过访问相应的url来从代理池中获取代理. 源码 Github 环境 Python 3.5+ Redis PhantomJS(可选) Supervisord(可选) 因为代码中大量使用了asyncio的async和await语法,它们是在Python3.5中才提供
-
Python爬虫爬取新浪微博内容示例【基于代理IP】
本文实例讲述了Python爬虫爬取新浪微博内容.分享给大家供大家参考,具体如下: 用Python编写爬虫,爬取微博大V的微博内容,本文以女神的微博为例(爬新浪m站:https://m.weibo.cn/u/1259110474) 一般做爬虫爬取网站,首选的都是m站,其次是wap站,最后考虑PC站.当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选.一般m站都以m开头后接域名, 所以本文开搞的网址就是 m.weibo.cn. 前期准备 1.代理IP 网上有
-
python requests 测试代理ip是否生效
代码如下所示: import requests '''代理IP地址(高匿)''' proxy = { 'http': 'http://117.85.105.170:808', 'https': 'https://117.85.105.170:808' } '''head 信息''' head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.
-
selenium+python设置爬虫代理IP的方法
1. 背景 在使用selenium浏览器渲染技术,爬取网站信息时,一般来说,速度是很慢的.而且一般需要用到这种技术爬取的网站,反爬技术都比较厉害,对IP的访问频率应该有相当的限制.所以,如果想提升selenium抓取数据的速度,可以从两个方面出发: 第一,提高抓取频率,出现验证信息时进行破解,一般是验证码或者用户登录. 第二,使用多线程 + 代理IP, 这种方式,需要电脑有足够的内存和充足稳定的代理IP . 2. 为chrome设置代理IP from selenium import webdri
-
python实现ip代理池功能示例
本文实例讲述了python实现ip代理池功能.分享给大家供大家参考,具体如下: 爬取的代理源为西刺代理. 用xpath解析页面 用telnet来验证ip是否可用 把有效的ip写入到本地txt中.当然也可以写入到redis.mongodb中,也可以设置检测程序当代理池中的ip数不够(如:小于20个)时,启动该脚本来重新获取ip,本脚本的代码也要做相应的改变. # !/usr/bin/env python # -*- coding: utf-8 -*- # @Version : 1.0 # @Tim
-
深入理解Python爬虫代理池服务
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来.不过呢,闲暇时间手痒,所以就想利用一些免费的资源搞一个简单的代理池服务. 1.问题 代理IP从何而来? 刚自学爬虫的时候没有代理IP就去西刺.快代理之类有免费代理的网站去爬,还是有个别代理能用.当然,如果你有更好的代理接口也可以自己接入. 免费代理的采集也很简单,无非就是:访问页面页面 -> 正则/xpath提取
-
使用python验证代理ip是否可用的实现方法
在使用爬虫爬取网络数据时,如果长时间对一个网站进行抓取时可能会遇到IP被封的情况,这种情况可以使用代理更换ip来突破服务器封IP的限制. 随手在百度上搜索免费代理IP,可以得到一系列的网站,这里我们通过对西刺网站的抓取来举例. 通过编写一个爬虫来抓取网站上面的IP地址,端口,及类型,把这些信息存到本地.这里不做介绍. 验证代理IP是否可用.原理是使用代理IP访问指定网站,如果返回状态为200,表示这个代理是可以使用的. # _*_ coding:utf-8 _*_ import urllib2
-
python单例模式获取IP代理的方法详解
引言 最近在学习python,先说一下我学Python得原因,一个是因为它足够好用,完成同样的功能,代码量会比其他语言少很多,有大量的丰富的库可以使用,基本上前期根本不需要自己造什么轮子.第二个是因为目前他很火,网上各种资料都比较丰富,且质量尚可.接下来不如正题 在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术导致爬取失败.高强度.高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,这里讲述一个爬虫技巧,设置代理IP 为什么需
-
python 爬虫 批量获取代理ip的实例代码
实例如下所示: import urllib.request import os, re,sys,time try: from StringIO import StringIO except ImportError: from io import StringIO loca = re.compile(r"""ion":"\D+", "ti""") #伪装成浏览器 header = {'User-Agent':
-
Python爬虫常用小技巧之设置代理IP
设置代理IP的原因 我们在使用Python爬虫爬取一个网站时,通常会频繁访问该网站.假如一个网站它会检测某一段时间某个IP的访问次数,如果访问次数过多,它会禁止你的访问.所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理,这样便不会出现因为频繁访问而导致禁止访问的现象. 我们在学习Python爬虫的时候,也经常会遇见所要爬取的网站采取了反爬取技术导致爬取失败.高强度.高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,所以下面这篇文
-
Python3实现并发检验代理池地址的方法
本文实例讲述了Python3实现并发检验代理池地址的方法.分享给大家供大家参考,具体如下: #encoding=utf-8 #author: walker #date: 2016-04-14 #summary: 用协程/线程池并发检验代理有效性 import os, sys, time import requests from concurrent import futures cur_dir_fullpath = os.path.dirname(os.path.abspath(__file__