用python做一个搜索引擎(Pylucene)的实例代码
1.什么是搜索引擎?
搜索引擎是“对网络信息资源进行搜集整理并提供信息查询服务的系统,包括信息搜集、信息整理和用户查询三部分”。如图1是搜索引擎的一般结构,信息搜集模块从网络采集信息到网络信息库之中(一般使用爬虫);然后信息整理模块对采集的信息进行分词、去停用词、赋权重等操作后建立索引表(一般是倒排索引)构成索引库;最后用户查询模块就可以识别用户的检索需求并提供检索服务啦。

图1 搜索引擎的一般结构
2. 使用python实现一个简单搜索引擎
2.1 问题分析
从图1看,一个完整的搜索引擎架构从互联网搜集信息开始,可以使用python编写一个爬虫,这是python的强项。
接着,信息处理模块。分词?停用词?倒排表?what?什么乱七八糟的?不用管它,我们有前辈们造好的轮子---Pylucene(lucene的python封装版本,Lucene能够帮助开发者为软件、系统增添检索功能。Lucene是一套用于全文检索和搜寻的开源程序库)。使用Pylucene可以简单的帮助我们完成对采集到的信息进行处理,包括索引的建立和搜索。
最后,为了能在网页上使用我们的搜索引擎,我们使用flask这个轻量级 Web 应用框架做一个小网页获取搜索语句并反馈搜索结果。
2.2 爬虫设计
主要搜集以下内容:目标网页的标题、目标网页的主要文字内容、目标网页指向其他页面的URL地址。网络爬虫的工作流程如图2所。爬虫的主要数据结构是队列。首先,起始的种子节点进入队列,然后从队列中取出一个节点访问,抓取该节点页面上的目标信息,再将该节点页面指向其他页面的URL链接放进队列,再从队列中取出新的节点进行访问,直至队列为空。通过队列“先进先出”的特点实现广度优先的遍历算法,逐个访问站点的每一页面。
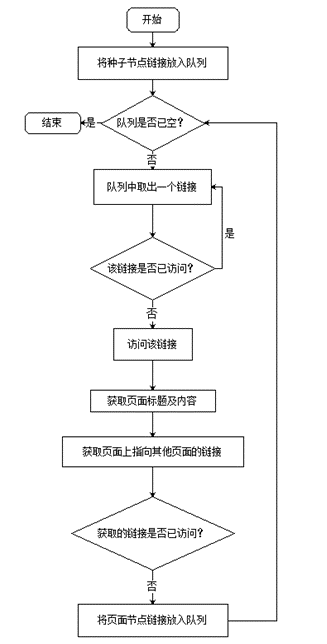
图2
2.3 pylucene的使用
Pylucene中关于建立索引的类主要有Directory、Analyzer、IndexWriter、Document、Filed。
Directory是Pylucene中关于文件操作的类。它有SimpleFSDirectory和RAMDirectory、CompoundFileDirectory、FileSwitchDirectory等11个子类,列举的四个是与索引目录的保存相关的子类,SimpleFSDirectory是将构建的索引保存至文件系统之中;RAMDirectory是将索引保存至RAM内存之中;CompoundFileDirectory是一种复合的索引保存方式;而FileSwitchDirectory允许临时切换索引的保存方式以发挥各种索引保存方式的优点。
Analyzer,分析器。它是对爬虫获得的将要进行构建索引的文本进行处理的类。包括了文本进行分词操作、去掉停用词、转换大小写等操作。Pylucene自带了若干分析器,构建索引时也可使用第三方分析器或者自写分析器。分析器的好坏关系到构建索引的质量与搜索服务的所能提供的精准度与速度。
IndexWriter,索引写入类。在Directory开辟的储存空间中IndexWriter可以进行索引的写入、修改、增添、删除等操作,但不可进行索引的读取也不能搜索索引。
Document,文档类。在Pylucene中建立索引的基本单位是“文档”(Document),一个Document可能是一个网页、一篇文章、一封邮件。Document是用以构建索引的单位同时也是进行搜索时的结果单位,对它进行合理的设计能够提供个性化的搜索服务。
Filed,域类。一个Document之中可以包含多个域(Field)。Filed是Document的组成部分,就如一篇文章的组成可能是文章标题、文章主体、作者、发表日期等多个Filed。
将一个页面作为一个Document,包含三个Field分别是页面的URL地址(url)、页面的标题(title)、页面的主要文字内容(content)。对于索引的储存方式选择使用SimpleFSDirectory类,将索引保存至文件之中。分析器选择Pylucene自带的CJKAnalyzer,该分析器对中文支持较好,适用于中文内容的文本处理。
使用Pylucene构建索引的具体操作步骤如下:
lucene.initVM()
INDEXIDR = self.__index_dir
indexdir = SimpleFSDirectory(File(INDEXIDR))①
analyzer = CJKAnalyzer(Version.LUCENE_30)②
index_writer = IndexWriter(indexdir, analyzer, True, IndexWriter.MaxFieldLength(512))③
document = Document()④
document.add(Field("content", str(page_info["content"]), Field.Store.NOT, Field.Index.ANALYZED))⑤
document.add(Field("url", visiting, Field.Store.YES, Field.Index.NOT_ANALYZED))⑥
document.add(Field("title", str(page_info["title"]), Field.Store.YES, Field.Index.ANALYZED))⑦
index_writer.addDocument(document)⑧
index_writer.optimize()⑨
index_writer.close()⑩
索引的构建有10个主要的步骤:
①实例化一个SimpleFSDirectory对象,将索引保存至本地文件之中,保存的路径为自定义的路径“INDEXIDR”。
②实例化一个CJKAnalyzer分析器,实例化时的参数Version.LUCENE_30为Pylucene的版本号。
③实例化一个IndexWriter对象,所携带的四个参数分是前面的实例化的SimpleFSDirectory对象和CJKAnalyzer分析器,布尔型的变量true表示创建一个新的索引,IndexWriter.MaxFieldLength指定了一个索引最大的域(Filed)数量。
④实例化一个Document对象,取名为document。
⑤为document添加名称为“content”的域。该域的内容为爬虫获取的某一网页页面的主要文字内容。该操作的参数是实例化并马上使用的Field对象;Field对象的四个参数分别是:
(1)“content”,域的名称。
(2)page_info["content"],爬虫搜集到的网页页面的主要文字内容。
(3)Field.Store是用于表示该域的值是否可以恢复原始字符的变量,Field.Store.YES表示存储在该域中的内容可以恢复至原始文本内容,Field. Store.NOT表示不可恢复。
(4)Field.Index变量表示该域的内容是否应用分析器处理,Field. Index.ANALYZED表示对该域字符处理使用分析器,Field. Index. NOT_ANALYZED则表示不对该域使用分析器处理字符。
⑥添加名称为“url”的域用以保存该页面地址。
⑦添加名称为“title”的域用以保存该页面的标题。
⑧实例化IndexWriter对像将文档document写入索引文件。
⑨优化索引库文件,合并索引库中的小文件为大文件。
⑩单个周期内构建索引操作完成后关闭IndexWriter对像。
Pylucene关于建立索引的搜索的类主要有IndexSearcher、Query、QueryParser[16]。
IndexSearcher,索引搜索类。用于在IndexWriter构建的索引库中进行搜索操作。
Query,描述查询请求的类。它将查询请求递交给IndexSearcher完成搜索操作。Query拥有许多子类以完成不同的查询请求。例如TermQuery是按词条搜索,它是最基本最简单的查询类型,用来在指定域中匹配特定项的文档;RangeQuery,指定范围内搜索,用于在指定域中匹配特定范围内的文档;FuzzyQuery,一种模糊查询,能够简单地识别近义词匹配与查询关键字语义相近的项。
QueryParser,Query解析器。需要实现不同的查询需求时必须使用Query提供的不同子类,导致Query使用起来容易造成混乱。因而Pylucene还提供了Query语法解析器QueryParser。QueryParser能够解析提交的Query语句,根据Query语法挑选合适Query子类完成相应的查询,开发者不必关心底层使用的是什么Query实现类。例如Query语句“关键字1 and 关键字2” QueryParser解析为查询同时匹配关键字1和关键字2的文档;Query语句“id[123 to 456]” QueryParser解析成为查询名称为“id”的域中的值在指定范围“123”到“456”之间的文档;Query语句“关键字 site:www.web.com”QueryParser解析成为查询同时满足名称为“site”的域中值为“www.web.com” 和匹配“关键字”两个查询条件的文档。
索引的搜索是Pylucene所专注的领域之一,为实现索引的搜索编写了一个名为query的类,query实现索引的搜索有以下主要步骤:
lucene.initVM()
if query_str.find(":") ==-1 and query_str.find(":") ==-1:
query_str="title:"+query_str+" OR content:"+query_str①
indir= SimpleFSDirectory(File(self.__indexDir))②
lucene_analyzer= CJKAnalyzer(Version.LUCENE_CURRENT)③
lucene_searcher= IndexSearcher(indir)④
my_query = QueryParser(Version.LUCENE_CURRENT,"title",lucene_analyzer).parse(query_str)⑤
total_hits = lucene_searcher.search(my_query, MAX)⑥
for hit in total_hits.scoreDocs:⑦
print"Hit Score: ", hit.score
doc = lucene_searcher.doc(hit.doc)
result_urls.append(doc.get("url").encode("utf-8"))
result_titles.append(doc.get("title").encode("utf-8"))
print doc.get("title").encode("utf-8")
result = {"Hits": total_hits.totalHits, "url":tuple(result_urls), "title":tuple(result_titles)}
return result
索引的搜索有7个主要的步骤:
①首先对搜索语句进行判断,若语句不是针对标题或文章内容进行单一域的查询,即不包含关键词“title:”或“content:”时默认搜索title和content两个域。
②实例化一个SimpleFSDirectory对象,指定它的工作路径为先前创建索引的路径。
③实例化一个CJKAnalyzer分析器,搜索时使用的分析器应与索引构建时使用的分析器在类型版本上均一致。
④实例化一个IndexSearcher对象lucene_searcher,它的参数为第○2步的SimpleFSDirectory对象。
⑤实例化一个QueryParser对象my_query,它描述查询请求,解析Query查询语句。参数Version.LUCENE_CURRENT为pylucene的版本号,“title”指默认的搜索域,lucene_analyzer指定了使用的分析器,query_str是Query查询语句。在实例化QueryParser前会对用户搜索请求作简单处理,若用户指定了搜索某个域就搜索该域,若用户未指定则同时搜索“title”和“content”两个域。
⑥lucene_searcher进行搜索操作,返回结果集total_hits。total_hits中包含结果总数totalHits,搜索结果的文档集scoreDocs,scoreDocs中包括搜索出的文档以及每篇文档与搜索语句相关度的得分。
⑦lucene_searcher搜索出的结果集不能直接被Python处理,因而在搜索操作返回结果之前应将结果由Pylucene转为普通的Python数据结构。使用For循环依次处理每个结果,将结果文档按相关度得分高低依次将它们的地址域“url”的值放入Python列表result_urls,将标题域“title”的值放入列表result_titles。最后将包含地址、标题的列表和结果总数组合成一个Python“字典”,将最后处理的结果作为整个搜索操作的返回值。
用户在浏览器搜索框输入搜索词并点击搜索,浏览器发起一个GET请求,Flask的路由route设置了由result函数响应该请求。result函数先实例化一个搜索类query的对象infoso,将搜索词传递给该对象,infoso完成搜索将结果返回给函数result。函数result将搜索出来的页面和结果总数等传递给模板result.html,模板result.html用于呈现结果
如下是Python使用flask模块处理搜索请求的代码:
app = Flask(__name__)#创建Flask实例
@app.route('/')#设置搜索默认主页
def index():
html="<h1>title这是标题</h1>"
return render_template('index.html')
@app.route("/result",methods=['GET', 'POST'])#注册路由,并指定HTTP方法为GET、POST
def result(): #resul函数
if request.method=="GET":#响应GET请求
key_word=request.args.get('word')#获取搜索语句
if len(key_word)!=0:
infoso = query("./glxy") #创建查询类query的实例
re = infoso.search(key_word)#进行搜索,返回结果集
so_result=[]
n=0
for item in re["url"]:
temp_result={"url":item,"title":re["title"][n]}#将结果集传递给模板
so_result.append(temp_result)
n=n+1
return render_template('result.html', key_word=key_word, result_sum=re["Hits"],result=so_result)
else:
key_word=""
return render_template('result.html')
if __name__ == '__main__':
app.debug = True
app.run()#运行web服务
以上这篇用python做一个搜索引擎(Pylucene)的实例代码就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法
在这篇文章中,我们将分析一个网络爬虫. 网络爬虫是一个扫描网络内容并记录其有用信息的工具.它能打开一大堆网页,分析每个页面的内容以便寻找所有感兴趣的数据,并将这些数据存储在一个数据库中,然后对其他网页进行同样的操作. 如果爬虫正在分析的网页中有一些链接,那么爬虫将会根据这些链接分析更多的页面. 搜索引擎就是基于这样的原理实现的. 这篇文章中,我特别选了一个稳定的."年轻"的开源项目pyspider,它是由 binux 编码实现的. 注:据认为pyspider持续监控网络,它假定网页在一
-
Python+django实现简单的文件上传
今天分享一下Django实现的简单的文件上传的小例子. 步骤 •创建Django项目,创建Django应用 •设计模型 •处理urls.py 以及views.py •设计模板,设计表单 •运行项目,查看数据库 下面我们就一起来分别完成每一个小部分吧. 创建项目和应用 django-admin startproject Django_upload django-admin startapp app 添加一个名为upload的目录,待会要用哦. 然后记得在settings.py 中的INS
-
Python中使用haystack实现django全文检索搜索引擎功能
前言 django是python语言的一个web框架,功能强大.配合一些插件可为web网站很方便地添加搜索功能. 搜索引擎使用whoosh,是一个纯python实现的全文搜索引擎,小巧简单. 中文搜索需要进行中文分词,使用jieba. 直接在django项目中使用whoosh需要关注一些基础细节问题,而通过haystack这一搜索框架,可以方便地在django中直接添加搜索功能,无需关注索引建立.搜索解析等细节问题. haystack支持多种搜索引擎,不仅仅是whoosh,使用solr.elas
-
Python中使用django form表单验证的方法
一. django form表单验证引入 有时时候我们需要使用get,post,put等方式在前台HTML页面提交一些数据到后台处理例 ; <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Form</title> </head> <body> <div> <for
-

python+django快速实现文件上传
对于web开来说,用户登陆.注册.文件上传等是最基础的功能,针对不同的web框架,相关的文章非常多,但搜索之后发现大多都不具有完整性,对于想学习web开发的新手来说就没办法一步一步的操作练习:对于web应用来说,包括数据库的创建,前端页面的开发,以及中间逻辑层的处理三部分. 本系列以可操作性为主,介绍如何通过django web框架来实现一些简单的功能.每一章都具有完整性和独立性.使用新手在动手做的过程中体会web开发的过程,过程中细节请参考相关文档. 本操作的环境: =============
-
Python采用Django开发自己的博客系统
好久之前就想做一下自己的博客系统了,但是在网上查了查好像是需要会一些Node.js的相关知识,而且还要安装辣么多的库什么的,就不想碰了.但是我遇到了Django这么一款神器,没想到我的博客系统就这么建立起来了.虽然是最基础的类型.但是也算是成功了,这篇博客比较适合对Django有了一定了解的童鞋,如果是新手的话,建议先看一下django的基础知识点再来做实验,这样效率更高! 好了,话不多说,开始吧. 搭建框架 •创建项目及应用 搭建框架的意思,就是安装Django以及做好相关的配置.因为我是在
-
Linux下安装Python3和django并配置mysql作为django默认服务器方法
我的操作系统为centos6.5 1 首先选择django要使用什么数据库.django1.10默认数据库为sqlite3,本人想使用mysql数据库,但为了测试方便顺便要安装一下sqlite开发包. yum install mysql mysql-devel #为了测试方便,我们需要安装sqlite-devel包 yum install sqlite-devel 2 接下来需要安装Python了,因为Python3已经成为主流,所以接下来我们要安装Python3,到官网去下载Python3
-
用python做一个搜索引擎(Pylucene)的实例代码
1.什么是搜索引擎? 搜索引擎是"对网络信息资源进行搜集整理并提供信息查询服务的系统,包括信息搜集.信息整理和用户查询三部分".如图1是搜索引擎的一般结构,信息搜集模块从网络采集信息到网络信息库之中(一般使用爬虫):然后信息整理模块对采集的信息进行分词.去停用词.赋权重等操作后建立索引表(一般是倒排索引)构成索引库:最后用户查询模块就可以识别用户的检索需求并提供检索服务啦. 图1 搜索引擎的一般结构 2. 使用python实现一个简单搜索引擎 2.1 问题分析 从图1看,一个完整的搜索
-
使用Python写一个贪吃蛇游戏实例代码
我在程序中加入了分数显示,三种特殊食物,将贪吃蛇的游戏逻辑写到了SnakeGame的类中,而不是在Snake类中. 特殊食物: 1.绿色:普通,吃了增加体型 2.红色:吃了减少体型 3.金色:吃了回到最初体型 4.变色食物:吃了会根据食物颜色改变蛇的颜色 #coding=UTF-8 from Tkinter import * from random import randint import tkMessageBox class Grid(object): def __init__(self,
-
使用Python做垃圾分类的原理及实例代码
0 引言 纸巾再湿也是干垃圾?瓜子皮再干也是湿垃圾??最近大家都被垃圾分类折磨的不行,傻傻的你是否拎得清?
-
使用Python做垃圾分类的原理及实例代码附源码
0 引言 纸巾再湿也是干垃圾?瓜子皮再干也是湿垃圾??最近大家都被垃圾分类折磨的不行,傻傻的你是否拎得清?
-
python做图片搜索引擎并保存到本地详情
前言 我们先说一下思路:先对目标网站发送请求,获取html源码,然后对源码里面的所以图片链接进行筛选,然后再次对图片链接发送请求,然后保存. 思路大致是这样,话不多说,直接上代码: 用到的模块: import requests #请求库 第三方库,需要安装: pip install requests import re #筛选库,py自带,无需安装 查找接口: 打开F12打开开发者工具,点击网络.Fetch/XHR.载荷.依次点下去,可以看到查询参数有两个,分别是:word:风景图
-
不到20行代码用Python做一个智能聊天机器人
伴随着自然语言技术和机器学习技术的发展,越来越多的有意思的自然语言小项目呈现在大家的眼前,聊天机器人就是其中最典型的应用,今天小编就带领大家用不到20行代码,运用两种方式搭建属于自己的聊天机器人. 1.神器wxpy库 首先,小编先向大家介绍一下本次运用到的python库,本次项目主要运用到的库有wxpy和chatterbot. wxpy是在 itchat库 的基础上,通过大量接口优化,让模块变得简单易用,并进行了功能上的扩展.什么是接口优化呢,简单来说就是用户直接调用函数,并输入几个参数,就可以
-
五分钟学会怎么用python做一个简单的贪吃蛇
Pygame 是一组用来开发游戏软件的 Python 程序模块,基于 SDL 库的基础上开发.我们今天将利用它来制作一款大家基本都玩过的小游戏--贪吃蛇. 一.需要导入的包 import pygame import time import random pygame:获取图形组件构建游戏 time:主要用来设置帧率 random:主要用来设置食物的刷新位置 二.窗口界面设置 首先我们初始化游戏,建立一个窗口 pygame.init() 然后我们定义游戏中需要使用的颜色,在这个示例中,我们定义了六
-
用Python做一个哔站小姐姐词云跳舞视频
目录 一.前言 二.实现思路 1. 下载视频 2. 获取弹幕内容 3. 从视频中提取图片 4. 利用百度AI进行人像分割 5. 小姐姐跳舞词云生成 6. 合成跳舞视频 7. 视频插入音频 一.前言 B站上的漂亮的小姐姐真的好多好多,利用 you-get 大法下载了一个 B 站上跳舞的小姐姐视频,利用视频中的弹幕来制作一个漂亮小姐姐词云跳舞视频,一起来看看吧. 二.实现思路 1. 下载视频 安装 you-get 库 pip install you-get -i http://pypi.douban
-
教你使用python做一个“罚点球”小游戏
在学习了一点 Python 基础之后,我们可以做一个罚点球的小游戏,大概流程是这样: 每一轮,你先输入一个方向射门,然后电脑随机判断一个方向扑救.方向不同则算进球得分,方向相同算扑救成功,不得分. 之后攻守轮换,你选择一个方向扑救,电脑随机方向射门. 第5轮结束之后,如果得分不同,比赛结束. 5轮之内,如果一方即使踢进剩下所有球,也无法达到另一方当前得分,比赛结束. 5论之后平分,比赛继续进行,直到某一轮分出胜负. 实现方法有很多种,我这里提供的只是一种参考.你可以按照自己喜欢的方式去做,那样才
-
Python编程scoketServer实现多线程同步实例代码
本文研究的主要是Python编程scoketServer实现多线程同步的相关内容,具体介绍如下. 开发过程中,为了实现不同的客户端同一时刻只能有一个使用共同数据. 虽说用Python编写简单的网络程序很方便,但复杂一点的网络程序还是用现成的框架比较好.这样就可以专心事务逻辑,而不是套接字的各种细节.SocketServer模块简化了编写网络服务程序的任务.同时SocketServer模块也是Python标准库中很多服务器框架的基础. 网络服务类: SocketServer提供了4个基本的服务类: