联邦学习论文解读分散数据的深层网络通信
目录
- 前言
- Abstract
- Introduction
- Federated Learning
- Privacy
- Federated Optimization
- The FederatedAveraging Algorithm
- Experimental Results
- Increasing parallelism
- Increasing computation per client
- Can we over-optimize on the client datasets?
- Conclusions and Future Work
前言
联邦学习(Federated Learning) 是人工智能的一个新的分支,这项技术是谷歌于2016年首次提出,本篇论文第一次描述了这一概念。
Abstract
现代移动设备可以访问到大量数据,这些数据训练后反过来可以大大提高用户体验。例如,语言模型可以改善语音识别和文本输入,图像模型可以自动选择好的照片。但是,这些丰富的数据通常对隐私敏感、数量众多或两者兼而有之,这可能会妨碍使用常规方法进行训练。于是我们提出将训练数据分发在移动设备上的替代训练方案,并通过聚合本地计算的更新来学习共享模型,我们称这种分散的学习方法为联邦学习。
简而言之,当下移动设备产生了大量的数据,我们需要利用这些数据来训练一些模型,这些模型将会提升用户实验。传统的训练方式:收集所有客户端的数据,然后利用这些数据训练一个模型,最后分发给所有客户端。存在的问题:我们没法直接收集所有设备的数据来统一训练(隐私要求),于是提出了一种新的不需要共享客户端数据的模型训练方式。
Introduction
联邦学习中,学习任务由中央服务器协调,每个客户端都有一个本地训练数据集,该数据集永远不会上传到服务器(即隐私不会被泄露)。
本文主要贡献:
- 将移动设备分散数据的训练问题确定为重要的研究方向
- 提出了解决该问题的具体算法
- 对所提出的算法进行了验证
更具体地说,我们引入了联邦平均算法(FederatedAveraging algorithm)。
Federated Learning
联邦学习的问题具有以下属性:
- 对来自移动设备的数据进行训练,与对数据中心通常可用的代理数据进行训练相比,具有明显的优势。
- 该数据是隐私敏感的或者大规模的(与模型的大小相比),因此最好不要纯粹出于模型训练的目的将其记录到数据中心(隐私的)
- 对于监督任务,可以从用户交互中自然推断出数据上的标签。
作为两个例子,我们考虑图像分类和语言模型。图像分类:例如预测哪些照片将来最有可能被多次查看或共享;语言模型:下一个单词的预测甚至预测整个回复来改善触摸屏键盘上的语音识别和文本输入。这两项任务的潜在训练数据(用户拍摄的所有照片以及他们在移动键盘上键入的所有照片,包括密码,URL,消息等)都可能对隐私敏感。
Privacy
与数据中心对持久数据的训练相比,联邦学习具有明显的隐私优势。但是即使是“匿名”数据集,也可能通过与其他数据结合而使用户隐私面临风险。
Federated Optimization
我们将联邦学习中的优化问题称为联邦优化(Federated Optimization)。联邦优化具有几个关键属性,可将其与典型的分布式优化问题区分开:
- Non-IID:给定客户端上的训练数据通常基于特定用户对移动设备的使用,因此任何特定用户的本地数据集将不代表总体分布。
- Unbalanced:一些用户将比其他用户更重地使用服务或应用程序,导致不同数量的本地培训数据。简而言之,每个用户产生的数据量不一样。
- Massively distributed:预计参与优化的客户端数量将远远大于每个客户端的平均示例数量。
- 移动设备经常脱机或连接缓慢或昂贵
本文重点是非IID和不平衡属性的优化,以及通信约束的关键性质。
我们假设一个同步更新方案在几轮通讯中进行。有一组固定的K个客户端,每个客户端都有一个固定的本地数据集。在每轮开始时,随机选择一部分客户端,服务器将当前全局算法状态发送给这些客户端中的每一个(例如,当前模型参数)。然后,每个选定的客户端根据全局状态及其本地数据集执行本地计算,并向服务器发送更新。然后,服务器将这些更新应用于其全局状态,并重复该过程。
问题的一般形式:


在数据中心优化中,通信成本相对较小,计算成本占主导地位,最近的重点是使用GPU来降低这些成本。相比之下,在联邦优化通信成本中占主导地位。
因此,我们的目标是使用额外的计算来减少训练模型所需的通信轮数。我们可以添加计算的两种主要方法:
增加并行性。使用更多客户端在每个通信周期之间独立工作。
增加对每个客户端的计算。即每个客户端在每个通信回合之间执行更复杂的计算。
以上内容下文都将有更加详细的介绍!
The FederatedAveraging Algorithm
深度学习的众多成功应用几乎完全依赖于随机梯度下降(SGD)的变体进行优化。
在联邦学习中,我们使用大批量同步SGD,已有相关论文证明,它是优于异步方法的。
为了在联邦学习中应用这种方法,我们在每轮中选择一部分客户端,并计算这些客户端持有的所有数据的损失梯度。参数C控制全局块大小,其中C=1对应于全批(非随机)梯度下降。我们将此算法称为FederatedSGD(orFedSGD)。

FedSGD的一种典型的实现方式:C=1(非SGD),学习率 η \eta η固定,每一个客户端算出自己所有数据损失的梯度(平均梯度),然后传递给中央服务器,中央服务器整合所有梯度,来更新全局的参数 w t w_t wt。
计算量由三个参数控制:
- C:每一轮执行计算的客户端比例(只有一部分客户端参与更新)
- E:每一轮更新时,每个客户端对其本地参数进行更新的次数
- B:客户端每一次更新参数时所用本地数据量的大小
该算法更加详细的描述如下:

参数介绍:K表示客户端的个数, B表示每一次本地更新时的数据量,E表示本地更新的次数, η表示学习率。
首先是服务器执行以下步骤:

Experimental Results
Table1:

表1描述的是图像分类任务:参数C对E=1的MNIST 2NN和E=5的CNN的影响。其中C=0表示每次选择一个客户端的数据进行更新。对于MINST 2NN来说,总的客户端数量为100,即五行分别表示1,10,20,50,100个客户端。
每个表格条目给出了实现2NN的97%和CNN的99%的测试集精度所需的通信轮数,以及相对于C=0这一baseline的加速比。 比如对于第三行 B = ∞ B=\infty B=∞这一情况( B = ∞ B=\infty B=∞表示每一次都用全部数据进行本地参数更新),中央服务器需要与客户端进行1658次通信,才能使得模型在测试集上的精度达到97%。
Table2:
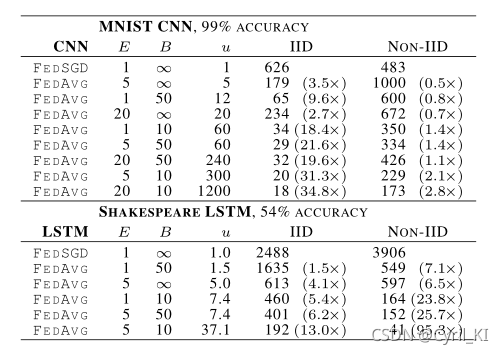
表2描述的是语言模型:LSTM语言模型,该模型在读取一行中的每个字符后预测下一个字符。该模型以一系列字符作为输入,并将每个字符嵌入到8维空间中,然后通过2个LSTM层处理嵌入的字符,每个层具有256个节点。
表2的含义同表1:在某一参数环境下,FedSGD要达到目标精度所需要进行的通讯次数。
SGD对学习率参数η的调整很敏感,本文的 η \eta η是基于网格搜索法找到的。
Increasing parallelism
增加并行性: 即增加客户端数量。
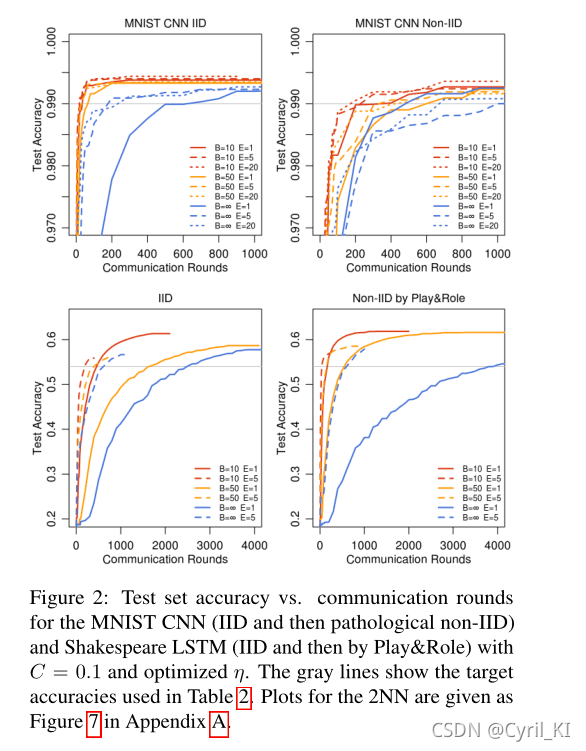
上图给出了特定参数设置下要达到阈值精度(图中灰线)所需要进行的通讯轮数。
然后,使用形成曲线的离散点之间的线性插值来计算曲线穿过目标精度的轮数。
Increasing computation per client
增加每个客户端的计算量。C=0.1固定,减小B,或者增加E,或者减小B的同时增加E。
还是上面这张图:
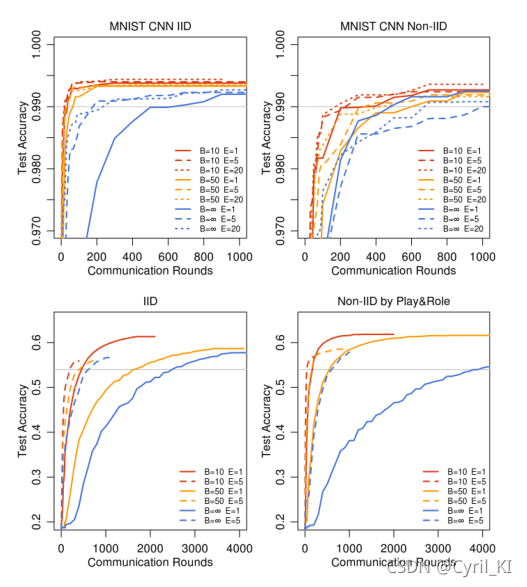
可以看到,随着B减小或者E增加,达到目标精度所需的通讯次数是减小的,也就是说:每轮添加更多本地SGD更新可以显著降低通信成本。
Can we over-optimize on the client datasets?
本地数据集上进行更新时可以过度优化吗?即E特别大,进行很多次的本地更新。
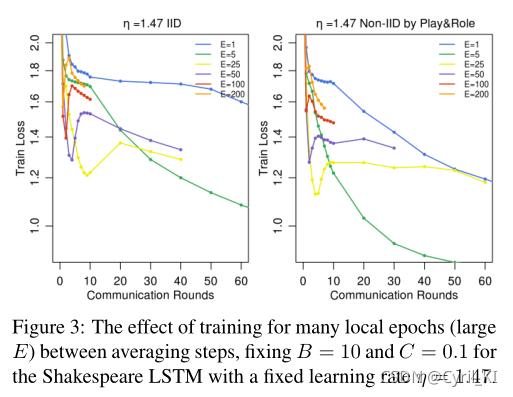
上图给出了E特别大时的实验结果:对于大的E值,收敛速度并没有显著的下降。
Conclusions and Future Work
联邦学习可以变得切实可行,因为可以使用相对较少的通信轮次来训练高质量模型。联邦学习将是未来比较热门的一个方向!
以上就是论文解读分散数据的深层网络通信有效学习的详细内容,更多关于分散数据深层网络通信的资料请关注我们其它相关文章!
相关推荐
-

微信小程序 网络通信实现详解
关于网络通信,这里我使用的是wx.request,官方代码示例如下: wx.request({ url: 'test.php', //仅为示例,并非真实的接口地址 data: { x: '', y: '' }, header: { 'content-type': 'application/json' // 默认值 }, success (res) { console.log(res.data) } }) 对于初学者而言,官方示例可能会看不怎么懂,所以我就以我自己当初项目驱动学习的方式(开发个人的
-
Docker数据管理与网络通信的使用
可以通过Dokcer核心及安装来安装Docker及简单操作. 一.Docker镜像的创建方法 Docker镜像除了是Docker的核心技术之外,也是应用发布的标准格式.一个 完整的Docker镜像可以支撑- -个Docker 容器的运行,在Docker的整个使用过程中,进入- -个已经定型的容器之后,就可以在容器中进行操作,最常见的操作就是在容器中安装应用服务,如果要把已经安装的服务进行迁移,就需要把环境及搭建的服务生成新的镜像. (1)基于已有镜像创建 基于已有镜像创建主要使用docker c
-
Java网络通信中ServerSocket的设计优化方案
前言:在java的网络通信中,两个不同节点的主机想要进行通信则可以通过建立Socket对象(相当于客户端主机,向服务端请求发送信息)和ServerSocket对象(相当于服务端主机,接收客户端的连接请求并回复信息)实现. 1:创建一个Socket对象 Socket socket = new Socket("IP",port); 指定将要连接的服务端的ip地址和端口号来创建一个Socket对象,在创建结束之后便可对其进行输出.输入操作. 2:创建一个ServerSocket对象 Serv
-
Docker 多主机网络通信详细介绍
最近做项目是关于Docker 的网络通信,需要多个主机进行链接通信,这里记录下,以后便于项目开发,大家需要的话也可以看下,少走些弯路. Docker多主机网络通信详解 Docker支持多主机网络通信功能,可以通过命令行建立多主机通信网络.本文使用Docker machine和Consul服务发现工具来讲解这一点. 前提是需要先安装Docker工具箱. 1.Docker Multi-Host Networking 作为一个示例,我们会在VirtualBox虚拟机上使用do
-
Android之网络通信案例分析
由于一个项目的需要,我研究了一下android的网络通信方式,大体和java平台的很相似! android平台也提供了很多的API供开发者使用,请按示例图: 首先,介绍一下通过http包工具进行通信,分get和post两种方式,两者的区别是: 1,post请求发送数据到服务器端,而且数据放在html header中一起发送到服务器url,数据对用户不可见,get请求是把参数值加到url的队列中,这在一定程度上,体现出post的安全性要比get高 2,get传送的数据量小,一般不能大于2kb,
-
联邦学习论文解读分散数据的深层网络通信
目录 前言 Abstract Introduction Federated Learning Privacy Federated Optimization The FederatedAveraging Algorithm Experimental Results Increasing parallelism Increasing computation per client Can we over-optimize on the client datasets? Conclusions and
-
知识蒸馏联邦学习的个性化技术综述
目录 前言 摘要 I. 引言 II. 个性化需求 III. 方法 A. 添加用户上下文 B. 迁移学习 C. 多任务学习 D. 元学习 E. 知识蒸馏 F. 基础+个性化层 G. 全局模型和本地模型混合 IV. 总结 前言 题目: Survey of Personalization Techniques for FederatedLearning 会议: 2020 Fourth World Conference on Smart Trends in Systems, Security and S
-
联邦学习神经网络FedAvg算法实现
目录 I. 前言 II. 数据介绍 1. 特征构造 III. 联邦学习 1. 整体框架 2. 服务器端 3. 客户端 4. 代码实现 4.1 初始化 4.2 服务器端 4.3 客户端 4.4 测试 IV. 实验及结果 V. 源码及数据 I. 前言 联邦学习(Federated Learning) 是人工智能的一个新的分支,这项技术是谷歌2016年于论文 Communication-Efficient Learning of Deep Networks from Decentralized Dat
-
联邦学习FedAvg中模型聚合过程的理解分析
目录 问题 聚合 1. 聚合所有客户端 2. 仅聚合被选中的客户端 3. 选择 问题 联邦学习原始论文中给出的FedAvg的算法框架为: 参数介绍: K 表示客户端的个数, B表示每一次本地更新时的数据量, E 表示本地更新的次数, η表示学习率. 首先是服务器执行以下步骤: 对每一个本地客户端来说,要做的就是更新本地参数,具体来讲: 把自己的数据集按照参数B分成若干个块,每一块大小都为B. 对每一块数据,需要进行E轮更新:算出该块数据损失的梯度,然后进行梯度下降更新,得到新的本地 w . 更新
-
PyTorch实现联邦学习的基本算法FedAvg
目录 I. 前言 II. 数据介绍 特征构造 III. 联邦学习 1. 整体框架 2. 服务器端 3. 客户端 IV. 代码实现 1. 初始化 2. 服务器端 3. 客户端 4. 测试 V. 实验及结果 VI. 源码及数据 I. 前言 在之前的一篇博客联邦学习基本算法FedAvg的代码实现中利用numpy手搭神经网络实现了FedAvg,手搭的神经网络效果已经很好了,不过这还是属于自己造轮子,建议优先使用PyTorch来实现. II. 数据介绍 联邦学习中存在多个客户端,每个客户端都有自己的数据集
-
PyTorch实现FedProx联邦学习算法
目录 I. 前言 III. FedProx 1. 模型定义 2. 服务器端 3. 客户端更新 IV. 完整代码 I. 前言 FedProx的原理请见:FedAvg联邦学习FedProx异质网络优化实验总结 联邦学习中存在多个客户端,每个客户端都有自己的数据集,这个数据集他们是不愿意共享的. 数据集为某城市十个地区的风电功率,我们假设这10个地区的电力部门不愿意共享自己的数据,但是他们又想得到一个由所有数据统一训练得到的全局模型. III. FedProx 算法伪代码: 1. 模型定义 客户端的模
-
FedAvg联邦学习FedProx异质网络优化实验总结
目录 前言 I. FedAvg II. FedProx III. 实验 IV. 总结 前言 题目: Federated Optimization for Heterogeneous Networks 会议: Conference on Machine Learning and Systems 2020 论文地址:Federated Optimization for Heterogeneous Networks FedAvg对设备异质性和数据异质性没有太好的解决办法,FedProx在FedAvg的
-
Node.js学习之TCP/IP数据通讯(实例讲解)
1.使用net模块实现基于TCP的数据通讯 提供了一个net模块,专用于实现TCP服务器与TCP客户端之间的通信 1.1创建TCP服务器 在Node.js利用net模块创建TCP服务器 var server = net.createServer([options],[connectionListener]) //options:false当TCP服务器接收到客户端发送的一个FIN包时将会回发一个FIN包 true当TCP服务器接收到客户端发送的一个FIN包时将不会回发FIN包,这使得TCP服务器
-
微信小程序学习笔记之本地数据缓存功能详解
本文实例讲述了微信小程序学习笔记之本地数据缓存功能.分享给大家供大家参考,具体如下: 前面介绍了微信小程序获取位置信息操作.这里再来介绍一下微信小程序的本地数据缓存功能. [将数据存储在本地缓存]wx.setStorage [读取本地缓存]wx.getStorage 以手机号+密码登录为例,把登录成功返回的token值存储在本地缓存中,然后读取缓存中的token: login.php: <?php header("Content-type:text/html;charset=utf-8&q
-
深度学习入门之Pytorch 数据增强的实现
数据增强 卷积神经网络非常容易出现过拟合的问题,而数据增强的方法是对抗过拟合问题的一个重要方法. 2012 年 AlexNet 在 ImageNet 上大获全胜,图片增强方法功不可没,因为有了图片增强,使得训练的数据集比实际数据集多了很多'新'样本,减少了过拟合的问题,下面我们来具体解释一下. 常用的数据增强方法 常用的数据增强方法如下: 1.对图片进行一定比例缩放 2.对图片进行随机位置的截取 3.对图片进行随机的水平和竖直翻转 4.对图片进行随机角度的旋转 5.对图片进行亮度.对比度和颜色的