Orace查询数据出现乱码的问题解决思路
问题描述:
经常有些朋友会遇到,我明明是输入的正确中文,为什么我在另外一台电脑上查询却出现乱码啦?其实这个是数据库在进行字符集转换的时候出现了问题,
下面通过测试来描述具体的情况:
1.环境
Oracle 数据库字符集:
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.1.0
Connected as scott
SQL> SELECT * FROM DATABASE_PROPERTIES WHERE PROPERTY_NAME = 'NLS_CHARACTERSET';
PROPERTY_NAME PROPERTY_VALUE DESCRIPTION
------------------------------ -------------------------------------------------------------------------------- ------------------------------------------------------------------------------
NLS_CHARACTERSET ZHS16GBK Character set
Oracle 数据库所在的客服端字符集:
在注册表的:NLS_LANG=SIMPLIFIED CHINESE_CHINA.ZHS16GBK 如下图: 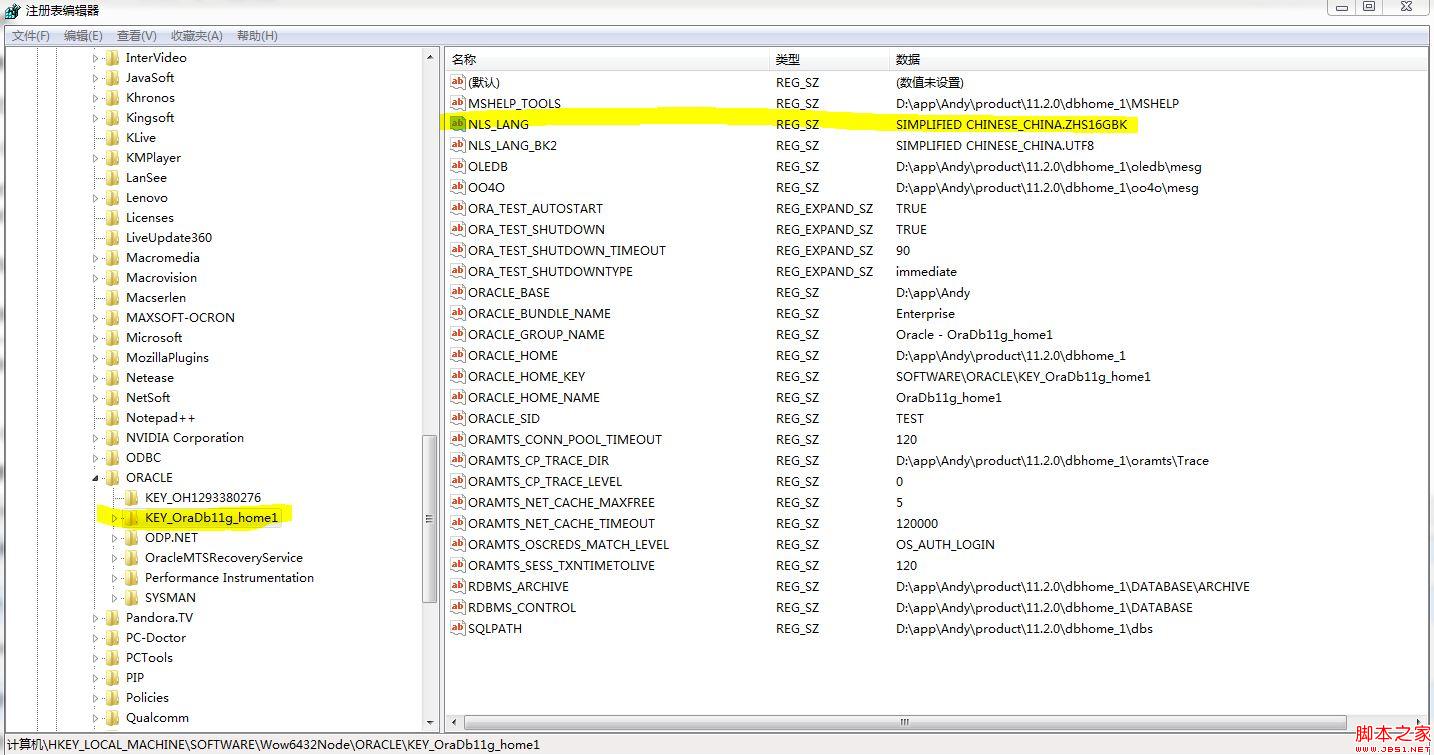
Oracle 所在的操作系统的字符集:
Microsoft Windows [版本 6.1.7601]
版权所有 (c) 2009 Microsoft Corporation。保留所有权利。
C:\Users\Andy>chcp
活动代码页: 936
表示是:中国 - 简体中文(GB2312)
2.测试
字符集如下:
Oracle 数据库字符集:ZHS16GBK
Oracle 数据库客户端字符集:ZHS16GBK
操作系统字符集:中国 - 简体中文(GB2312)
输入测试数据:
SQL> INSERT INTO TAB_INDX
2 values(1,'汉字输入字符集测试','Chinese Input Test',sysdate);
1 row inserted
字符集不修改,进行测试数据现实:
SQL> select * from tab_indx where tid = 1;
TID TNAME TDESC SYSDT
---------- -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- -----------
1 汉字输入字符集测试 Chinese Input Test 2012/12/30
显示正常,
现在我把客服端的字符集修改为:UTF8
及注册表的:NLS_LANG=SIMPLIFIED CHINESE_CHINA.UTF8
现在字符集如下:
Oracle 数据库字符集:ZHS16GBK
Oracle 数据库客户端字符集:UTF8
操作系统字符集:中国 - 简体中文(GB2312)
现在再查询刚才输入的数据:
SQL> select tname,tdesc from tab_indx;
TNAME TDESC
-------------------------------------------------------------------------------- --------------------------------------------------------------------------------
发现查询出来的数据已经不能正常现实,因为这些汉字是以ZHS16GBK编码格式存储的,然而你查询出来后根据Oracle客服端的编码(UTF8)转换,及转成了UTF8的编码格式,但是操作系统是简体中文(GB2312),所以操作系统就把UTF8编码格式的数据,当成简体中文(GB2312)的编码格式数据显示,结果就出现了乱码,
现在我再插入一笔数据:
SQL> INSERT INTO TAB_INDX
2 values(1,'UTF8下汉字输入字符集测试','Chinese Input Test',sysdate);
1 row inserted
再查询:
SQL> select tname,tdesc from tab_indx;
TNAME TDESC
-------------------------------------------------------------------------------- --------------------------------------------------------------------------------
发现新插入的数据也出现了乱码,但是乱码跟刚才的值不一样??为什么呢?
因为输入的汉字,是简体中文(GB2312)的编码格式,当Oracle数据库按照客户端的编码格式传给数据库,Oracle数据库发现,Oracle数据库客户端是UTF8的编码格式,跟数据库的编码格式(ZHS16GBK)不一样,就进行字符集转换,UTF8-->ZHS16GBK,所以把简体中文(GB2312)的编码格式的数据当成UTF8,转为ZHS16GBK的编码格式数据,就已经出错啦,查询出来自然转换回去就不行啦
(本来需要测试Oracle数据库的字符集修改后的情况,这种情况暂时不测试)这里我们在把Oracle客户的字符集修改回去;
在注册表的:NLS_LANG=SIMPLIFIED CHINESE_CHINA.ZHS16GBK
现在字符集如下:
Oracle 数据库字符集:ZHS16GBK
Oracle 数据库客户端字符集:ZHS16GBK
操作系统字符集:中国 - 简体中文(GB2312)
再查询:
SQL> select tname,tdesc from tab_indx;
TNAME TDESC
-------------------------------------------------------------------------------- --------------------------------------------------------------------------------
汉字输入字符集测试 Chinese Input Test
UTF8????????????? Chinese Input Test
发现最开始输入的汉字正常啦,但是第二次输入的汉字,又变了,跟上次的乱码不一样????
虽然这里没有进行编码格式转换,但是上次在存数据的时候,已经是存的错误的编码格式,所以显示出来肯定不正确
其实还有好几种情况测试,由于本地环境的限制,所以测试的其它情况,大家可以去试试,如:数据库的字符集是UTF8,然后客服端的字符集变化,对汉字的输入输出有什么影响
根据上面的测试情况和我自己的分析,现在总结如下:
1.数据库的查询出来的数据,是Oracle数据库字符集,Oracle客户端字符集,操作系统字符集共同作用的结果。
2.Oracle存数据和查询数据都是通过Oracle数据库的字符集和Oracle客服端的字符集进行转换的,显示数据又是根据操作系统的字符集来确定的。
3.为了避免出现乱码必须要把Oracle客户端的字符集和操作系统的字符集设置成一样的。
相关推荐
-

Orace查询数据出现乱码的问题解决思路
问题描述: 经常有些朋友会遇到,我明明是输入的正确中文,为什么我在另外一台电脑上查询却出现乱码啦?其实这个是数据库在进行字符集转换的时候出现了问题, 下面通过测试来描述具体的情况: 1.环境 Oracle 数据库字符集: Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 Connected as scott SQL> SELECT * FROM DATABASE_PROPERTIES WHERE PROP
-
Oracle客户端与plsql查询数据乱码修改成中文的快速解决方法
1.查询ORACLE服务器的语言.地域和字符集 select * from nls_database_paameters; 查询结果如下图, NLS_LANGUAGE 表示"语言",NLS_TERRITORY 表示"地域",NLS_CHARACTSET 表示"字符集",将他们三个按照"语言_地域.字符集"的格式拼接起来,就有了"AMERICAN_AMERICA.ZHS16GBK". 下面正式的来操作: 2.
-
mybatis实现mapper配置并查询数据的思路详解
mapper开发 开发规范: 2.mapper.java接口中的方法名和mapper.xml中statement的id一致 3.mapper.java接口中的方法输入参数类型和mapper.xml中statement的parameterType指定的类型一致. 4.mapper.java接口中的方法返回值类型和mapper.xml中statement的resultType指定的类型一致. 首先创建一个entity 创建mapper文件: 创建实现: 创建mapper映射文件: 最后在sqlCon
-
微信小程序 wx.login解密出现乱码的问题解决办法
微信小程序 wx.login解密出现乱码的问题解决办法 最近在给公司开发微信小程序,需要用到微信登录,根据文档要求需要把获取的用户信息按照AES进行解密. 我使用的是官方提供的PHP demo,拷贝到程序中,测试发现,解密之后的数据前面有一串乱码. 类似于这样子的,前面一段是乱码. 经过仔细的检查,发现官方的提供的demo中的帐号和机密之后的信息是可以解密的,这就说明解密代码是没有问题的. 后来查询微信开发者社区,找到好多解密失败.其中一个回答说是因为多次调用wx.login之后导致的问题. 终
-
Java编程删除链表中重复的节点问题解决思路及源码分享
一. 题目 在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针. 二. 例子 输入链表:1->2->3->3->4->4->5 处理后为:1->2->5 三. 思路 个人感觉这题关键是注意指针的指向,可以定义一个first对象(值为-1,主要用于返回操作后的链表),first.next指向head,定义一个last同样指向first(主要用于操作记录要删除节点的前一个节点),定义一个p指向head,指向当前节点.
-
php查询mssql出现乱码的解决方法
本文实例讲述了php查询mssql出现乱码的解决方法.分享给大家供大家参考.具体分析如下: 在php连接mssql时查询出来的全部是乱码,这种问题我根据经验知道是编码问题,下面来给各位总结一下解决方法. 方法一,修改php.ini文件,当然根据你页面情况来设置也可以是utf-8编码了,代码如下: 复制代码 代码如下: ;mssql.charset = "ISO-8859-1" mssql.charset = "GBK" 方法二,直接程序中转换,代码如下: 复制代码
-
详解MongoDB数据还原及同步解决思路
mongodb数据如何还原,同步到其他系统?只要我们了解了数据库日志原理,一切都是那么简单 oplog原理 Oplog.rs 表类型为 Capped Collections - 表类型: Capped collections它的插入速度非常快,基本和磁盘的写入速度差不多,并且支持按照插入顺序高效的查询操作.Capped collections的大小是固定的,它的工作方式很像环形缓冲器(circular buffers), 当剩余空间不足时,会覆盖最先插入的数据. 优势: Capped colle
-
Python实现大数据收集至excel的思路详解
一.在工程目录中新建一个excel文件 二.使用python脚本程序将目标excel文件中的列头写入,本文省略该部分的code展示,可自行网上查询 三.以下code内容为:实现从接口获取到的数据值写入excel的整体步骤 1.整体思路: (1).根据每日调取接口的日期来作为excel文件中:列名为"收集日期"的值 (2).程序默认是每天会定时调取接口并获取接口的返回值并写入excel中(我使用的定时任务是:linux下的contab) (3).针对接口异常未正确返回数据时,使用特殊符号
-
JAVA实现按时间段查询数据操作
html / jsp <span style="vertical-align: -webkit-baseline-middle;font-size:16px;font-weight:bold;">开始时间:</span> <input name="startTime" id="startTime" type="text" class="Wdate" onfocus="
-
JAVA读取HDFS的文件数据出现乱码的解决方案
使用JAVA api读取HDFS文件乱码踩坑 想写一个读取HFDS上的部分文件数据做预览的接口,根据网上的博客实现后,发现有时读取信息会出现乱码,例如读取一个csv时,字符串之间被逗号分割 英文字符串aaa,能正常显示 中文字符串"你好",能正常显示 中英混合字符串如"aaa你好",出现乱码 查阅了众多博客,解决方案大概都是:使用xxx字符集解码.抱着不信的想法,我依次尝试,果然没用. 解决思路 因为HDFS支持6种字符集编码,每个本地文件编码方式又是极可能不一样的