C语言实现最小生成树构造算法
最小生成树
最小生成树(minimum spanning tree)是由n个顶点,n-1条边,将一个连通图连接起来,且使权值最小的结构。
最小生成树可以用Prim(普里姆)算法或kruskal(克鲁斯卡尔)算法求出。
我们将以下面的带权连通图为例讲解这两种算法的实现:

注:由于测试输入数据较多,程序可以采用文件输入

Prim(普里姆)算法
时间复杂度:O(N^2)(N为顶点数)
prim算法又称“加点法”,用于边数较多的带权无向连通图
方法:每次找与之连线权值最小的顶点,将该点加入最小生成树集合中
注意:相同权值任选其中一个即可,但是不允许出现闭合回路的情况。
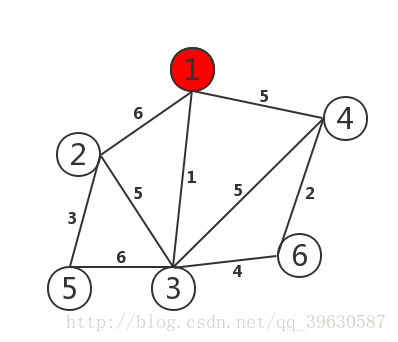



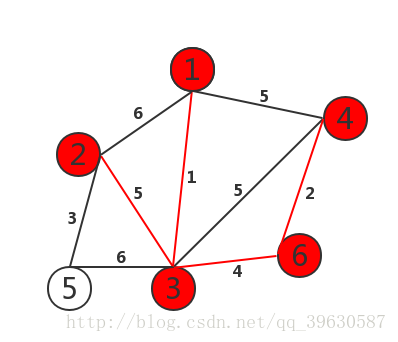

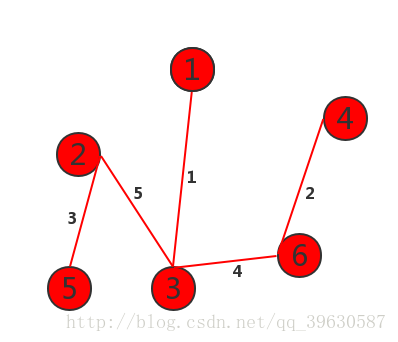
代码部分通过以下步骤可以得到最小生成树:
1.初始化:
lowcost[i]:表示以i为终点的边的最小权值,当lowcost[i]=0表示i点加入了MST。
mst[i]:表示对应lowcost[i]的起点,当mst[i]=0表示起点i加入MST。
由于我们规定最开始的顶点是1,所以lowcost[1]=0,MST[1]=0。即只需要对2~n进行初始化即可。
#define MAX 100
#define MAXCOST 0x7fffffff
int graph[MAX][MAX];
void prim(int graph[][MAX], int n)
{
int lowcost[MAX];
int mst[MAX];
int i, j, min, minid, sum = 0;
for (i = 2; i <= n; i++)
{
lowcost[i] = graph[1][i];//lowcost存放顶点1可达点的路径长度
mst[i] = 1;//初始化以1位起始点
}
mst[1] = 0;
2.查找最小权值及路径更新
定义一个最小权值min和一个最小顶点ID minid,通过循环查找出min和minid,另外由于规定了某一顶点如果被连入,则lowcost[i]=0,所以不需要担心重复点问题。所以找出的终点minid在MST[i]中可以找到对应起点,min为权值,直接输出即可。
我们连入了一个新的顶点,自然需要对这一点可达的路径及权值进行更新,所以循环中还应该包括路径更新的代码。
for (i = 2; i <= n; i++)
{
min = MAXCOST;
minid = 0;
for (j = 2; j <= n; j++)
{
if (lowcost[j] < min && lowcost[j] != 0)
{
min = lowcost[j];//找出权值最短的路径长度
minid = j; //找出最小的ID
}
}
printf("V%d-V%d=%d\n",mst[minid],minid,min);
sum += min;//求和
lowcost[minid] = 0;//该处最短路径置为0
for (j = 2; j <= n; j++)
{
if (graph[minid][j] < lowcost[j])//对这一点直达的顶点进行路径更新
{
lowcost[j] = graph[minid][j];
mst[j] = minid;
}
}
}
printf("最小权值之和=%d\n",sum);
}
具体代码如下:
#include<stdio.h>
#define MAX 100
#define MAXCOST 0x7fffffff
int graph[MAX][MAX];
void prim(int graph[][MAX], int n)
{
int lowcost[MAX];
int mst[MAX];
int i, j, min, minid, sum = 0;
for (i = 2; i <= n; i++)
{
lowcost[i] = graph[1][i];//lowcost存放顶点1可达点的路径长度
mst[i] = 1;//初始化以1位起始点
}
mst[1] = 0;
for (i = 2; i <= n; i++)
{
min = MAXCOST;
minid = 0;
for (j = 2; j <= n; j++)
{
if (lowcost[j] < min && lowcost[j] != 0)
{
min = lowcost[j];//找出权值最短的路径长度
minid = j; //找出最小的ID
}
}
printf("V%d-V%d=%d\n",mst[minid],minid,min);
sum += min;//求和
lowcost[minid] = 0;//该处最短路径置为0
for (j = 2; j <= n; j++)
{
if (graph[minid][j] < lowcost[j])//对这一点直达的顶点进行路径更新
{
lowcost[j] = graph[minid][j];
mst[j] = minid;
}
}
}
printf("最小权值之和=%d\n",sum);
}
int main()
{
int i, j, k, m, n;
int x, y, cost;
//freopen("1.txt","r",stdin);//文件输入
scanf("%d%d",&m,&n);//m=顶点的个数,n=边的个数
for (i = 1; i <= m; i++)//初始化图
{
for (j = 1; j <= m; j++)
{
graph[i][j] = MAXCOST;
}
}
for (k = 1; k <= n; k++)
{
scanf("%d%d%d",&i,&j,&cost);
graph[i][j] = cost;
graph[j][i] = cost;
}
prim(graph, m);
return 0;
}
编译运行结果:

kruskal(克鲁斯卡尔)算法
时间复杂度:O(NlogN)(N为边数)
kruskal算法又称“加边法”,用于边数较少的稀疏图
方法:每次找图中权值最小的边,将边连接的两个顶点加入最小生成树集合中
注意:相同权值任选其中一个即可,但是不允许出现闭合回路的情况。
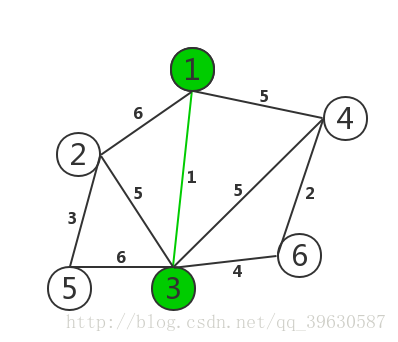
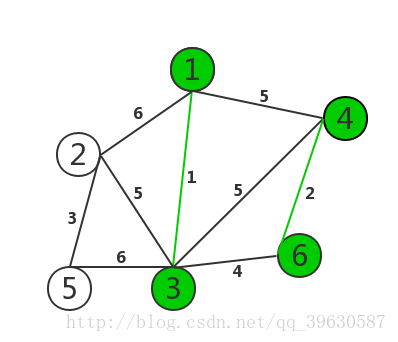




代码部分通过以下步骤可以得到最小生成树:
1.初始化:
构建边的结构体,包括起始顶点、终止顶点,边的权值
借用一个辅助数组vset[i]用来判断某边是否加入了最小生成树集合
#define MAXE 100
#define MAXV 100
typedef struct{
int vex1; //边的起始顶点
int vex2; //边的终止顶点
int weight; //边的权值
}Edge;
void kruskal(Edge E[],int n,int e)
{
int i,j,m1,m2,sn1,sn2,k,sum=0;
int vset[n+1];
for(i=1;i<=n;i++) //初始化辅助数组
vset[i]=i;
k=1;//表示当前构造最小生成树的第k条边,初值为1
j=0;//E中边的下标,初值为0
2.取边和辅助集合更新
按照排好的顺序依次取边,若不属于同一集合则将其加入最小生成树集合,每当加入新的边,所连接的两个点即纳入最小生成树集合,为避免重复添加,需要进行辅助集合更新
注:由于kruskal算法需要按照权值大小顺序取边,所以应该事先对图按权值升序,这里我采用了快速排序算法,具体算法可以参照快速排序(C语言)
while(k<e)//生成的边数小于e时继续循环
{
m1=E[j].vex1;
m2=E[j].vex2;//取一条边的两个邻接点
sn1=vset[m1];
sn2=vset[m2];
//分别得到两个顶点所属的集合编号
if(sn1!=sn2)//两顶点分属于不同的集合,该边是最小生成树的一条边
{//防止出现闭合回路
printf("V%d-V%d=%d\n",m1,m2,E[j].weight);
sum+=E[j].weight;
k++; //生成边数增加
if(k>=n)
break;
for(i=1;i<=n;i++) //两个集合统一编号
if (vset[i]==sn2) //集合编号为sn2的改为sn1
vset[i]=sn1;
}
j++; //扫描下一条边
}
printf("最小权值之和=%d\n",sum);
}
具体算法实现:
#include <stdio.h>
#define MAXE 100
#define MAXV 100
typedef struct{
int vex1; //边的起始顶点
int vex2; //边的终止顶点
int weight; //边的权值
}Edge;
void kruskal(Edge E[],int n,int e)
{
int i,j,m1,m2,sn1,sn2,k,sum=0;
int vset[n+1];
for(i=1;i<=n;i++) //初始化辅助数组
vset[i]=i;
k=1;//表示当前构造最小生成树的第k条边,初值为1
j=0;//E中边的下标,初值为0
while(k<e)//生成的边数小于e时继续循环
{
m1=E[j].vex1;
m2=E[j].vex2;//取一条边的两个邻接点
sn1=vset[m1];
sn2=vset[m2];
//分别得到两个顶点所属的集合编号
if(sn1!=sn2)//两顶点分属于不同的集合,该边是最小生成树的一条边
{//防止出现闭合回路
printf("V%d-V%d=%d\n",m1,m2,E[j].weight);
sum+=E[j].weight;
k++; //生成边数增加
if(k>=n)
break;
for(i=1;i<=n;i++) //两个集合统一编号
if (vset[i]==sn2) //集合编号为sn2的改为sn1
vset[i]=sn1;
}
j++; //扫描下一条边
}
printf("最小权值之和=%d\n",sum);
}
int fun(Edge arr[],int low,int high)
{
int key;
Edge lowx;
lowx=arr[low];
key=arr[low].weight;
while(low<high)
{
while(low<high && arr[high].weight>=key)
high--;
if(low<high)
arr[low++]=arr[high];
while(low<high && arr[low].weight<=key)
low++;
if(low<high)
arr[high--]=arr[low];
}
arr[low]=lowx;
return low;
}
void quick_sort(Edge arr[],int start,int end)
{
int pos;
if(start<end)
{
pos=fun(arr,start,end);
quick_sort(arr,start,pos-1);
quick_sort(arr,pos+1,end);
}
}
int main()
{
Edge E[MAXE];
int nume,numn;
//freopen("1.txt","r",stdin);//文件输入
printf("输入顶数和边数:\n");
scanf("%d%d",&numn,&nume);
for(int i=0;i<nume;i++)
scanf("%d%d%d",&E[i].vex1,&E[i].vex2,&E[i].weight);
quick_sort(E,0,nume-1);
kruskal(E,numn,nume);
}
编译运行结果:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
最小生成树算法C语言代码实例
在贪婪算法这一章提到了最小生成树的一些算法,首先是Kruskal算法,实现如下: MST.h 复制代码 代码如下: #ifndef H_MST#define H_MST #define NODE node *#define G graph *#define MST edge ** /* the undirect graph start */typedef struct _node { char data; int flag; struct _node *parent;} node; typede
-

使用C语言实现最小生成树求解的简单方法
最小生成树Prim算法朴素版 有几点需要说明一下. 1.2个for循环都是从2开始的,因为一般我们默认开始就把第一个节点加入生成树,因此之后不需要再次寻找它. 2.lowcost[i]记录的是以节点i为终点的最小边权值.初始化时因为默认把第一个节点加入生成树,因此lowcost[i] = graph[1][i],即最小边权值就是各节点到1号节点的边权值. 3.mst[i]记录的是lowcost[i]对应的起点,这样有起点,有终点,即可唯一确定一条边了.初始化时mst[i] = 1,即每条边都是从
-
Prim(普里姆)算法求最小生成树的思想及C语言实例讲解
Prim 算法思想: 从任意一顶点 v0 开始选择其最近顶点 v1 构成树 T1,再连接与 T1 最近顶点 v2 构成树 T2, 如此重复直到所有顶点均在所构成树中为止. 最小生成树(MST):权值最小的生成树. 生成树和最小生成树的应用:要连通n个城市需要n-1条边线路.可以把边上的权值解释为线路的造价.则最小生成树表示使其造价最小的生成树. 构造网的最小生成树必须解决下面两个问题: 1.尽可能选取权值小的边,但不能构成回路: 2.选取n-1条恰当的边以连通n个顶点: MST性质:假设G=(V
-
C语言实现最小生成树构造算法
最小生成树 最小生成树(minimum spanning tree)是由n个顶点,n-1条边,将一个连通图连接起来,且使权值最小的结构. 最小生成树可以用Prim(普里姆)算法或kruskal(克鲁斯卡尔)算法求出. 我们将以下面的带权连通图为例讲解这两种算法的实现: 注:由于测试输入数据较多,程序可以采用文件输入 Prim(普里姆)算法 时间复杂度:O(N^2)(N为顶点数) prim算法又称"加点法",用于边数较多的带权无向连通图 方法:每次找与之连线权值最小的顶点,将该点加入最小
-
Python 语言实现六大查找算法
目录 一.顺序查找算法 二.折半查找算法 三.插补查找算法 四.哈希查找算法 五.分块查找算法 六.斐波那契查找算法 七.六种查找算法的时间复杂度 一.顺序查找算法 顺序查找又称为线性查找,是最简单的查找算法.这种算法就是按照数据的顺序一项一项逐个查找,所以不管数据顺序如何,都得从头到尾地遍历一次.顺序查找的优点就是数据在查找前,不需要对其进行任何处理(包括排序).缺点是查找速度慢,如果数据列的第一个数据就是想要查找的数据,则该算法查找速度为最快,只需查找一次即可:如果查找的数据是数据列的最后一
-
java语言实现权重随机算法完整实例
前言 现在app就是雨后春笋,嗖嗖的往外冒啊,有经验的.没经验的.有资历的.没资历的都想着创业,创业的90%以上都要做一个app出来,好像成了创业的标配. 做了app就得推广啊,怎么推,发券送钱是最多用的被不可少的了,现在好多产品或者运营都要求能够随机出优惠券的金额,但是呢又不能过于随机,送出去的券都是钱吗,投资人的钱,是吧. 所以,在随机生成的金额中就要求,小额度的几率要大,大额度的几率要小,比如说3元的70%,5块的25%,10块的5%,这个样子的概率去生成优惠券,这个怎么办呢? 对于上述的
-
基于Go和PHP语言实现爬楼梯算法的思路详解
爬楼梯(Climbing-Stairs) 题干: 假设你正在爬楼梯.需要 n 阶你才能到达楼顶.每次你可以爬 1 或 2 个台阶.你有多少种不同的方法可以爬到楼顶呢?注意:给定 n 是一个正整数.示例 1: 输入: 2 输出: 2 解释: 有两种方法可以爬到楼顶. 1. 1 阶 + 1 阶 2. 2 阶示例 2: 输入: 3 输出: 3 解释: 有三种方法可以爬到楼顶. 1. 1 阶 + 1 阶 + 1 阶 2. 1 阶 + 2 阶 3. 2 阶 + 1 阶来源:力扣 这题
-
C语言实现页面置换算法
本文实例为大家分享了C语言实现页面置换算法的具体代码,供大家参考,具体内容如下 操作系统实验 页面置换算法(FIFO.LRU.OPT) 概念: 1.最佳置换算法(OPT)(理想置换算法):从主存中移出永远不再需要的页面:如无这样的页面存在,则选择最长时间不需要访问的页面.于所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率. 2.先进先出置换算法(FIFO):是最简单的页面置换算法.这种算法的基本思想是:当需要淘汰一个页面时,总是选择驻留主存时
-
R语言关于随机森林算法的知识点详解
在随机森林方法中,创建大量的决策树. 每个观察被馈入每个决策树. 每个观察的最常见的结果被用作最终输出. 新的观察结果被馈入所有的树并且对每个分类模型取多数投票. 对构建树时未使用的情况进行错误估计. 这称为OOB(袋外)误差估计,其被提及为百分比. R语言包"randomForest"用于创建随机森林. 安装R包 在R语言控制台中使用以下命令安装软件包. 您还必须安装相关软件包(如果有). install.packages("randomForest") 包&qu
-
Go语言实现Snowflake雪花算法
每次放长假的在家里的时候,总想找点简单的例子来看看实现原理,这次我们来看看 Go 语言雪花算法. 介绍 有时候在业务中,需要使用一些唯一的ID,来记录我们某个数据的标识.最常用的无非以下几种:UUID.数据库自增主键.Redis的Incr命令等方法来获取一个唯一的值.下面我们分别说一下它们的优劣,以便引出我们的分布式雪花算法. 雪花算法 雪花算法的原始版本是scala版,用于生成分布式ID(纯数字,时间顺序),订单编号等. 自增ID:对于数据敏感场景不宜使用,且不适合于分布式场景. GUID:采
-
C语言实现各种排序算法实例代码(选择,冒泡,插入,归并,希尔,快排,堆排序,计数)
目录 前言 选择排序 冒泡排序 插入排序 归并排序 希尔排序 快速排序 堆排序 计数排序 总结 前言 平时用惯了高级语言高级工具高级算法,难免对一些基础算法感到生疏.但最基础的排序算法中实则蕴含着相当丰富的优化思维,熟练运用可起到举一反三之功效. 选择排序 选择排序几乎是最无脑的一种排序算法,通过遍历一次数组,选出其中最大(小)的值放在新数组的第一位:再从数组中剩下的数里选出最大(小)的,放到第二位,依次类推. 算法步骤 设数组有n个元素,{ a 0 , a 1 , - , a n } 从数组第
-
C语言实现页面置换算法(FIFO、LRU)
目录 1.实现效果 2.实现源代码 1.实现效果 2.实现源代码 #include<iostream> #include<process.h> #include<stdlib.h> #include<ctime> #include<conio.h> #include<stdio.h> #include<string.h> using namespace std; #define Myprintf printf(&quo