Python教程pandas数据分析去重复值
目录
- 加载数据
- sample抽样函数
- 指定需要更新的值
- append直接添加
- append函数用法
- 根据某一列key值进行去重(key唯一)
加载数据
首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的。
import pandas as pd
#这里说明一下,clean_beer.csv数据有两千多行数据
#所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习
data = pd.read_csv('clean_beer.csv')
data_sam = data.sample(frac=0.1,weights=data['ounces'].values)
data_sam1 = data_sam
data_sam
我们采用data[‘ounces']列为权重对数据进行采样,并将结果赋值给data_sam1,其中data_sam和data_sam1是后续我们需要用到的两个数据(因为需要将两个数据合并,并去除重复)
此时,data_sam和data_sam1的数据是一样的。
data_sam数据
data_sam
data_sam1数据
data_sam1
sample抽样函数
简要介绍一下sample函数
df.sample()就是抽样函数,参数如下:
df.sample(n=None,frac=None,replace=Flase,weights=None,random_state=None,axis=None)
参数说明:
n:就是样本量,如果不写,就是抽一条数据
frac:抽样比,就是样本量占全样本的比例,如frac=0.3 ,注意n和frac不能共存
replace:是否放回,默认是不放回,如果有放回(replace=True)可以选择比df长度更多的元素回来
weights:样本权重,自动归一化,可以以某一列为权重
random_state:随机状态。就是为了保证程序每次运行得到的结果都一样
axis:抽样维度,0是行,1是列,默认为0
指定需要更新的值
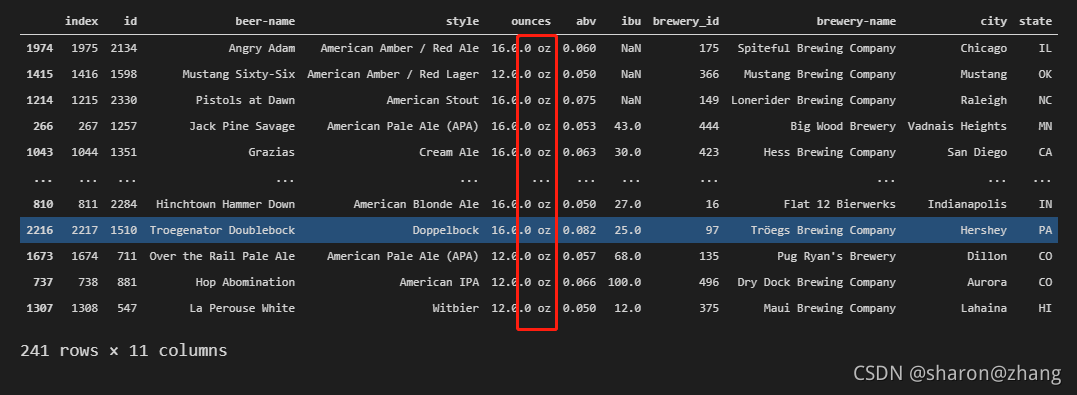
接下来,我们对data_sam1的值进行更新,主要是将data_sam1的ounces属性列值加上后缀'.0 oz',具体代码如下:
data_sam1['ounces'] = data_sam1['ounces'].astype('str') + '.0 oz'
data_sam1
对data_sam1的值进行显示,其中我们可以看到,ounces的值已经全部加上了我们所指定的后缀:
现在,我们已经得到的新的值,接下来的目标就是如何将我们已经得到的新值,更新到data_sam中
append直接添加
从标题可以看到,我们使用的是append方法进行直接添加。
data_sam = data_sam.append(data_sam1,ignore_index=True) data_sam
我们将data_sam1使用append方法添加到data_sam最后一行的后面。下面展示其结果,并详细介绍append的用法。
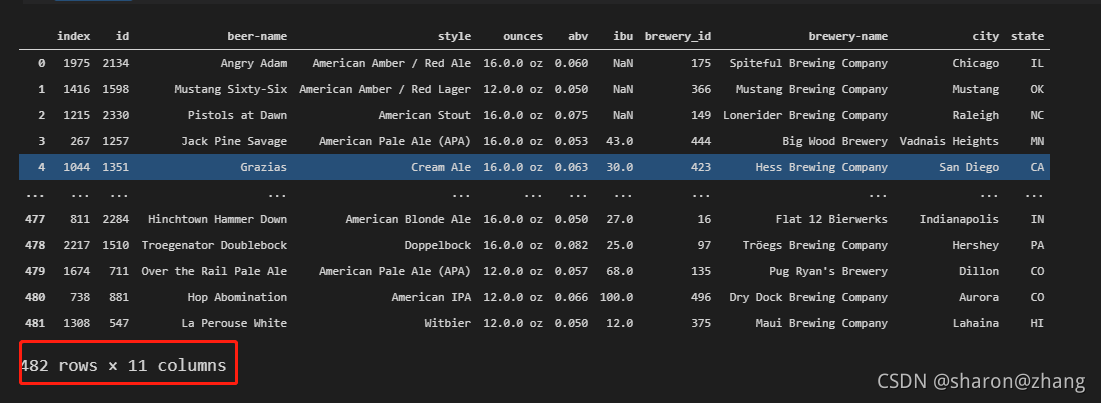
可以看到,行数已经有原来的241改为现在的482rows,显然我们此时已经成功使用append添加数据成功。不过我们想要的不止是简简单单的添加数据在最后一行,而是想要把我们增加后缀的那一列更新到原来的数据中,所以最后一步就是去重。
append函数用法
append()函数的语法为:
DataFrame.append(other,ignore_index=False,verify_integrity=False,sort=None)
参数说明:
other: DataFrame,Series或Dict式对象,其行将添加到调用方DataFrame中。
ignore_index: 如果为True,则将忽略源DataFrame对象中的索引。
verify_integrity:如果为True,则在创建具有重复项的索引时引发ValueError 。
sort: 如果源DataFrame列未对齐,则对列进行排序。 不建议使用此功能。 因此,我们必须传递sort=True来排序和静音警告消息。 如果传递了sort=False ,则不会对列进行排序,并且会忽略警告。
根据某一列key值进行去重(key唯一)
接下来,就是最后一个步骤,也就是根据ounces列对数据进行去重。
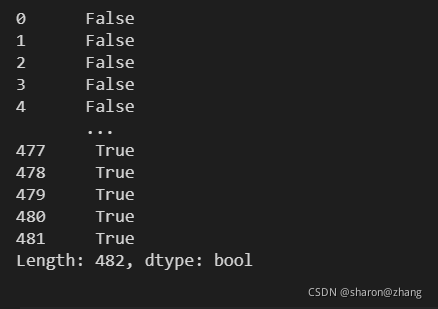
通过duplicated()函数可以看到数据还是有很多重复的。
data_sam.duplicated(['id'],keep='first')
DataFrame.drop_duplicated(self,subset = None,keep ='first')
subset : 列标签或标签序列,可选仅考虑某些列来标识重复项,默认情况下使用所有列
keep : {'first','last',False},默认为'first'
first:将重复项标记True为第一次出现的除外。
last:将重复项标记True为最后一次除外。
False:将所有重复项标记为True。
既然知道数据中是有重复项的,通过对数据的观察可以看到,数据的id是唯一的,所以我们以id这一列为契机,来进行我们的去重操作。具体代码如下:
data_sam = data_sam.drop_duplicates(subset = 'id') data_sam
最后来看一看,我们最后的结果是不是已经成功去重,或者说是不是我们想要的最终结果呢???
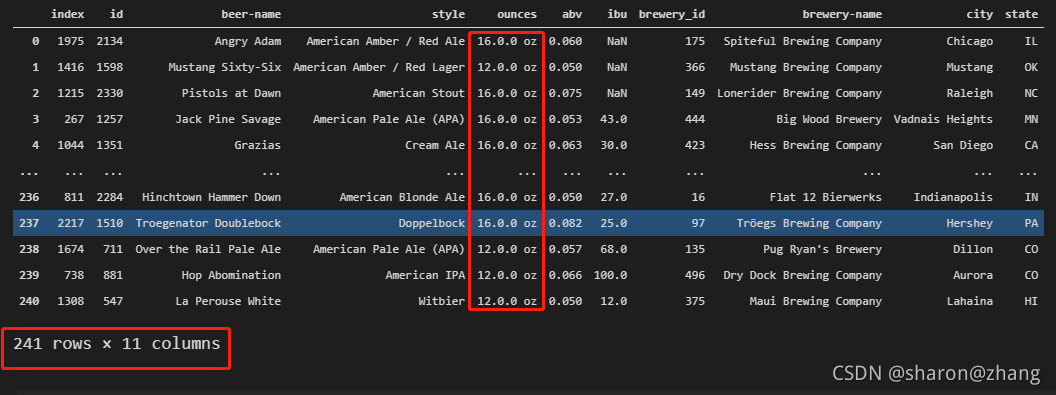
根据上面的图片结果,可以看到我们已经执行成功,得到的确实是我们起初想要的一个数据结果。有兴趣的也可以去试一下merge和update联合的操作进行更新数据,看看是不是也能成功。
以上就是Python教程pandas数据分析的详细内容,希望通过记录能够加强记忆,并帮到和我一样正在学习的你,更多关于pandas数据分析去重复值的资料请关注我们其它相关文章!感谢阅读~
相关推荐
-

手把手带你了解Python数据分析--matplotlib
目录 柱形图 条形图 折线图 饼图和圆环图 分离饼图块 圆环图 总结 柱形图 bar()函数绘制柱形图 import matplotlib.pyplot as pl x = [1,2,3,4,5,6,7] y = [15,69,85,12,36,95,11] pl.bar(x,y) pl.show() bar()函数的参数width和color设置每根柱子的宽度和颜色 有中文时要添加 pl.rcParams['font.sans-serif'] = ['FangSong'] 有负号时要添加 pl
-
python数据分析必会的Pandas技巧汇总
目录 一.Pandas两大数据结构的创建 二.DataFrame常见方法 三.数据索引 四.DataFrame选取和重新组合数据的方法 五.排序 六.相关分析和统计分析 七.分组的方法 八.读写文本格式数据的方法 九.处理缺失数据 十.数据转换 一.Pandas两大数据结构的创建 序号 方法 说明 1 pd.Series(对象,index=[ ]) 创建Series.对象可以是列表\ndarray.字典以及DataFrame中的某一行或某一列 2 pd.DataFrame(data,column
-
Python数据分析JupyterNotebook3魔法命令详解及示例
目录 1.魔法命令介绍 %lsmagic:列出所有magics命令 %quickref:输出所有魔法指令的简单版帮助文档 %Magics_Name?:输出某个魔法命令详细帮助文档 2.Line magics:Line魔法指令 3.Cell magics:Cell魔法指令 写bash程序 写perl程序 1.魔法命令介绍 %lsmagic:列出所有magics命令 Available line magics:[对当前行使用共计93个] %alias %alias_magic %autoawait
-
python数据分析之DataFrame内存优化
目录 1. pandas查看数据占用大小 2. 对数据进行压缩 3. 参考资料
-
利用python数据分析处理进行炒股实战行情
作为一个新手,你需要以下3个步骤: 1.用户注册 > 2.获取token > 3.调取数据 数据内容: 包含股票.基金.期货.债券.外汇.行业大数据, 同时包括了数字货币行情等区块链数据的全数据品类的金融大数据平台, 为各类金融投资和研究人员提供适用的数据和工具. 1.数据采集 我们进行本地化计算,首先要做的,就是将所需的基础数据采集到本地数据库里 本篇的示例源码采用的数据库是MySQL5.5,数据源是xxx pro接口. 我们现在要取一批特定股票的日线行情 部分代码如下: # 设置xxxxx
-
Python 数据分析之Beautiful Soup 提取页面信息
概述 数据分析 (Data Analyze) 可以在工作中的各个方面帮助我们. 本专栏为量化交易专栏下的子专栏, 主要讲解一些数据分析的基础知识. Beautiful Soup Beautiful 是一个可以从 HTML 或 XML 文件中提取数据的 Pyhton 库. 简单来说, 它能将 HTML 的标签文件解析成树形结构, 然后方便的获取到指定标签的对应属性. 安装: pip install beautifulsoup4 例子: from bs4 import BeautifulSoup #
-
Python通过四大 AutoEDA 工具包快速产出完美数据报告
AutoEDA工具包对于刚刚学习数据分析的小伙伴可以带来非常大的帮助. 本篇文章我们介绍目前最流行的四大AutoEDA工具包. D-tale Pandas-Profiling Sweetviz AutoViz 这几个工具包可以以短短三五行代码帮新手节省将近一天时间去写代码分析,非常建议大家收藏学习,喜欢点赞支持,文末提供技术交流群,尽情畅聊. 介绍 01 D-Tale D-Tale是Flask后端和React前端组合的产物,也是一个开源的Python自动可视化库,可以为我们提供查看和分析Pand
-
简单且有用的Python数据分析和机器学习代码
为什么选择Python进行数据分析? Python是一门动态的.面向对象的脚本语言,同时也是一门简约,通俗易懂的编程语言.Python入门简单,代码可读性强,一段好的Python代码,阅读起来像是在读一篇外语文章.Python这种特性称为"伪代码",它可以使你只关心完成什么样的工作任务,而不是纠结于Python的语法. 另外,Python是开源的,它拥有非常多优秀的库,可以用于数据分析及其他领域.更重要的是,Python与最受欢迎的开源大数据平台Hadoop具有很好的兼容性.因此,学习
-
Python教程pandas数据分析去重复值
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs
-
获取python的list中含有重复值的index方法
关于怎么获得,我想其实网上有很多答案. list.index( )获得值的索引值,但是如果list中含有的值一样,例如含有两个11,22,这样每次获得的都是第一个值的位置. 那么怎么去解决这个问题呢? 下面的程序对这个问题做了一定的解答 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Author : SundayCoder-俊勇 # @File : listlearn.py # 怎么获得list中的相同值的索引值 # 请看下列程序 s = [1
-
JS实现数组去重复值的方法示例
本文实例讲述了JS实现数组去重复值的方法.分享给大家供大家参考,具体如下: 运行效果图如下: 完整实例代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml&
-
pandas中DataFrame检测重复值的实现
本文详解如何使用pandas查看dataframe的重复数据,判断是否重复,以及如何去重 DataFrame.duplicated(subset=None, keep='first') subset:如果你认为几个字段重复,则数据重复,就把那几个字段以列表形式放到subset后面.默认是所有字段重复为重复数据. keep: 默认为'first' ,也就是如果有重复数据,则第一条出现的定义为False,后面的重复数据为True. 如果为'last',也就是如果有重复数据,则最后一条出现的定义为Fa
-
Python 第三方库 Pandas 数据分析教程
目录 Pandas导入 Pandas与numpy的比较 Pandas的Series类型 Pandas的Series类型的创建 Pandas的Series类型的基本操作 pandas的DataFrame类型 pandas的DataFrame类型创建 Pandas的Dataframe类型的基本操作 pandas索引操作 pandas重新索引 pandas删除索引 pandas数据运算 算术运算 Pandas数据分析 pandas导入与导出数据 导入数据 导出数据 Pandas查看.检查数据 Pand
-
Python Pandas中DataFrame.drop_duplicates()删除重复值详解
目录 语法 参数 结果展示 扩展:识别重复值 总结 语法 df.drop_duplicates(subset = None, keep = 'first', inplace = False, ignore_index = False) 参数 1.subset:指定的标签或标签序列,仅删除这些列重复值,默认情况为所有列 2.keep:确定要保留的重复值,有以下可选项: first:保留第一次出现的重复值,默认 last:保留最后一次出现的重复值 False:删除所有重复值 3.inplace:是否
-
Python运用于数据分析的简单教程
最近,Analysis with Programming加入了Planet Python.作为该网站的首批特约博客,我这里来分享一下如何通过Python来开始数据分析.具体内容如下: 数据导入 导入本地的或者web端的CSV文件: 数据变换: 数据统计描述: 假设检验 单样本t检验: 可视化: 创建自定义函数. 数据导入 这是很关键的一步,为了后续的分析我们首先需要导入数据.通常来说,数据是CSV格式,就算不是,至少也可以转
-
Python实现嵌套列表及字典并按某一元素去重复功能示例
本文实例讲述了Python实现嵌套列表及字典并按某一元素去重复功能.分享给大家供大家参考,具体如下: #! /usr/bin/env python #coding=utf-8 class HostScheduler(object): def __init__(self, resource_list): self.resource_list = resource_list def MergeHost(self): allResource=[] allResource.append(self.res
-
python重复值处理得方法
前言: 如果大家接触过数据分析,那么大家可能都知道,最让人头疼的就是在数据录入的过程中,不可避免的会产生重复值,缺失值和异常值了,python也提供了一些方法让我们处理这些值.下面让我们一块来学习一下吧~ 今天,先处理重复值,首先创建一个包含重复值的DataFrame,如下: import pandas as pd data = pd.DataFrame([[1,2],[1,2],[3,4]],columns = ['a','b']) print(data) 我们将其打印出来,结果如下: 可以看
-
Python 数据分析教程探索性数据分析
目录 什么是探索性数据分析(EDA)? 描述性统计 分组数据 方差分析 相关性和相关性计算 什么是探索性数据分析(EDA)? EDA 是数据分析下的一种现象,用于更好地理解数据方面,例如: – 数据的主要特征 – 变量和它们之间的关系 – 确定哪些变量对我们的问题很重要 我们将研究各种探索性数据分析方法, 例如: 描述性统计,这是一种简要概述我们正在处理的数据集的方法,包括样本的一些度量和特征 分组数据 [使用group by 进行基本分组] ANOVA,方差分析,这是一种计算方法,可将观察集