C语言正则表达式详解 regcomp() regexec() regfree()用法详解
标准的C和C++都不支持正则表达式,但有一些函数库可以辅助C/C++程序员完成这一功能,其中最著名的当数Philip Hazel的Perl-Compatible Regular Expression库,许多Linux发行版本都带有这个函数库。
C语言处理正则表达式常用的函数有regcomp()、regexec()、regfree()和regerror(),一般分为三个步骤,如下所示:
- C语言中使用正则表达式一般分为三步:
-
- 编译正则表达式 regcomp()
- 匹配正则表达式 regexec()
- 释放正则表达式 regfree()
下边是对三个函数的详细解释
1、int regcomp (regex_t *compiled, const char *pattern, int cflags)
这个函数把指定的正则表达式pattern编译成一种特定的数据格式compiled,这样可以使匹配更有效。函数regexec 会使用这个数据在目标文本串中进行模式匹配。执行成功返回0。
参数说明:
①regex_t 是一个结构体数据类型,用来存放编译后的正则表达式,它的成员re_nsub 用来存储正则表达式中的子正则表达式的个数,子正则表达式就是用圆括号包起来的部分表达式。
②pattern 是指向我们写好的正则表达式的指针。
③cflags 有如下4个值或者是它们或运算(|)后的值:
REG_EXTENDED 以功能更加强大的扩展正则表达式的方式进行匹配。
REG_ICASE 匹配字母时忽略大小写。
REG_NOSUB 不用存储匹配后的结果。
REG_NEWLINE 识别换行符,这样'$'就可以从行尾开始匹配,'^'就可以从行的开头开始匹配。
2. int regexec (regex_t *compiled, char *string, size_t nmatch, regmatch_t matchptr [], int eflags)
当我们编译好正则表达式后,就可以用regexec 匹配我们的目标文本串了,如果在编译正则表达式的时候没有指定cflags的参数为REG_NEWLINE,则默认情况下是忽略换行符的,也就是把整个文本串当作一个字符串处理。执行成功返回0。
regmatch_t 是一个结构体数据类型,在regex.h中定义:
typedef struct
{
regoff_t rm_so;
regoff_t rm_eo;
} regmatch_t;
成员rm_so 存放匹配文本串在目标串中的开始位置,rm_eo 存放结束位置。通常我们以数组的形式定义一组这样的结构。因为往往我们的正则表达式中还包含子正则表达式。数组0单元存放主正则表达式位置,后边的单元依次存放子正则表达式位置。
参数说明:
①compiled 是已经用regcomp函数编译好的正则表达式。
②string 是目标文本串。
③nmatch 是regmatch_t结构体数组的长度。
④matchptr regmatch_t类型的结构体数组,存放匹配文本串的位置信息。
⑤eflags 有两个值
REG_NOTBOL 按我的理解是如果指定了这个值,那么'^'就不会从我们的目标串开始匹配。总之我到现在还不是很明白这个参数的意义;
REG_NOTEOL 和上边那个作用差不多,不过这个指定结束end of line。
3. void regfree (regex_t *compiled)
当我们使用完编译好的正则表达式后,或者要重新编译其他正则表达式的时候,我们可以用这个函数清空compiled指向的regex_t结构体的内容,请记住,如果是重新编译的话,一定要先清空regex_t结构体。
4. size_t regerror (int errcode, regex_t *compiled, char *buffer, size_t length)
当执行regcomp 或者regexec 产生错误的时候,就可以调用这个函数而返回一个包含错误信息的字符串。
参数说明:
①errcode 是由regcomp 和 regexec 函数返回的错误代号。
②compiled 是已经用regcomp函数编译好的正则表达式,这个值可以为NULL。
③buffer 指向用来存放错误信息的字符串的内存空间。
④length 指明buffer的长度,如果这个错误信息的长度大于这个值,则regerror 函数会自动截断超出的字符串,但他仍然会返回完整的字符串的长度。所以我们可以用如下的方法先得到错误字符串的长度。
size_t length = regerror (errcode, compiled, NULL, 0);
下边是一个匹配Email例子,按照上面的三步就可以。
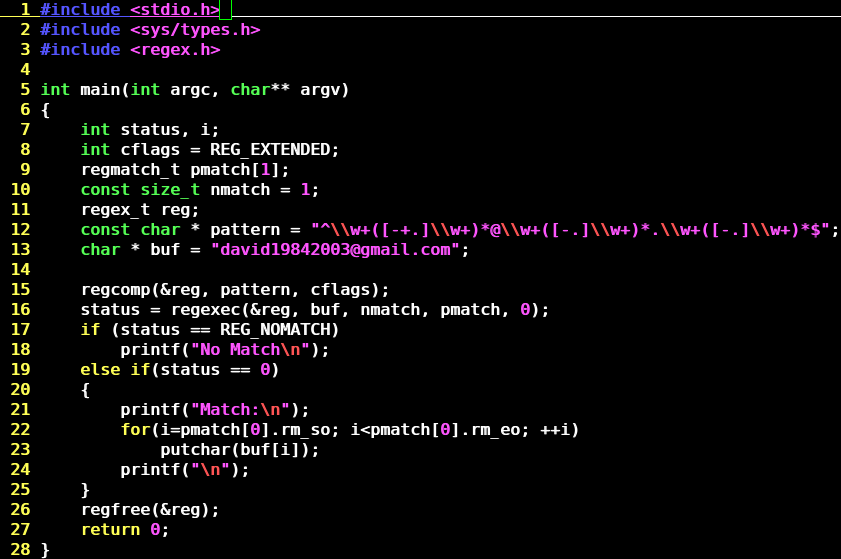
下面的程序负责从命令行获取正则表达式,然后将其运用于从标准输入得到的每行数据,并打印出匹配结果。
#include <stdio.h>
#include <sys/types.h>
#include <regex.h>
/* 取子串的函数 */
static char* substr(const char*str,
unsigned start, unsigned end)
{
unsigned n = end - start;
static char stbuf[256];
strncpy(stbuf, str + start, n);
stbuf[n] = 0;
return stbuf;
}
/* 主程序 */
int main(int argc, char** argv)
{
char * pattern;
int x, z, lno = 0, cflags = 0;
char ebuf[128], lbuf[256];
regex_t reg;
regmatch_t pm[10];
const size_t nmatch = 10;
/* 编译正则表达式*/
pattern = argv[1];
z = regcomp(?, pattern, cflags);
if (z != 0){
regerror(z, ?, ebuf, sizeof(ebuf));
fprintf(stderr, "%s: pattern '%s' \n",ebuf, pattern);
return 1;
}
/* 逐行处理输入的数据 */
while(fgets(lbuf, sizeof(lbuf), stdin))
{
++lno;
if ((z = strlen(lbuf)) > 0 && lbuf[z-1] == '\n')
lbuf[z - 1] = 0;
/* 对每一行应用正则表达式进行匹配 */
z = regexec(?, lbuf, nmatch, pm, 0);
if (z == REG_NOMATCH) continue;
else if (z != 0) {
regerror(z, ?, ebuf, sizeof(ebuf));
fprintf(stderr, "%s: regcom('%s')\n", ebuf, lbuf);
return 2;
}
/* 输出处理结果 */
for (x = 0; x < nmatch && pm[x].rm_so != -1; ++ x)
{
if (!x) printf("%04d: %s\n", lno, lbuf);
printf(" $%d='%s'\n", x, substr(lbuf, pm[x].rm_so, pm[x].rm_eo));
}
}
/* 释放正则表达式 */
regfree(?);
return 0;
}
执行下面的命令可以编译并执行该程序:
# gcc regexp.c -o regexp # ./regexp 'regex[a-z]*' < regexp.c 0003: #include <regex.h> $0='regex' 0027: regex_t reg; $0='regex' 0054: z = regexec(?, lbuf, nmatch, pm, 0); $0='regexec'
小结:对那些需要进行复杂数据处理的程序来说,正则表达式无疑是一个非常有用的工具。本文重点在于阐述如何在C语言中利用正则表达式来简化字符串处理,以便在数据处理方面能够获得与Perl语言类似的灵活性。
相关推荐
-
C语言正则表达式详解 regcomp() regexec() regfree()用法详解
标准的C和C++都不支持正则表达式,但有一些函数库可以辅助C/C++程序员完成这一功能,其中最著名的当数Philip Hazel的Perl-Compatible Regular Expression库,许多Linux发行版本都带有这个函数库. C语言处理正则表达式常用的函数有regcomp().regexec().regfree()和regerror(),一般分为三个步骤,如下所示: C语言中使用正则表达式一般分为三步: 编译正则表达式 regcomp() 匹配正则表达式 regexec() 释
-
Python正则表达式中group与groups的用法详解
目录 1 .group函数 1.1 返回整个匹配结果 1.2 返回指定分组的匹配结果 1.3 处理没有匹配结果的情况 2. groups函数 3. group和groups的使用场景 在Python中,正则表达式的group和groups方法是非常有用的函数,用于处理匹配结果的分组信息.group方法是re.MatchObject类中的一个函数,用于返回匹配对象的整个匹配结果或特定的分组匹配结果.而groups方法同样是re.MatchObject类中的函数,它返回的是所有分组匹配结果组成的元组
-
Node.js API详解之 console模块用法详解
本文实例讲述了Node.js API详解之 console模块用法.分享给大家供大家参考,具体如下: console模块简介 说明: console 模块提供了一个简单的调试控制台,类似于 Web 浏览器提供的 JavaScript 控制台. console 模块导出了两个特定的组件: 一个 Console 类,包含 console.log() . console.error() 和 console.warn() 等方法,可以被用于写入到任何 Node.js 流. 一个全局的 console 实
-
Node.js API详解之 readline模块用法详解
本文实例讲述了Node.js API详解之 readline模块用法.分享给大家供大家参考,具体如下: Node.js API详解之 readline readline 模块提供了一个接口,用于从可读流(如 process.stdin)读取数据,每次读取一行. 它可以通过以下方式使用: const readline = require('readline'); readline 模块的基本用法: const readline = require('readline'); const rl = r
-
java中DecimalFormat四舍五入用法详解
DecimalFormat 是 NumberFormat 的一个具体子类,用于格式化十进制数字.它可以支持不同类型的数,包括整数 (123).定点数 (123.4).科学记数法表示的数 (1.23E4).百分数 (12%) 和金额 ($123)这些内容的本地化. 下边先介绍下DecimalFormat的用法: import java.text.*; import java.util.*; public class DecimalFormatDemo { public static void ma
-

java.text.DecimalFormat用法详解
简要 DecimalFormat 的 pattern 都包含着 正负子 pattern ,例如 "#,##0.00;(#,##0.00)": /** * Created by Shuai on 2016/7/11. */ public class Main { public static void main(String[] args) { // 正值 BigDecimal bigDecimal = BigDecimal.valueOf(-12211151515151.541666);
-
DecimalFormat数字格式化用法详解
DecimalFormat 是 NumberFormat 的一个具体子类,用于格式化十进制数字. DecimalFormat 包含一个模式 和一组符号 符号含义: 下列字符用在非本地化的模式中.已本地化的模式使用从此 formatter 的 DecimalFormatSymbols 对象中获得的相应字符,这些字符已失去其特殊状态.两种例外是货币符号和引号,不将其本地化. import java.text.DecimalFormat; public class TestDecimalFormat
-
DecimalFormat多种用法详解
NumberFormat.getInstance()方法返回NumberFormat的一个实例(实际上是NumberFormat具体的一个子类,例如DecimalFormat), 这适合根据本地设置格式化一个数字.你也可以使用非缺省的地区设置,例如德国.然后格式化方法根据特定的地区规则格式化数字.这个程序也可以使用一个简单的形式: NumberFormat.getInstance().format(1234.56) 但是保存一个格式然后重用更加有效.国际化是格式化数字时的一个大问题. 另一个是对
-
Go语言正则表达式的使用详解
正则表达式是一种进行模式匹配和文本操纵的功能强大的工具.正则表达式灵活.易用,按照它的语法规则,随需构造出的匹配模式就能够从原始文本中筛选出几乎任何你想要得到的字符组合. 准则 默认是最短匹配,只要字符串满足条件就返回. 如果没有匹配到,都是返回为nil. 如果需要做最长匹配,调用Longest()函数. 正则表达式功能:匹配(macth),查找(find)和替换(replace). 存在长度选择的函数,传入<0的数字表示匹配全部. 使用regexp调用 Match,MatchReader和 M
-
oracle sql语言模糊查询--通配符like的使用教程详解
oracle在Where子句中,可以对datetime.char.varchar字段类型的列用Like子句配合通配符选取那些"很像..."的数据记录,以下是可使用的通配符: % 零或者多个字符 _ 单一任何字符(下划线) \ 特殊字符 oracle10g以上支持正则表达式的函数主要有下面四个: 1,REGEXP_LIKE :与LIKE的功能相似 2,REGEXP_INSTR :与INSTR的功能相似 3,REGEXP_SUBSTR :与SUBSTR的功能相似 4,RE