Python数据分析之pandas读取数据
一、三种数据文件的读取

二、csv、tsv、txt 文件读取
1)CSV文件读取:
语法格式:pandas.read_csv(文件路径)
CSV文件内容如下:

import pandas as pd file_path = "e:\\pandas_study\\test.csv" content = pd.read_csv(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回一个元组(总行数,总列数),总行数不包括标题行 content.index # 返回索引,是一个可迭代的对象<class 'pandas.core.indexes.range.RangeIndex'> content.column # 返回所有的列名 Index(['姓名', '年龄', '籍贯'], dtype='object') content.dtypes # 返回的是每列的数据类型 姓名 object 年龄 int64 籍贯 object dtype: object
2)CSV文件读取:
语法格式:pandas.read_csv(文件路径)
CSV文件内容如下:

import pandas as pd file_path = "e:\\pandas_study\\test2.txt" content = pd.read_csv(file_path,sep='\t',header = None ,names= ['name','age','adress']) #参数说明: # header = None 表示没有标题行 # sep='\t' 表示去除分割符中的空格 # names= ['name','age','adress'] ,列名依次自定义为'name','age','adress' content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回一个元组(总行数,总列数),总行数不包括标题行 content.index # 返回索引,是一个可迭代的对象<class 'pandas.core.indexes.range.RangeIndex'> content.column # 返回所有的列名 Index(['姓名', '年龄', '籍贯'], dtype='object') content.dtypes # 返回的是每列的数据类型
三、excel文件读取
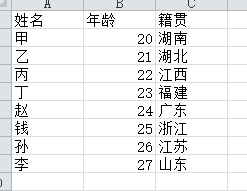
import pandas as pd file_path = "e:\\pandas_study\\test3.xlsx" content = pd.read_excel(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回一个元组(总行数,总列数),总行数不包括标题行 content.index # 返回索引,是一个可迭代的对象<class 'pandas.core.indexes.range.RangeIndex'> content.column # 返回所有的列名 Index(['姓名', '年龄', '籍贯'], dtype='object') content.dtypes # 返回的是每列的数据类型 姓名 object 年龄 int64 籍贯 object dtype: object
四、数据库表格读取
语法: pandas.read_sql(sql语句,数据库连接对象)
数据对象的创建,可以根据pymysql,cx_oracle等模块连接mysql或者oracle。
到此这篇关于Python数据分析之pandas读取数据的文章就介绍到这了,更多相关pandas读取数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
利用python Pandas实现批量拆分Excel与合并Excel
一.实例演示 1.将一个大Excel等份拆成多个Excel 2.将多个小Excel合并成一个大Excel并标记来源 work_dir="./course_datas/c15_excel_split_merge" splits_dir=f"{work_dir}/splits" import os if not os.path.exists(splits_dir): os.mkdir(splits_dir) 二.读取源Excel到Pandas import pandas
-
python 使用pandas同时对多列进行赋值
如dataframe data1['月份']=int(month) #加入月份和企业名称 data1['企业']=parmentname 可以增加单列,并赋值,如果想同时对多列进行赋值 data1['月份','企业']=int(month) , parmentname #加入月份和企业名称 会出错 ValueError: Length of values does not match length of index data[['合计','平均']]='数据','月份' 类似这样的,也无效 Ke
-

python基于Pandas读写MySQL数据库
要实现 pandas 对 mysql 的读写需要三个库 pandas sqlalchemy pymysql 可能有的同学会问,单独用 pymysql 或 sqlalchemy 来读写数据库不香么,为什么要同时用三个库?主要是使用场景不同,个人觉得就大数据处理而言,用 pandas 读写数据库更加便捷. 1.read_sql_query 读取 mysql read_sql_query 或 read_sql 方法传入参数均为 sql 语句,读取数据库后,返回内容是 dateframe 对象.普及一下
-
Python3 pandas.concat的用法说明
前面给大家分享了pandas.merge用法详解,这节分享pandas数据合并处理的姊妹篇,pandas.concat用法详解,参考利用Python进行数据分析与pandas官网进行整理. pandas.merge参数列表如下图,其中只有objs是必须得参数,另外常用参数包括objs.axis.join.keys.ignore_index. 1.pd.concat([df1,df2,df3]), 默认axis=0,在0轴上合并. 2.pd.concat([df1,df4],axis=1)–在1轴
-
Python基础之pandas数据合并
一.concat concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False) axis: 需要合并链接的轴,0是行,1是列join:连接的方式 inner,或者outer 二.相同字段的表首尾相接 #现将表构成l
-
python pandas合并Sheet,处理列乱序和出现Unnamed列的解决
使用python中的pandas,xlrd,openpyxl库完成合并excel中指定sheet的操作 # -*- coding: UTF-8 -*- import xlrd import pandas as pd from pandas import DataFrame from openpyxl import load_workbook #表格位置 excel_name = '1.xlsx' # 获取workbook中所有的表格 wb = xlrd.open_workbook(excel_n
-
解决python3安装pandas出错的问题
安装pandas出错: Running setup.py (path:/data/envs/py3/build/pandas/setup.py) egg_info for package pandas Traceback (most recent call last): File "<string>", line 17, in <module> File "/data/envs/py3/build/pandas/setup.py", line
-
python pandas模糊匹配 读取Excel后 获取指定指标的操作
1.首先读取Excel文件 数据代表了各个城市店铺的装修和配置费用,要统计出装修和配置项的总费用并进行加和计算: 2.pandas实现过程 import pandas as pd #1.读取数据 df = pd.read_excel(r'./data/pfee.xlsx') print(df) cols = list(df.columns) print(cols) #2.获取含有装修 和 配置 字段的数据 zx_lists=[] pz_lists=[] for name in cols: if
-
Python Pandas知识点之缺失值处理详解
前言 数据处理过程中,经常会遇到数据有缺失值的情况,本文介绍如何用Pandas处理数据中的缺失值. 一.什么是缺失值 对数据而言,缺失值分为两种,一种是Pandas中的空值,另一种是自定义的缺失值. 1. Pandas中的空值有三个:np.nan (Not a Number) . None 和 pd.NaT(时间格式的空值,注意大小写不能错),这三个值可以用Pandas中的函数isnull(),notnull(),isna()进行判断. isnull()和notnull()的结果互为取反,isn
-
Python机器学习三大件之二pandas
一.Pandas 2008年WesMcKinney开发出的库 专门用于数据挖掘的开源python库 以Numpy为基础,借力Numpy模块在计算方面性能高的优势 基于matplotlib,能够简便的画图 独特的数据结构 二.数据结构 Pandas中一共有三种数据结构,分别为:Series.DataFrame和MultiIndex. 三.Series Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数.字符串.浮点数等,主要由一组数据和与之相关的索引两部分构成. Ser