解析Linux源码之epoll
目录
- 一、前言
- 二、简单的epoll例子
- 2.1、epoll_create
- 2.2、struct eventpoll
- 2.3、epoll_ctl(add)
- 2.4、ep_insert
- 2.5、tfile->f_op->poll的实现
- 2.6、回调函数的安装
- 2.7、epoll_wait
- 2.8、ep_send_events
- 三、事件到来添加到epoll就绪队列(rdllist)的过程
- 3.1、可读事件到来
- 3.2、可写事件到来
- 四、关闭描述符(close fd)
- 五、总结
一、前言
在linux的高性能网络编程中,绕不开的就是epoll。和select、poll等系统调用相比,epoll在需要监视大量文件描述符并且其中只有少数活跃的时候,表现出无可比拟的优势。epoll能让内核记住所关注的描述符,并在对应的描述符事件就绪的时候,在epoll的就绪链表中添加这些就绪元素,并唤醒对应的epoll等待进程。
二、简单的epoll例子
下面的例子,是从笔者本人用c语言写的dbproxy中的一段代码。由于细节过多,所以做了一些删减。
int init_reactor(int listen_fd,int worker_count){
......
// 创建多个epoll fd,以充分利用多核
for(i=0;i<worker_count;i++){
reactor->worker_fd = epoll_create(EPOLL_MAX_EVENTS);
}
/* epoll add listen_fd and accept */
// 将accept后的事件加入到对应的epoll fd中
int client_fd = accept(listen_fd,(struct sockaddr *)&client_addr,&client_len)));
// 将连接描述符注册到对应的worker里面
epoll_ctl(reactor->client_fd,EPOLL_CTL_ADD,epifd,&event);
}
// reactor的worker线程
static void* rw_thread_func(void* arg){
......
for(;;){
// epoll_wait等待事件触发
int retval = epoll_wait(epfd,events,EPOLL_MAX_EVENTS,500);
if(retval > 0){
for(j=0; j < retval; j++){
// 处理读事件
if(event & EPOLLIN){
handle_ready_read_connection(conn);
continue;
}
/* 处理其它事件 */
}
}
}
......
}
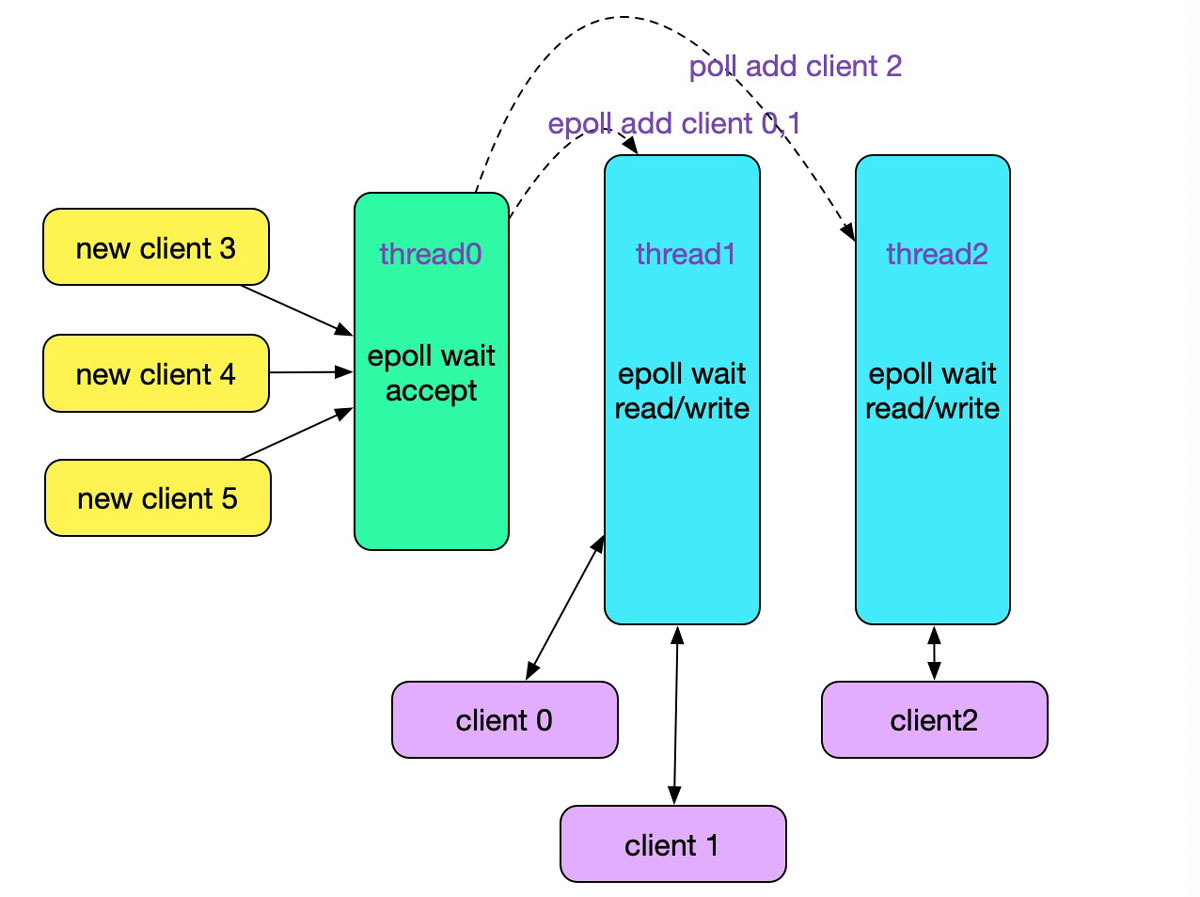
上述代码事实上就是实现了一个reactor模式中的accept与read/write处理线程,如下图所示:
2.1、epoll_create
Unix的万物皆文件的思想在epoll里面也有体现,epoll_create调用返回一个文件描述符,此描述符挂载在anon_inode_fs(匿名inode文件系统)的根目录下面。让我们看下具体的epoll_create系统调用源码:
SYSCALL_DEFINE1(epoll_create, int, size)
{
if (size <= 0)
return -EINVAL;
return sys_epoll_create1(0);
}
由上述源码可见,epoll_create的参数是基本没有意义的,kernel简单的判断是否为0,然后就直接就调用了sys_epoll_create1。由于linux的系统调用是通过(SYSCALL_DEFINE1,SYSCALL_DEFINE2......SYSCALL_DEFINE6)定义的,那么sys_epoll_create1对应的源码即是SYSCALL_DEFINE(epoll_create1)。
(注:受限于寄存器数量的限制,(80x86下的)kernel限制系统调用最多有6个参数。据ulk3所述,这是由于32位80x86寄存器的限制)
接下来,我们就看下epoll_create1的源码:
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
// kzalloc(sizeof(*ep), GFP_KERNEL),用的是内核空间
error = ep_alloc(&ep);
// 获取尚未被使用的文件描述符,即描述符数组的槽位
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
// 在匿名inode文件系统中分配一个inode,并得到其file结构体
// 且file->f_op = &eventpoll_fops
// 且file->private_data = ep;
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
// 将file填入到对应的文件描述符数组的槽里面
fd_install(fd,file);
ep->file = file;
return fd;
}
最后epoll_create生成的文件描述符如下图所示:

2.2、struct eventpoll
所有的epoll系统调用都是围绕eventpoll结构体做操作,现简要描述下其中的成员:
/*
* 此结构体存储在file->private_data中
*/
struct eventpoll {
// 自旋锁,在kernel内部用自旋锁加锁,就可以同时多线(进)程对此结构体进行操作
// 主要是保护ready_list
spinlock_t lock;
// 这个互斥锁是为了保证在eventloop使用对应的文件描述符的时候,文件描述符不会被移除掉
struct mutex mtx;
// epoll_wait使用的等待队列,和进程唤醒有关
wait_queue_head_t wq;
// file->poll使用的等待队列,和进程唤醒有关
wait_queue_head_t poll_wait;
// 就绪的描述符队列
struct list_head rdllist;
// 通过红黑树来组织当前epoll关注的文件描述符
struct rb_root rbr;
// 在向用户空间传输就绪事件的时候,将同时发生事件的文件描述符链入到这个链表里面
struct epitem *ovflist;
// 对应的user
struct user_struct *user;
// 对应的文件描述符
struct file *file;
// 下面两个是用于环路检测的优化
int visited;
struct list_head visited_list_link;
};
本文讲述的是kernel是如何将就绪事件传递给epoll并唤醒对应进程上,因此在这里主要聚焦于(wait_queue_head_t wq)等成员。
2.3、epoll_ctl(add)
我们看下epoll_ctl(EPOLL_CTL_ADD)是如何将对应的文件描述符插入到eventpoll中的。
借助于spin_lock(自旋锁)和mutex(互斥锁),epoll_ctl调用可以在多个KSE(内核调度实体,即进程/线程)中并发执行。
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
/* 校验epfd是否是epoll的描述符 */
// 此处的互斥锁是为了防止并发调用epoll_ctl,即保护内部数据结构
// 不会被并发的添加修改删除破坏
mutex_lock_nested(&ep->mtx, 0);
switch (op) {
case EPOLL_CTL_ADD:
...
// 插入到红黑树中
error = ep_insert(ep, &epds, tfile, fd);
...
break;
......
}
mutex_unlock(&ep->mtx);
}
上述过程如下图所示:

2.4、ep_insert
在ep_insert中初始化了epitem,然后初始化了本文关注的焦点,即事件就绪时候的回调函数,代码如下所示:
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
{
/* 初始化epitem */
// &epq.pt->qproc = ep_ptable_queue_proc
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
// 在这里将回调函数注入
revents = tfile->f_op->poll(tfile, &epq.pt);
// 如果当前有事件已经就绪,那么一开始就会被加入到ready list
// 例如可写事件
// 另外,在tcp内部ack之后调用tcp_check_space,最终调用sock_def_write_space来唤醒对应的epoll_wait下的进程
if ((revents & event->events) && !ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
// wake_up ep对应在epoll_wait下的进程
if (waitqueue_active(&ep->wq)){
wake_up_locked(&ep->wq);
}
......
}
// 将epitem插入红黑树
ep_rbtree_insert(ep, epi);
......
}
2.5、tfile->f_op->poll的实现
向kernel更底层注册回调函数的是tfile->f_op->poll(tfile, &epq.pt)这一句,我们来看一下对于对应的socket文件描述符,其fd=>file->f_op->poll的初始化过程:
// 将accept后的事件加入到对应的epoll fd中 int client_fd = accept(listen_fd,(struct sockaddr *)&client_addr,&client_len))); // 将连接描述符注册到对应的worker里面 epoll_ctl(reactor->client_fd,EPOLL_CTL_ADD,epifd,&event);
回顾一下上述user space代码,fd即client_fd是由tcp的listen_fd通过accept调用而来,那么我们看下accept调用链的关键路径:
accept
|->accept4
|->sock_attach_fd(newsock, newfile, flags & O_NONBLOCK);
|->init_file(file,...,&socket_file_ops);
|->file->f_op = fop;
/* file->f_op = &socket_file_ops */
|->fd_install(newfd, newfile); // 安装fd
那么,由accept获得的client_fd的结构如下图所示:

(注:由于是tcp socket,所以这边sock->ops=inet_stream_ops,既然知道了tfile->f_op->poll的实现,我们就可以看下此poll是如何将安装回调函数的。
2.6、回调函数的安装
kernel的调用路径如下:
sock_poll /*tfile->f_op->poll(tfile, &epq.pt)*/;
|->sock->ops->poll
|->tcp_poll
/* 这边重要的是拿到了sk_sleep用于KSE(进程/线程)的唤醒 */
|->sock_poll_wait(file, sk->sk_sleep, wait);
|->poll_wait
|->p->qproc(filp, wait_address, p);
/* p为&epq.pt,而且&epq.pt->qproc= ep_ptable_queue_proc*/
|-> ep_ptable_queue_proc(filp,wait_address,p);
绕了一大圈之后,我们的回调函数的安装其实就是调用了eventpoll.c中的ep_ptable_queue_proc,而且向其中传递了sk->sk_sleep作为其waitqueue的head,其源码如下所示:
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
// 取出当前client_fd对应的epitem
struct epitem *epi = ep_item_from_epqueue(pt);
// &pwq->wait->func=ep_poll_callback,用于回调唤醒
// 注意,这边不是init_waitqueue_entry,即没有将当前KSE(current,当前进程/线程)写入到
// wait_queue当中,因为不一定是从当前安装的KSE唤醒,而应该是唤醒epoll\_wait的KSE
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
// 这边的whead是sk->sk_sleep,将当前的waitqueue链入到socket对应的sleep列表
add_wait_queue(whead, &pwq->wait);
}
这样client_fd的结构进一步完善,如下图所示:

ep_poll_callback函数是唤醒对应epoll_wait的地方,我们将在后面一起讲述。
2.7、epoll_wait
epoll_wait主要是调用了ep_poll:
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
/* 检查epfd是否是epoll\_create创建的fd */
// 调用ep_poll
error = ep_poll(ep, events, maxevents, timeout);
...
}
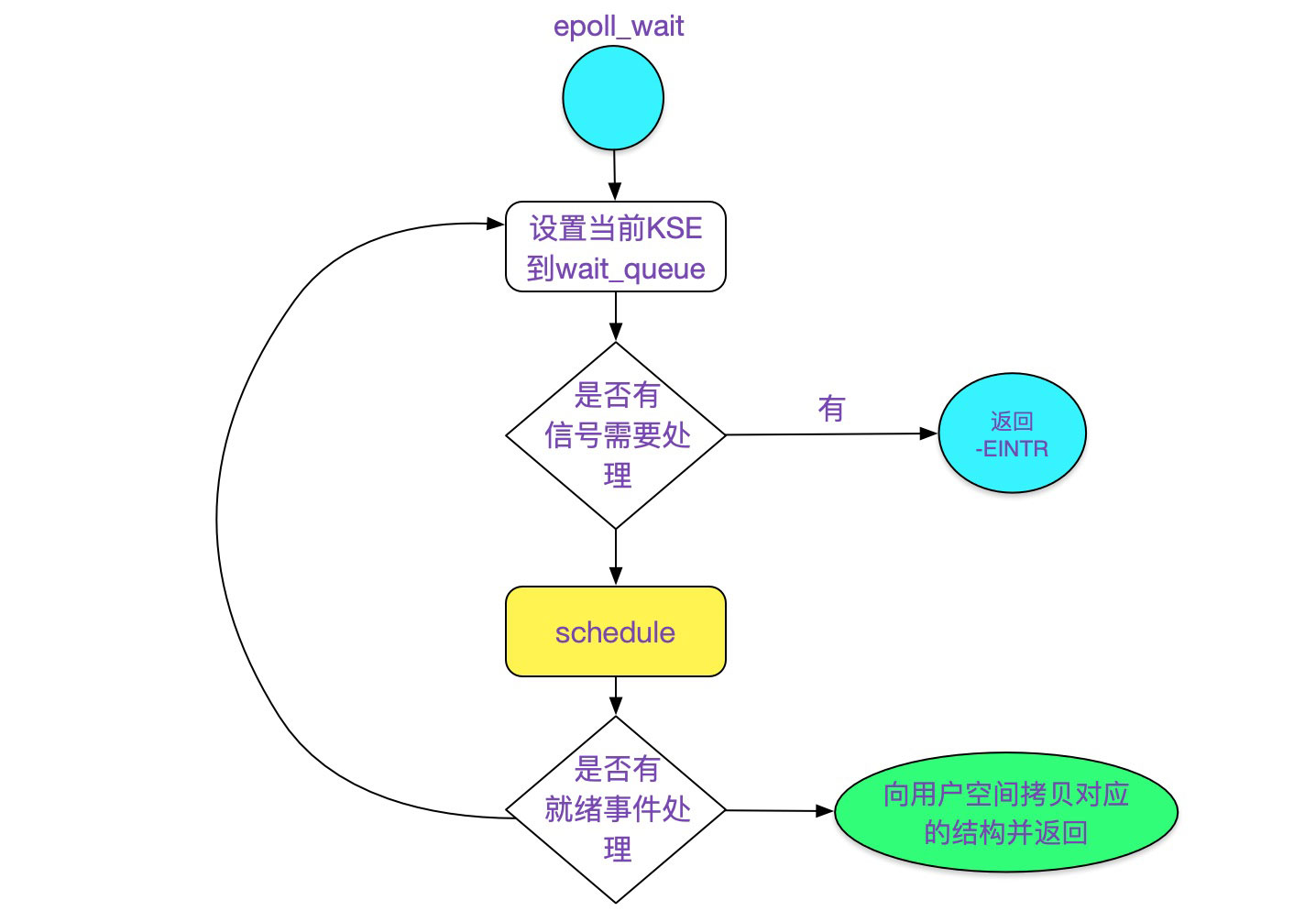
紧接着,我们看下ep_poll函数:
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
......
retry:
// 获取spinlock
spin_lock_irqsave(&ep->lock, flags);
// 将当前task_struct写入到waitqueue中以便唤醒
// wq_entry->func = default_wake_function;
init_waitqueue_entry(&wait, current);
// WQ_FLAG_EXCLUSIVE,排他性唤醒,配合SO_REUSEPORT从而解决accept惊群问题
wait.flags |= WQ_FLAG_EXCLUSIVE;
// 链入到ep的waitqueue中
__add_wait_queue(&ep->wq, &wait);
for (;;) {
// 设置当前进程状态为可打断
set_current_state(TASK_INTERRUPTIBLE);
// 检查当前线程是否有信号要处理,有则返回-EINTR
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irqrestore(&ep->lock, flags);
// schedule调度,让出CPU
jtimeout = schedule_timeout(jtimeout);
spin_lock_irqsave(&ep->lock, flags);
}
// 到这里,表明超时或者有事件触发等动作导致进程重新调度
__remove_wait_queue(&ep->wq, &wait);
// 设置进程状态为running
set_current_state(TASK_RUNNING);
......
// 检查是否有可用事件
eavail = !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR;
......
// 向用户空间拷贝就绪事件
ep_send_events(ep, events, maxevents)
}
上述逻辑如下图所示:
2.8、ep_send_events
ep_send_events函数主要就是调用了ep_scan_ready_list,顾名思义ep_scan_ready_list就是扫描就绪列表:
static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv,
int depth)
{
...
// 将epfd的rdllist链入到txlist
list_splice_init(&ep->rdllist, &txlist);
...
/* sproc = ep_send_events_proc */
error = (*sproc)(ep, &txlist, priv);
...
// 处理ovflist,即在上面sproc过程中又到来的事件
...
}
其主要调用了ep_send_events_proc:
static int ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
for (eventcnt = 0, uevent = esed->events;
!list_empty(head) && eventcnt < esed->maxevents;) {
// 遍历ready list
epi = list_first_entry(head, struct epitem, rdllink);
list_del_init(&epi->rdllink);
// readylist只是表明当前epi有事件,具体的事件信息还是得调用对应file的poll
// 这边的poll即是tcp_poll,根据tcp本身的信息设置掩码(mask)等信息 & 上兴趣事件掩码,则可以得知当前事件是否是epoll_wait感兴趣的事件
revents = epi->ffd.file->f_op->poll(epi->ffd.file, NULL) &
epi->event.events;
if(revents){
/* 将event放入到用户空间 */
/* 处理ONESHOT逻辑 */
// 如果不是边缘触发,则将当前的epi重新加回到可用列表中,这样就可以下一次继续触发poll,如果下一次poll的revents不为0,那么用户空间依旧能感知 */
else if (!(epi->event.events & EPOLLET)){
list_add_tail(&epi->rdllink, &ep->rdllist);
}
/* 如果是边缘触发,那么就不加回可用列表,因此只能等到下一个可用事件触发的时候才会将对应的epi放到可用列表里面*/
eventcnt++
}
/* 如poll出来的revents事件epoll_wait不感兴趣(或者本来就没有事件),那么也不会加回到可用列表 */
......
}
return eventcnt;
}
上述代码逻辑如下所示:

三、事件到来添加到epoll就绪队列(rdllist)的过程
经过上述章节的详述之后,我们终于可以阐述,tcp在数据到来时是怎么加入到epoll的就绪队列的了。
3.1、可读事件到来
首先我们看下tcp数据包从网卡驱动到kernel内部tcp协议处理调用链:
step1:
网络分组到来的内核路径,网卡发起中断后调用netif_rx将事件挂入CPU的等待队列,并唤起软中断(soft_irq),再通过linux的软中断机制调用net_rx_action,如下图所示:

注:上图来自PLKA(<<深入Linux内核架构>>)
step2:
紧接着跟踪next_rx_action
next_rx_action
|-process_backlog
......
|->packet_type->func 在这里我们考虑ip_rcv
|->ipprot->handler 在这里ipprot重载为tcp_protocol
(handler 即为tcp_v4_rcv)
我们再看下对应的tcp_v4_rcv
tcp_v4_rcv
|->tcp_v4_do_rcv
|->tcp_rcv_state_process
|->tcp_data_queue
|-> sk->sk_data_ready(sock_def_readable)
|->wake_up_interruptible_sync_poll(sk->sleep,...)
|->__wake_up
|->__wake_up_common
|->curr->func
/* 这里已经被ep_insert添加为ep_poll_callback,而且设定了排它标识WQ_FLAG_EXCLUSIVE*/
|->ep_poll_callback
这样,我们就看下最终唤醒epoll_wait的ep_poll_callback函数:
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
// 获取wait对应的epitem
struct epitem *epi = ep_item_from_wait(wait);
// epitem对应的eventpoll结构体
struct eventpoll *ep = epi->ep;
// 获取自旋锁,保护ready_list等结构
spin_lock_irqsave(&ep->lock, flags);
// 如果当前epi没有被链入ep的ready list,则链入
// 这样,就把当前的可用事件加入到epoll的可用列表了
if (!ep_is_linked(&epi->rdllink))
list_add_tail(&epi->rdllink, &ep->rdllist);
// 如果有epoll_wait在等待的话,则唤醒这个epoll_wait进程
// 对应的&ep->wq是在epoll_wait调用的时候通过init_waitqueue_entry(&wait, current)而生成的
// 其中的current即是对应调用epoll_wait的进程信息task_struct
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
}
上述过程如下图所示:

最后wake_up_locked调用__wake_up_common,然后调用了在init_waitqueue_entry注册的default_wake_function,调用路径为:
wake_up_locked
|->__wake_up_common
|->default_wake_function
|->try_wake_up (wake up a thread)
|->activate_task
|->enqueue_task running
将epoll_wait进程推入可运行队列,等待内核重新调度进程,然后epoll_wait对应的这个进程重新运行后,就从schedule恢复,继续下面的ep_send_events(向用户空间拷贝事件并返回)。
wake_up过程如下图所示:

3.2、可写事件到来
可写事件的运行过程和可读事件大同小异:
首先,在epoll_ctl_add的时候预先会调用一次对应文件描述符的poll,如果返回事件里有可写掩码的时候直接调用wake_up_locked以唤醒对应的epoll_wait进程。
然后,在tcp在底层驱动有数据到来的时候可能携带了ack从而可以释放部分已经被对端接收的数据,于是触发可写事件,这一部分的调用链为:
tcp_input.c
tcp_v4_rcv
|-tcp_v4_do_rcv
|-tcp_rcv_state_process
|-tcp_data_snd_check
|->tcp_check_space
|->tcp_new_space
|->sk->sk_write_space
/* tcp下即是sk_stream_write_space*/
最后在此函数里面sk_stream_write_space唤醒对应的epoll_wait进程
void sk_stream_write_space(struct sock *sk)
{
// 即有1/3可写空间的时候才触发可写事件
if (sk_stream_wspace(sk) >= sk_stream_min_wspace(sk) && sock) {
clear_bit(SOCK_NOSPACE, &sock->flags);
if (sk->sk_sleep && waitqueue_active(sk->sk_sleep))
wake_up_interruptible_poll(sk->sk_sleep, POLLOUT |
POLLWRNORM | POLLWRBAND)
......
}
}
四、关闭描述符(close fd)
值得注意的是,我们在close对应的文件描述符的时候,会自动调用eventpoll_release将对应的file从其关联的epoll_fd中删除,kernel关键路径如下:
close fd
|->filp_close
|->fput
|->__fput
|->eventpoll_release
|->ep_remove
所以我们在关闭对应的文件描述符后,并不需要通过epoll_ctl_del来删掉对应epoll中相应的描述符。
五、总结
epoll作为linux下非常优秀的事件触发机制得到了广泛的运用。其源码还是比较复杂的,本文只是阐述了epoll读写事件的触发机制。
以上就是解析Linux源码之epoll的详细内容,更多关于Linux源码 epoll的资料请关注我们其它相关文章!
相关推荐
-

Linux下源码编译安装配置SVN服务器的步骤分享
说明: SVN(subversion)的运行方式有两种: 一种是基于Apache的http.https网页访问形式: 还有一种是基于svnserve的独立服务器模式. SVN的数据存储方式也有两种:一种是在Berkeley DB数据库中存储数据:另一种是使用普通的文件FSFS存储数据. 由于Berkeley DB方式在使用中有可能锁住数据,一般建议使用FSFS方式更安全. 实现目的: 以svnserve的独立服务器模式,使用FSFS数据存储方式源码编译安装配置SVN服务器. 具体操作: 操作系统
-
linux内核select/poll,epoll实现与区别
下面文章在这段时间内研究 select/poll/epoll的内核实现的一点心得体会: select,poll,epoll都是多路复用IO的函数,简单说就是在一个线程里,可以同时处理多个文件描述符的读写. select/poll的实现很类似,epoll是从select/poll扩展而来,主要是为了解决select/poll天生的缺陷. epoll在内核版本2.6以上才出现的新的函数,而他们在linux内核中的实现都是十分相似. 这三种函数都需要设备驱动提供poll回调函数,对于套接字而言,他们是
-
linux epoll机制详解
在linux 没有实现epoll事件驱动机制之前,我们一般选择用select或者poll等IO多路复用的方法来实现并发服务程序.在linux新的内核中,有了一种替换它的机制,就是epoll. select()和poll() IO多路复用模型 select的缺点: 1.单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,当然可以更改数量,但由于select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差:(在linux内核头文件中,有这样的定义:#define __FD_SE
-
SUSE Linux下源码编译方式安装MySQL 5.6过程分享
MySQL为开源数据库,因此可以基于源码实现安装.基于源码安装有更多的灵活性.也就是说我们可以针对自己的硬件平台选用合适的编译器来优化编译后的二进制代码,根据不同的软件平台环境调整相关的编译参数,选择自身需要选择不同的安装组件,设定需要的字符集等等一些可以根据特定应用场景所作的各种调整.本文描述了如何在源码方式下安装MySQL. 1.安装环境及介质 复制代码 代码如下: #安装环境 SZDB:~ # cat /etc/issue Welcome to SUSE Linux Enterprise
-
linux下源码安装mysql5.6.20教程
linux下MySQL 5.6源码安装记录如下 1.下载:当前mysql版本到了5.6.20 http://dev.mysql.com/downloads/mysql 选择Source Code 2.必要软件包 复制代码 代码如下: yum -y install gcc gcc-c++ gcc-g77 autoconf automake zlib* fiex* libxml* ncurses-devel libmcrypt* libtool-ltdl-devel* make cmake 3.编
-
python实现Linux异步epoll代码
复制代码 代码如下: import socketimport select if __name__=="__main__": s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) s.bind(("",20123)) s.listen(10) epoll=select.epoll()
-
Linux下安装mysql的方式(yum和源码编译两种方式)
这里介绍Linux下两种安装mysql的方式:yum安装和源码编译安装. 1. yum安装 (1)首先查看centos自带的mysql是否被安装: # yum list installed |grep mysql //若有自带安装的mysql,将其卸载 # yum -y remove mysql-libs.x86_64 (2)下载MySQL官网的yum仓库:https://dev.mysql.com/downloads/repo/yum/, # yum localinstall mysql57-
-
Linux+php+apache+oracle环境搭建之CentOS下源码编译安装PHP
首先需要安装下面几个安装包,可以在CD-ROM数据源里找到以下安装包yum安装 yum install perl* freetype libpng* libxm2 libxm2-devel curl curl-devel libjpeg* 手动下载安装 jpegsrc.v8c.tar libmcrypt-2.5.8.tar.gz 安装 jpegsrc # tar -xvzf jpegsrc.v8c.tar # cd jpeg-8c # ./configure --prefix=/usr/loca
-
Linux IO多路复用之epoll网络编程
前言 本章节是用基本的Linux基本函数加上epoll调用编写一个完整的服务器和客户端例子,可在Linux上运行,客户端和服务端的功能如下: 客户端从标准输入读入一行,发送到服务端 服务端从网络读取一行,然后输出到客户端 客户端收到服务端的响应,输出这一行到标准输出 服务端 代码如下: #include <unistd.h> #include <sys/types.h> /* basic system data types */ #include <sys/socket.h&
-
解析Linux源码之epoll
目录 一.前言 二.简单的epoll例子 2.1.epoll_create 2.2.struct eventpoll 2.3.epoll_ctl(add) 2.4.ep_insert 2.5.tfile->f_op->poll的实现 2.6.回调函数的安装 2.7.epoll_wait 2.8.ep_send_events 三.事件到来添加到epoll就绪队列(rdllist)的过程 3.1.可读事件到来 3.2.可写事件到来 四.关闭描述符(close fd) 五.总结 一.前言 在linu
-
从Linux源码看Socket(TCP)Client端的Connect的示例详解
前言 笔者一直觉得如果能知道从应用到框架再到操作系统的每一处代码,是一件Exciting的事情. 今天笔者就来从Linux源码的角度看下Client端的Socket在进行Connect的时候到底做了哪些事情.由于篇幅原因,关于Server端的Accept源码讲解留给下一篇博客. (基于Linux 3.10内核) 一个最简单的Connect例子 int clientSocket; if((clientSocket = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
-
详解从Linux源码看Socket(TCP)的bind
目录 一.一个最简单的Server端例子 二.bind系统调用 2.1.inet_bind 2.2.inet_csk_get_port 三.判断端口号是否冲突 四.SO_REUSEADDR和SO_REUSEPORT 五.SO_REUSEADDR 六.SO_REUSEPORT 七.总结 一.一个最简单的Server端例子 众所周知,一个Server端Socket的建立,需要socket.bind.listen.accept四个步骤. 代码如下: void start_server(){ // se
-
解析xHTML源码的DLL组件AngleSharp介绍
AngleSharp是基于.NET(C#)开发的专门为解析xHTML源码的DLL组件. 项目地址:https://github.com/FlorianRappl/AngleSharp 我主要介绍是一些使用AngleSharp常用的方法,跟大家介绍,我会以我们站点作为原型. 其它的类似组件有: 国内:Jumony github地址: https://github.com/Ivony/Jumony 国外:Html Agility Pack 项目地址:http://htmlagilitypack.co
-
分析从Linux源码看TIME_WAIT的持续时间
目录 一.前言 二.首先介绍下Linux环境 三.TIME_WAIT状态转移图 四.持续时间真如TCP_TIMEWAIT_LEN所定义么? 五.TIME_WAIT定时器源码 5.1.inet_twsk_schedule 5.2.具体的清理函数 5.3.先作出一个假设 5.4.如果一个slot中的TIME_WAIT<=100 5.5.如果一个slot中的TIME_WAIT>100 5.6.PAWS(Protection Against Wrapped Sequences)使得TIME_WAIT延
-
解析spark源码yarn-cluster模式任务提交
目录 一,运行命令 二,任务提交流程图 三,启动脚本 四,程序入口类org.apache.spark.deploy.SparkSubmit 五,org.apache.spark.deploy.yarn.YarnClusterApplication类 六, org.apache.spark.deploy.yarn.ApplicationMaster 类. 一,运行命令 bin/spark-submit \ --master yarn \ --deploy-mode cluster \ --clas
-
Vue3 AST解析器-源码解析
目录 1.生成 AST 抽象语法树 2.创建 AST 的根节点 3.解析子节点 4.解析模板元素 Element 5.示例:模板元素解析 上一篇文章Vue3 编译流程-源码解析中,我们从 packges/vue/src/index.ts 的入口开始,了解了一个 Vue 对象的编译流程,在文中我们提到 baseCompile 函数在执行过程中会生成 AST 抽象语法树,毫无疑问这是很关键的一步,因为只有拿到生成的 AST 我们才能遍历 AST 的节点进行 transform 转换操作,比如解析 v
-
Python爬虫实战之网易云音乐加密解析附源码
目录 环境 知识点 第一步 第二步 开始代码 先导入所需模块 请求数据 提取我们真正想要的 音乐的名称 id 导入js文件 保存文件 完整代码 环境 python3.8 pycharm2021.2 知识点 requests >>> pip install requests execjs >>> pip install PyExecJS 第一步 打开这个网站 在里面去分析我们需要的数据 每个音乐的名称 id 去网页源代码查找数据,发现并没有,这个网页 并不是一个静态页面
-
Vue编译器解析compile源码解析
目录 引言 解析 compile compile 源码 配置选项 属性分别解析 finalOptions添加warn 方法 两个特殊的属性处理 引言 在上篇文章 Vue编译器源码分析compileToFunctions作用中我们介绍到了,在 compileToFunctions 方法中: // compile var compiled = compile(template, options); 而真正的编译工作是依托于 compile 函数,接下来我们详细解析 compile . 解析 comp
-
深入解析vue 源码目录及构建过程分析
" 本文主要梳理一下vue代码的目录,以及vue代码构建流程,旨在对vue源码整体有一个认知,有助于后续对源码的阅读." 一.目录结构 上图是对vue的代码的所有目录进行的梳理,其中源码位于src目录下,下面对src下的目录进行介绍. compiler 该目录是编译相关的代码,即将 template 模板转化成 render 函数的代码. vue 提供了 render 函数,render 函数作用是用来创建 VNode,但在平时开发中,绝大多数情况下使用 template 来创建 H