php实现爬取和分析知乎用户数据
背景说明:小拽利用php的curl写的爬虫,实验性的爬取了知乎5w用户的基本信息;同时,针对爬取的数据,进行了简单的分析呈现。
php的spider代码和用户dashboard的展现代码,整理后上传github,在个人博客和公众号更新代码库,程序仅供娱乐和学习交流;如果有侵犯知乎相关权益,请尽快联系本人删除。
无图无真相
移动端分析数据截图

pc端分析数据截图
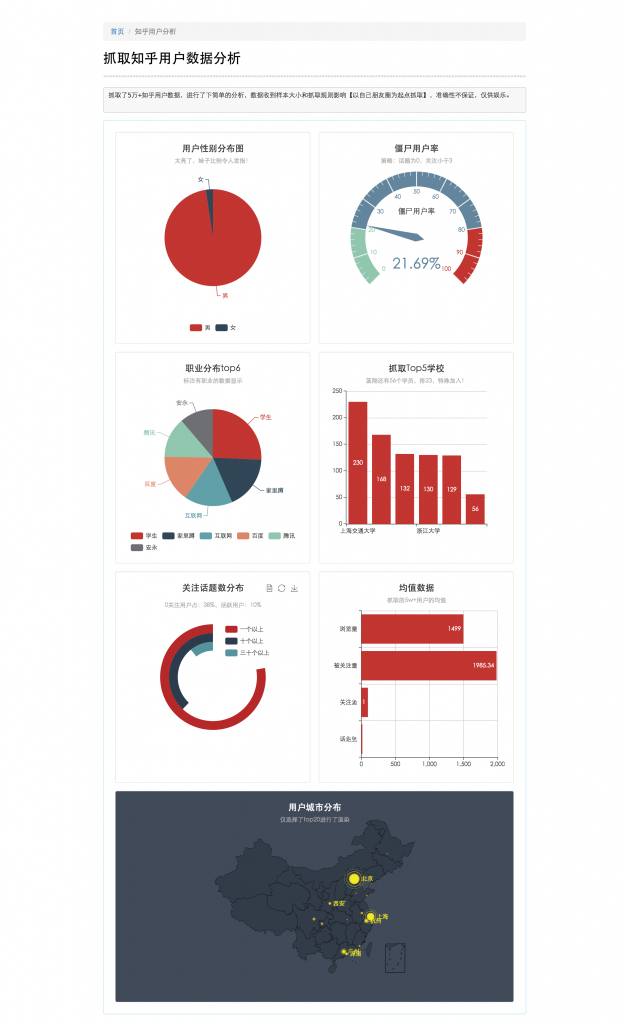
整个爬取,分析,展现过程大概分如下几步,小拽将分别介绍
- curl爬取知乎网页数据
- 正则分析知乎网页数据
- 数据数据入库和程序部署
- 数据分析和呈现
curl爬取网页数据
PHP的curl扩展是PHP支持的,允许你与各种服务器使用各种类型的协议进行连接和通信的库。是一个非常便捷的抓取网页的工具,同时,支持多线程扩展。
本程序抓取的是知乎对外提供用户访问的个人信息页面https://www.zhihu.com/people/xxx,抓取过程需要携带用户cookie才能获取页面。直接上码
获取页面cookie
// 登录知乎,打开个人中心,打开控制台,获取cookie
document.cookie
"_za=67254197-3wwb8d-43f6-94f0-fb0e2d521c31; _ga=GA1.2.2142818188.1433767929; q_c1=78ee1604225d47d08cddd8142a08288b23|1452172601000|1452172601000; _xsrf=15f0639cbe6fb607560c075269064393; cap_id="N2QwMTExNGQ0YTY2NGVddlMGIyNmQ4NjdjOTU0YTM5MmQ=|1453444256|49fdc6b43dc51f702b7d6575451e228f56cdaf5d"; __utmt=1; unlock_ticket="QUJDTWpmM0lsZdd2dYQUFBQVlRSlZUVTNVb1ZaNDVoQXJlblVmWGJ0WGwyaHlDdVdscXdZU1VRPT0=|1453444421|c47a2afde1ff334d416bafb1cc267b41014c9d5f"; __utma=51854390.21428dd18188.1433767929.1453187421.1453444257.3; __utmb=51854390.14.8.1453444425011; __utmc=51854390; __utmz=51854390.1452846679.1.dd1.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __utmv=51854390.100-1|2=registration_date=20150823=1^dd3=entry_date=20150823=1"
抓取个人中心页面
通过curl,携带cookie,先抓取本人中心页面
/**
* 通过用户名抓取个人中心页面并存储
*
* @param $username str :用户名 flag
* @return boolean :成功与否标志
*/
public function spiderUser($username)
{
$cookie = "xxxx" ;
$url_info = 'http://www.zhihu.com/people/' . $username; //此处cui-xiao-zhuai代表用户ID,可以直接看url获取本人id
$ch = curl_init($url_info); //初始化会话
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_COOKIE, $cookie); //设置请求COOKIE
curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$result = curl_exec($ch);
file_put_contents('/home/work/zxdata_ch/php/zhihu_spider/file/'.$username.'.html',$result);
return true;
}
正则分析网页数据分析新链接,进一步爬取
对于抓取过来的网页进行存储,要想进行进一步的爬取,页面必须包含有可用于进一步爬取用户的链接。通过对知乎页面分析发现:在个人中心页面中有关注人和部分点赞人和被关注人。
如下所示
// 抓取的html页面中发现了新的用户,可用于爬虫
<a class="zm-item-link-avatar avatar-link" href="/people/new-user" data-tip="p$t$new-user">
ok,这样子就可以通过自己-》关注人-》关注人的关注人-》。。。进行不断爬取。接下来就是通过正则匹配提取该信息
// 匹配到抓取页面的所有用户
preg_match_all('/\/people\/([\w-]+)\"/i', $str, $match_arr);
// 去重合并入新的用户数组,用户进一步抓取
self::$newUserArr = array_unique(array_merge($match_arr[1], self::$newUserArr));
到此,整个爬虫过程就可以顺利进行了。
如果需要大量的抓取数据,可以研究下curl_multi和pcntl进行多线程的快速抓取,此处不做赘述。
分析用户数据,提供分析
通过正则可以进一步匹配出更多的该用户数据,直接上码。
// 获取用户头像
preg_match('/<img.+src=\"?([^\s]+\.(jpg|gif|bmp|bnp|png))\"?.+>/i', $str, $match_img);
$img_url = $match_img[1];
// 匹配用户名:
// <span class="name">崔小拽</span>
preg_match('/<span.+class=\"?name\"?>([\x{4e00}-\x{9fa5}]+).+span>/u', $str, $match_name);
$user_name = $match_name[1];
// 匹配用户简介
// class bio span 中文
preg_match('/<span.+class=\"?bio\"?.+\>([\x{4e00}-\x{9fa5}]+).+span>/u', $str, $match_title);
$user_title = $match_title[1];
// 匹配性别
//<input type="radio" name="gender" value="1" checked="checked" class="male"/> 男
// gender value1 ;结束 中文
preg_match('/<input.+name=\"?gender\"?.+value=\"?1\"?.+([\x{4e00}-\x{9fa5}]+).+\;/u', $str, $match_sex);
$user_sex = $match_sex[1];
// 匹配地区
//<span class="location item" title="北京">
preg_match('/<span.+class=\"?location.+\"?.+\"([\x{4e00}-\x{9fa5}]+)\">/u', $str, $match_city);
$user_city = $match_city[1];
// 匹配工作
//<span class="employment item" title="人见人骂的公司">人见人骂的公司</span>
preg_match('/<span.+class=\"?employment.+\"?.+\"([\x{4e00}-\x{9fa5}]+)\">/u', $str, $match_employment);
$user_employ = $match_employment[1];
// 匹配职位
// <span class="position item" title="程序猿"><a href="/topic/19590046" title="程序猿" class="topic-link" data-token="19590046" data-topicid="13253">程序猿</a></span>
preg_match('/<span.+class=\"?position.+\"?.+\"([\x{4e00}-\x{9fa5}]+).+\">/u', $str, $match_position);
$user_position = $match_position[1];
// 匹配学历
// <span class="education item" title="研究僧">研究僧</span>
preg_match('/<span.+class=\"?education.+\"?.+\"([\x{4e00}-\x{9fa5}]+)\">/u', $str, $match_education);
$user_education = $match_education[1];
// 工作情况
// <span class="education-extra item" title='挨踢'>挨踢</span>
preg_match('/<span.+class=\"?education-extra.+\"?.+>([\x{4e00}-
\x{9fa5}]+)</u', $str, $match_education_extra);
$user_education_extra = $match_education_extra[1];
// 匹配关注话题数量
// class="zg-link-litblue"><strong>41 个话题</strong></a>
preg_match('/class=\"?zg-link-litblue\"?><strong>(\d+)\s.+strong>/i', $str, $match_topic);
$user_topic = $match_topic[1];
// 关注人数
// <span class="zg-gray-normal">关注了
preg_match_all('/<strong>(\d+)<.+<label>/i', $str, $match_care);
$user_care = $match_care[1][0];
$user_be_careed = $match_care[1][1];
// 历史浏览量
// <span class="zg-gray-normal">个人主页被 <strong>17</strong> 人浏览</span>
preg_match('/class=\"?zg-gray-normal\"?.+>(\d+)<.+span>/i', $str, $match_browse);
$user_browse = $match_browse[1];
在抓取的过程中,有条件的话,一定要通过redis入库,确实能提升抓取和入库效率。没有条件的话只能通过sql优化。这里来几发心德。
数据库表设计索引一定要慎重。在spider爬取的过程中,建议出了用户名,左右字段都不要索引,包括主键都不要,尽可能的提高入库效率,试想5000w的数据,每次添加一个,建立索引需要多少消耗。等抓取完毕,需要分析数据时,批量建立索引。
数据入库和更新操作,一定要批量。 mysql 官方给出的增删改的建议和速度:http://dev.mysql.com/doc/refman/5.7/en/insert-speed.html
# 官方的最优批量插入 INSERT INTO yourtable VALUES (1,2), (5,5), ...;
部署操作。程序在抓取过程中,有可能会出现异常挂掉,为了保证高效稳定,尽可能的写一个定时脚本。每隔一段时间干掉,重新跑,这样即使异常挂掉也不会浪费太多宝贵时间,毕竟,time is money。
#!/bin/bash
# 干掉
ps aux |grep spider |awk '{print $2}'|xargs kill -9
sleep 5s
# 重新跑
nohup /home/cuixiaohuan/lamp/php5/bin/php /home/cuixiaohuan/php/zhihu_spider/spider_new.php &
数据分析呈现
数据的呈现主要使用echarts 3.0,感觉对于移动端兼容还不错。兼容移动端的页面响应式布局主要通过几个简单的css控制,代码如下
// 获取用户头像
preg_match('/<img.+src=\"?([^\s]+\.(jpg|gif|bmp|bnp|png))\"?.+>/i', $str, $match_img);
$img_url = $match_img[1];
// 匹配用户名:
// <span class="name">崔小拽</span>
preg_match('/<span.+class=\"?name\"?>([\x{4e00}-\x{9fa5}]+).+span>/u', $str, $match_name);
$user_name = $match_name[1];
// 匹配用户简介
// class bio span 中文
preg_match('/<span.+class=\"?bio\"?.+\>([\x{4e00}-\x{9fa5}]+).+span>/u', $str, $match_title);
$user_title = $match_title[1];
// 匹配性别
//<input type="radio" name="gender" value="1" checked="checked" class="male"/> 男
// gender value1 ;结束 中文
preg_match('/<input.+name=\"?gender\"?.+value=\"?1\"?.+([\x{4e00}-\x{9fa5}]+).+\;/u', $str, $match_sex);
$user_sex = $match_sex[1];
// 匹配地区
//<span class="location item" title="北京">
preg_match('/<span.+class=\"?location.+\"?.+\"([\x{4e00}-\x{9fa5}]+)\">/u', $str, $match_city);
$user_city = $match_city[1];
// 匹配工作
//<span class="employment item" title="人见人骂的公司">人见人骂的公司</span>
preg_match('/<span.+class=\"?employment.+\"?.+\"([\x{4e00}-\x{9fa5}]+)\">/u', $str, $match_employment);
$user_employ = $match_employment[1];
// 匹配职位
// <span class="position item" title="程序猿"><a href="/topic/19590046" title="程序猿" class="topic-link" data-token="19590046" data-topicid="13253">程序猿</a></span>
preg_match('/<span.+class=\"?position.+\"?.+\"([\x{4e00}-\x{9fa5}]+).+\">/u', $str, $match_position);
$user_position = $match_position[1];
// 匹配学历
// <span class="education item" title="研究僧">研究僧</span>
preg_match('/<span.+class=\"?education.+\"?.+\"([\x{4e00}-\x{9fa5}]+)\">/u', $str, $match_education);
$user_education = $match_education[1];
// 工作情况
// <span class="education-extra item" title='挨踢'>挨踢</span>
preg_match('/<span.+class=\"?education-extra.+\"?.+>([\x{4e00}-
\x{9fa5}]+)</u', $str, $match_education_extra);
$user_education_extra = $match_education_extra[1];
// 匹配关注话题数量
// class="zg-link-litblue"><strong>41 个话题</strong></a>
preg_match('/class=\"?zg-link-litblue\"?><strong>(\d+)\s.+strong>/i', $str, $match_topic);
$user_topic = $match_topic[1];
// 关注人数
// <span class="zg-gray-normal">关注了
preg_match_all('/<strong>(\d+)<.+<label>/i', $str, $match_care);
$user_care = $match_care[1][0];
$user_be_careed = $match_care[1][1];
// 历史浏览量
// <span class="zg-gray-normal">个人主页被 <strong>17</strong> 人浏览</span>
preg_match('/class=\"?zg-gray-normal\"?.+>(\d+)<.+span>/i', $str, $match_browse);
$user_browse = $match_browse[1];
不足和待学习
整个过程中涉及php,shell,js,css,html,正则等语言和部署等基础知识,但还有诸多需要改进完善,小拽特此记录,后续补充例:
- php 采用multicul进行多线程。
- 正则匹配进一步优化
- 部署和抓取过程采用redis提升存储
- 移动端布局的兼容性提升
- js的模块化和sass书写css。
相关推荐
-
PHP代码实现爬虫记录——超管用
实现爬虫记录本文从创建crawler 数据库,robot.php记录来访的爬虫从而将信息插入数据库crawler,然后从数据库中就可以获得所有的爬虫信息.实现代码具体如下: 数据库设计 create table crawler ( crawler_ID bigint() unsigned not null auto_increment primary key, crawler_category varchar() not null, crawler_date datetime not null
-
PHP实现简单爬虫的方法
本文实例讲述了PHP实现简单爬虫的方法.分享给大家供大家参考.具体如下: <?php /** * 爬虫程序 -- 原型 * * 从给定的url获取html内容 * * @param string $url * @return string */ function _getUrlContent($url) { $handle = fopen($url, "r"); if ($handle) { $content = stream_get_contents($handle, 1024
-
php 向访客和爬虫显示不同的内容
听说本方法会触犯搜索引擎的一些操作原则, 有可能被被各搜索引擎处罚, 甚至删除网站. 所以我刚刚已经撤下这样的处理, 直到确定其不属于作弊. 有魄力的朋友可以继续使用, 但后果自负. 本博客的首页和存档页面以列表的形式显示文章, 在访客点击展开文章时才加载文章的内容. 因为文章的内容部分包含了大量的文字和图片, 需要大量的加载时间和流量. 尽快地向访客展示网页可以挽留大量的来访者. 而对于手机用户来说, 加载时间和流量则更为重要. 一般来说, 网站的首页是搜索引擎访问最多的页面, 应该尽可能的向
-
一个PHP实现的轻量级简单爬虫
最近需要收集资料,在浏览器上用另存为的方式实在是很麻烦,而且不利于存储和检索.所以自己写了一个小爬虫,在网上爬东西,迄今为止,已经爬了近百 万张网页.现在正在想办法着手处理这些数据. 爬虫的结构: 爬虫的原理其实很简单,就是分析下载的页面,找出其中的连接,然后再下载这些链接,再分析再下载,周而复始.在数据存储方面,数据库是首选,便于检索,而 开发语言,只要支持正则表达式就可以了,数据库我选择了mysql,所以,开发脚本我选择了php.它支持perl兼容正则表达式,连接mysql很方 便,支
-

PHP爬虫之百万级别知乎用户数据爬取与分析
这次抓取了110万的用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu: 安装PHP5.6或以上版本: 安装MySQL5.5或以上版本: 安装curl.pcntl扩展. 使用PHP的curl扩展抓取页面数据 PHP的curl扩展是PHP支持的允许你与各种服务器使用各种类型的协议进行连接和通信的库. 本程序是抓取知乎的用户数据,要能访问用户个人页面,需要用户登录后的才能访问.当我们在浏览器的页面中点击一个用户头像链接
-
php IIS日志分析搜索引擎爬虫记录程序第1/2页
使用注意: 修改iis.php文件中iis日志的绝对路径 例如:$folder="c:/windows/system32/logfiles/站点日志目录/"; //后面记得一定要带斜杠(/). ( 用虚拟空间的不懂查看你的站点绝对路径?上传个探针查看! 直接查看法:http://站点域名/iis.php 本地查看法:把日志下载到本地 http://127.0.0.1/iis.php ) 注意: //站点日志目录,注意该目录必须要有站点用户读取权限! //如果把日志下载到本地请修改143
-
php实现爬取和分析知乎用户数据
背景说明:小拽利用php的curl写的爬虫,实验性的爬取了知乎5w用户的基本信息:同时,针对爬取的数据,进行了简单的分析呈现. php的spider代码和用户dashboard的展现代码,整理后上传github,在个人博客和公众号更新代码库,程序仅供娱乐和学习交流:如果有侵犯知乎相关权益,请尽快联系本人删除. 无图无真相 移动端分析数据截图 pc端分析数据截图 整个爬取,分析,展现过程大概分如下几步,小拽将分别介绍 curl爬取知乎网页数据 正则分析知乎网页数据 数据数据入库和程序部署 数据分析
-
php爬取天猫和淘宝商品数据
一.思路 最近做了一个网站用到了从网址爬取天猫和淘宝的商品信息,首先看了下手机端的网页发现用的react,不太了解没法搞,所以就考虑从PC入口爬取数据,但是当爬取URL获取数据时并没有获取价格,库存等的信息,仔细研究了下发现是异步请求了另一个接口,但是接口要使用refer才能获取数据,于是就通过以下方式写了一个简单的爬虫,用于爬取商品预览图和商品的第一个分类的价格.库存等. 二.实现 代码如下: function crawlUrl($url){ import('PhpQuery.Curl');
-
百万级别知乎用户数据抓取与分析之PHP开发
这次抓取了110万的用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu: 安装PHP5.6或以上版本: 安装curl.pcntl扩展. 使用PHP的curl扩展抓取页面数据 PHP的curl扩展是PHP支持的允许你与各种服务器使用各种类型的协议进行连接和通信的库. 本程序是抓取知乎的用户数据,要能访问用户个人页面,需要用户登录后的才能访问.当我们在浏览器的页面中点击一个用户头像链接进入用户个人中心页面的时候,之所以
-
Python爬虫小练习之爬取并分析腾讯视频m3u8格式
目录 普通爬虫正常流程: 环境介绍 分析网站 开始代码 导入模块 数据请求 提取数据 遍历 保存数据 运行代码 普通爬虫正常流程: 数据来源分析 发送请求 获取数据 解析数据 保存数据 环境介绍 python 3.8 pycharm 2021专业版 [付费VIP完整版]只要看了就能学会的教程,80集Python基础入门视频教学 点这里即可免费在线观看 分析网站 先打开开发者工具,然后搜索m3u8,会返回给你很多的ts的文件,像这种ts文件,就是视频的片段 我们可以复制url地址,在新的浏览页打开
-
Python实现微信好友数据爬取及分析
前言 随着微信的普及,越来越多的人开始使用微信.微信渐渐从一款单纯的社交软件转变成了一个生活方式,人们的日常沟通需要微信,工作交流也需要微信.微信里的每一个好友,都代表着人们在社会里扮演的不同角色. 今天这篇文章会基于Python对微信好友进行数据分析,这里选择的维度主要有:性别.头像.签名.位置,主要采用图表和词云两种形式来呈现结果,其中,对文本类信息会采用词频分析和情感分析两种方法.常言道:工欲善其事,必先利其器也.在正式开始这篇文章前,简单介绍下本文中使用到的第三方模块: itchat:微
-
python爬虫爬取股票的北上资金持仓数据
目录 前言 数据分析 数据抓取 建立模型 总结 前言 前面已经讲述了如何获取股票的k线数据,今天我们来分析一下股票的资金流入情况,股票的上涨和下跌都是由资金推动的,这其中的北上资金就是一个风向标,今天就抓取一下北上资金对股票的逐天持仓变动和资金变动. 数据分析 照例先贴一下数据的访问地址: # 以海尔智家为例贴一下数据的页面连接地址,再次吐槽一下拼音前缀 https://data.eastmoney.com/hsgtcg/StockHdStatistics/600690.html 下图就是北上资
-
Python爬取商家联系电话以及各种数据的方法
上次学会了爬取图片,这次就想着试试爬取商家的联系电话,当然,这里纯属个人技术学习,爬取过后及时删除,不得用于其它违法用途,一切后果自负. 首先我学习时用的是114黄页数据. 下面四个是用到的模块,前面2个需要安装一下,后面2个是python自带的. import requests from bs4 import BeautifulSoup import csv import time 然后,写个函数获取到页面种想要的数据,记得最后的return返回一下,因为下面的函数要到把数据写到csv里面.
-
python爬虫实现爬取同一个网站的多页数据的实例讲解
对于一个网站的图片.文字音视频等,如果我们一个个的下载,不仅浪费时间,而且很容易出错.Python爬虫帮助我们获取需要的数据,这个数据是可以快速批量的获取.本文小编带领大家通过python爬虫获取获取总页数并更改url的方法,实现爬取同一个网站的多页数据. 一.爬虫的目的 从网上获取对你有需要的数据 二.爬虫过程 1.获取url(网址). 2.发出请求,获得响应. 3.提取数据. 4.保存数据. 三.爬虫功能 可以快速批量的获取想要的数据,不用手动的一个个下载(图片.文字音视频等) 四.使用py
-
用C#+Selenium+ChromeDriver爬取网页(模拟真实的用户浏览行为)
以下文章来源于公众号:DotNetCore实战 1.背景 Selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.而对于爬虫来说,使用Selenium操控浏览器来爬取网上的数据那么肯定是爬虫中的杀手武器.这里,我将介绍selenium + 谷歌浏览器的一般使用. 2.需求 在平常的爬虫开发中,有时候网页是一堆js堆起来的代码,涉及很多异步计算,如果是普通的http 控制台请求,那么得到的源文件是一堆js ,需要自己在去组装数据,很费力