python机器学习之贝叶斯分类
一、贝叶斯分类介绍
贝叶斯分类器是一个统计分类器。它们能够预测类别所属的概率,如:一个数据对象属于某个类别的概率。贝叶斯分类器是基于贝叶斯定理而构造出来的。对分类方法进行比较的有关研究结果表明:简单贝叶斯分类器(称为基本贝叶斯分类器)在分类性能上与决策树和神经网络都是可比的。在处理大规模数据库时,贝叶斯分类器已表现出较高的分类准确性和运算性能。基本贝叶斯分类器假设一个指定类别中各属性的取值是相互独立的。这一假设也被称为:类别条件独立,它可以帮助有效减少在构造贝叶斯分类器时所需要进行的计算。
二、贝叶斯定理
p(A|B) 条件概率 表示在B发生的前提下,A发生的概率;

基本贝叶斯分类器通常都假设各类别是相互独立的,即各属性的取值是相互独立的。对于特定的类别且其各属性相互独立,就会有:
P(AB|C) = P(A|C)*P(B|C)
三、贝叶斯分类案例
1.分类属性是离散
假设有样本数为6个的训练集数字如下:
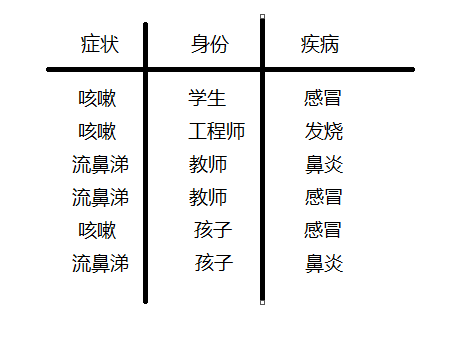
现在假设来又来了一个人是症状为咳嗽的教师,那这位教师是患上感冒、发烧、鼻炎的概率分别是多少呢?这个问题可以用贝叶斯分类来解决,最后三个疾病哪个概率高,就把这个咳嗽的教师划为哪个类,实质就是分别求p(感冒|咳嗽*教师)和P(发烧 | 咳嗽 * 教师)
P(鼻炎 | 咳嗽 * 教师) 的概率;
假设各个类别相互独立:

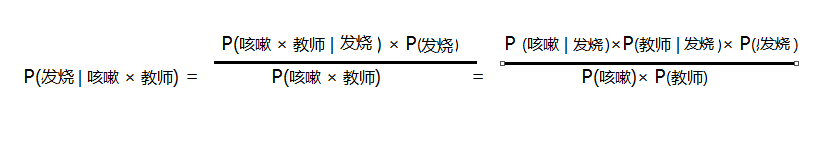

P(感冒)=3/6 P(发烧)=1/6 P(鼻炎)=2/6
p(咳嗽) = 3/6 P(教师)= 2/6
p(咳嗽 | 感冒) = 2/3 P(教师 | 感冒) = 1/3
故
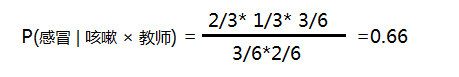
按以上方法可分别求 P(发烧 | 咳嗽 × 教师) 和P(鼻炎 |咳嗽 × 教师 )的概率;
2.分类属性连续
如果按上面的样本上加一个年龄的属性;因为年龄是连续,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算;这时,可以假设感冒、发烧、鼻炎分类的年龄都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数;
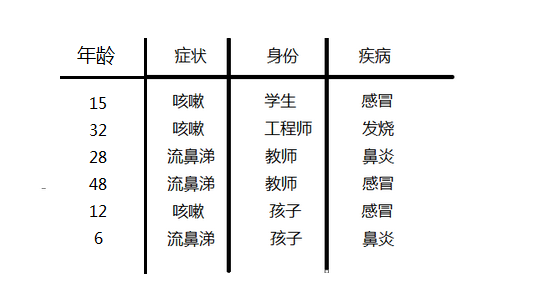
下面就以求P(年龄=15|感冒)下的概率为例说明:
第一:求在感冒类下的年龄平均值 u=(15+48+12)/3=25
第二:求在感冒类下年龄的方差 代入下面公司可求:方差=266
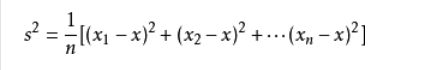
第三:把年龄=15 代入正太分布公式如下:参数代进去既可以求的P(age=15|感冒)的概率
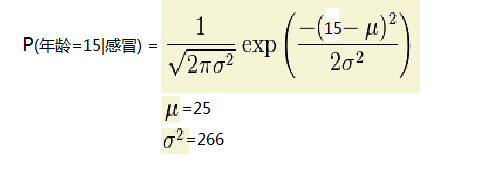
其他属性按离散方法可求;
四、概率值为0处理
假设有这种情况出现,在训练集上感冒的元祖有10个,有0个是孩子,有6个是学生,有4个教师;当分别求
P(孩子|感冒) =0; P(学生|感冒)=6/10 ; P(教师|感冒)=4/10 ;出现了概率为0的现象,为了避免这个现象,在假设训练元祖数量大量的前提下,可以使用拉普拉斯估计法,把每个类型加1这样可求的分别概率是
P(孩子|感冒) = 1/13 ; P(学生|感冒) = 7/13 ; P(教师|感冒)=4/13
五、垃圾邮件贝叶斯分类案例
1.准备训练集数据
假设postingList为一个六个邮件内容,classVec=[0,1,0,1,0,1]为邮件类型,设1位垃圾邮件
def loadDataSet():
postingList =[['my','dog','has',' flea','problems','help','please'],
['mybe','not','take','him','to','dog','park','stupid'],
['my','dalmation','is','so','cute','i','love','hime'],
['stop','posting','stupid','worthless','garbage'],
['mr','licks','ate','my','steak','how','to','stop','hime'],
['quit','buying','worthless','dog','food','stupid','quit']]
classVec =[0,1,0,1,0,1]
return postingList,classVec
2.根据所有的邮件内容创建一个所有单词集合
def createVocabList(dataSet): vocabSet =set([]) for document in dataSet: vocabSet = vocabSet | set(document) return list(vocabSet)
测试后获取所有不重复单词的集合见下一共:

3.根据2部所有不重复的单词集合对每个邮件内容向量化
def bagOfWords2VecMN(vocabList,inputSet): returnVec =[0]*len(vocabList) for word in inputSet: returnVec[vocabList.index(word)] +=1 return returnVec
测试后可得如下,打印内容为向量化的六个邮件内容
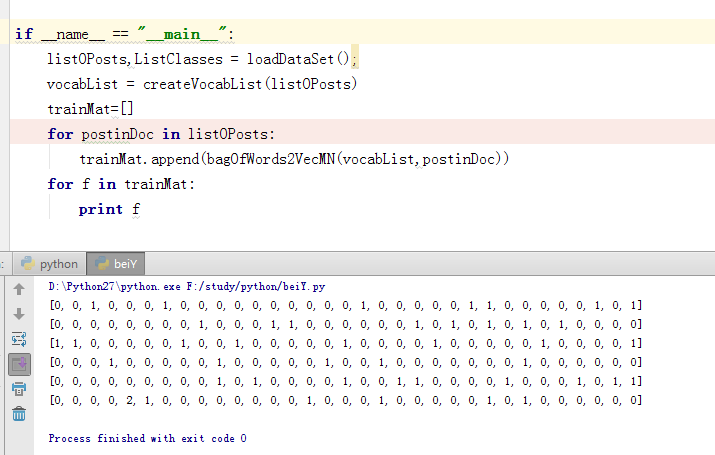
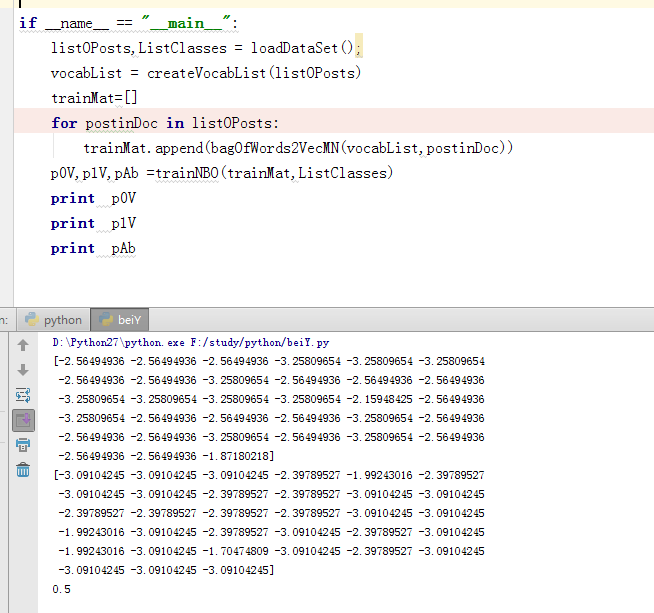
4.训练模型,此时就是分别求p(垃圾|文档) = p(垃圾)*p(文档|垃圾)/p(文档)
def trainNBO(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords =len(trainMatrix[0])
#计算p(垃圾)的概率
pAbusive = sum(trainCategory)/float(numTrainDocs)
#为了防止一个概率为0,假设都有一个
p0Num =ones(numWords);
p1Num = ones(numWords)
p0Denom =2.0;p1Denom=2.0;
for i in range(numTrainDocs):
if trainCategory[i] ==1:
p1Num +=trainMatrix[i]
p1Denom +=sum(trainMatrix[i])
else:
p0Num +=trainMatrix[i]
p0Denom +=sum(trainMatrix[i])
p1Vect = np.log((p1Num/p1Denom))
p0Vect = np.log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
对训练模型进行测试结果如下:
5.定义分类方法
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 =sum(vec2Classify * p1Vec) +math.log(pClass1)
p0 = sum(vec2Classify * p0Vec)+math.log(1.0-pClass1)
if p1>p0:
return 1
else:
return 0
6.以上分类完成,下面就对其进行测试,测试方法如下:
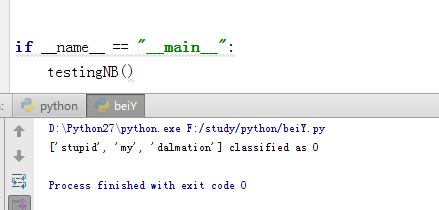
def testingNB():
listOPosts,ListClasses = loadDataSet();
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(bagOfWords2VecMN(myVocabList,postinDoc))
p0V,p1V,pAb =trainNBO(trainMat,ListClasses)
testEntry =['stupid','my','dalmation']
thisDoc = array(bagOfWords2VecMN(myVocabList,testEntry))
print testEntry,'classified as',classifyNB(thisDoc,p0V,p1V,pAb)
结果如下:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python实现的朴素贝叶斯分类器示例
- 用Python从零实现贝叶斯分类器的机器学习的教程
相关推荐
-

用Python从零实现贝叶斯分类器的机器学习的教程
朴素贝叶斯算法简单高效,在处理分类问题上,是应该首先考虑的方法之一. 通过本教程,你将学到朴素贝叶斯算法的原理和Python版本的逐步实现. 更新:查看后续的关于朴素贝叶斯使用技巧的文章"Better Naive Bayes: 12 Tips To Get The Most From The Naive Bayes Algorithm" 朴素贝叶斯分类器,Matt Buck保留部分版权 关于朴素贝叶斯 朴素贝叶斯算法是一个直观的方法,使用每个属性归属于某个类的概率来做预测.你可以使用这
-
Python实现的朴素贝叶斯分类器示例
本文实例讲述了Python实现的朴素贝叶斯分类器.分享给大家供大家参考,具体如下: 因工作中需要,自己写了一个朴素贝叶斯分类器. 对于未出现的属性,采取了拉普拉斯平滑,避免未出现的属性的概率为零导致整个条件概率都为零的情况出现. 朴素贝叶斯的基本原理网上很容易查到,这里不再叙述,直接附上代码 因工作中需要,自己写了一个朴素贝叶斯分类器.对于未出现的属性,采取了拉普拉斯平滑,避免未出现的属性的概率为零导致整个条件概率都为零的情况出现. class NBClassify(object): def _
-
python机器学习之贝叶斯分类
一.贝叶斯分类介绍 贝叶斯分类器是一个统计分类器.它们能够预测类别所属的概率,如:一个数据对象属于某个类别的概率.贝叶斯分类器是基于贝叶斯定理而构造出来的.对分类方法进行比较的有关研究结果表明:简单贝叶斯分类器(称为基本贝叶斯分类器)在分类性能上与决策树和神经网络都是可比的.在处理大规模数据库时,贝叶斯分类器已表现出较高的分类准确性和运算性能.基本贝叶斯分类器假设一个指定类别中各属性的取值是相互独立的.这一假设也被称为:类别条件独立,它可以帮助有效减少在构造贝叶斯分类器时所需要进行的计算. 二.
-
python 机器学习之实现朴素贝叶斯算法的示例
特点 这是分类算法贝叶斯算法的较为简单的一种,整个贝叶斯分类算法的核心就是在求解贝叶斯方程P(y|x)=[P(x|y)P(y)]/P(x) 而朴素贝叶斯算法就是在牺牲一定准确率的情况下强制特征x满足独立条件,求解P(x|y)就更为方便了 但基本上现实生活中,没有任何关系的两个特征几乎是不存在的,故朴素贝叶斯不适合那些关系密切的特征 from collections import defaultdict import numpy as np from sklearn.datasets import
-
Python机器学习入门(五)算法审查
目录 1.审查分类算法 1.1线性算法审查 1.1.1逻辑回归 1.1.2线性判别分析 1.2非线性算法审查 1.2.1K近邻算法 1.2.2贝叶斯分类器 1.2.4支持向量机 2.审查回归算法 2.1线性算法审查 2.1.1线性回归算法 2.1.2岭回归算法 2.1.3套索回归算法 2.1.4弹性网络回归算法 2.2非线性算法审查 2.2.1K近邻算法 2.2.2分类与回归树 2.2.3支持向量机 3.算法比较 总结 程序测试是展现BUG存在的有效方式,但令人绝望的是它不足以展现其缺位. --
-
Python机器学习NLP自然语言处理基本操作新闻分类
目录 概述 TF-IDF 关键词提取 TF IDF TF-IDF TfidfVectorizer 数据介绍 代码实现 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. TF-IDF 关键词提取 TF-IDF (Term Frequency-Inverse Document Frequency), 即词频-逆文件频率是一种用于信息检索与数据挖掘的常用加权技术. TF-IDF 可以帮助我
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
Python机器学习应用之朴素贝叶斯篇
朴素贝叶斯(Naive Bayes,NB):朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一.朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等. 1.鸢尾花案例 #%%库函数导入 import warnings warnings.filterwarnings('ignore') import numpy as np # 加载莺尾花数据集 from sklearn import datasets # 导入高斯朴素贝叶斯分类器 from sklearn.naive_b
-
Python机器学习入门(五)之Python算法审查
目录 1.审查分类算法 1.1线性算法审查 1.1.1逻辑回归 1.1.2线性判别分析 1.2非线性算法审查 1.2.1K近邻算法 1.2.2贝叶斯分类器 1.2.3分类与回归树 1.2.4支持向量机 2.审查回归算法 2.1线性算法审查 2.1.1线性回归算法 2.1.2岭回归算法 2.1.3套索回归算法 2.1.4弹性网络回归算法 2.2非线性算法审查 2.2.1K近邻算法 2.2.2分类与回归树 2.2.3支持向量机 3.算法比较 总结 程序测试是展现BUG存在的有效方式,但令人绝望的是它
-
python机器学习库常用汇总
汇总整理一套Python网页爬虫,文本处理,科学计算,机器学习和数据挖掘的兵器谱. 1. Python网页爬虫工具集 一个真实的项目,一定是从获取数据开始的.无论文本处理,机器学习和数据挖掘,都需要数据,除了通过一些渠道购买或者下载的专业数据外,常常需要大家自己动手爬数据,这个时候,爬虫就显得格外重要了,幸好,Python提供了一批很不错的网页爬虫工具框架,既能爬取数据,也能获取和清洗数据,也就从这里开始了: 1.1 Scrapy 鼎鼎大名的Scrapy,相信不少同学都有耳闻,课程图谱中的很多课
-
Python机器学习logistic回归代码解析
本文主要研究的是Python机器学习logistic回归的相关内容,同时介绍了一些机器学习中的概念,具体如下. Logistic回归的主要目的:寻找一个非线性函数sigmod最佳的拟合参数 拟合.插值和逼近是数值分析的三大工具 回归:对一直公式的位置参数进行估计 拟合:把平面上的一些系列点,用一条光滑曲线连接起来 logistic主要思想:根据现有数据对分类边界线建立回归公式.以此进行分类 sigmoid函数:在神经网络中它是所谓的激励函数.当输入大于0时,输出趋向于1,输入小于0时,输出趋向0
-
python机器学习案例教程——K最近邻算法的实现
K最近邻属于一种分类算法,他的解释最容易,近朱者赤,近墨者黑,我们想看一个人是什么样的,看他的朋友是什么样的就可以了.当然其他还牵着到,看哪方面和朋友比较接近(对象特征),怎样才算是跟朋友亲近,一起吃饭还是一起逛街算是亲近(距离函数),根据朋友的优秀不优秀如何评判目标任务优秀不优秀(分类算法),是否不同优秀程度的朋友和不同的接近程度要考虑一下(距离权重),看几个朋友合适(k值),能否以分数的形式表示优秀度(概率分布). K最近邻概念: 它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并