浅谈如何保证Mysql主从一致
目录
- binlog的三种格式对比
- 为什么会有mixed格式的binlog?
- 循环复制问题
- 小结
为什么备库执行了 binlog 就可以跟主库保持一致了呢?今天正式地和你介绍一下它。
在最开始,MySQL 是以容易学习和方便的高可用架构,被开发人员青睐的。而它的几乎所有的高可用架构,都直接依赖于 binlog。虽然这些高可用架构已经呈现出越来越复杂的趋势,但都是从最基本的一主一备演化过来的。
MySQL 主备的基本原理
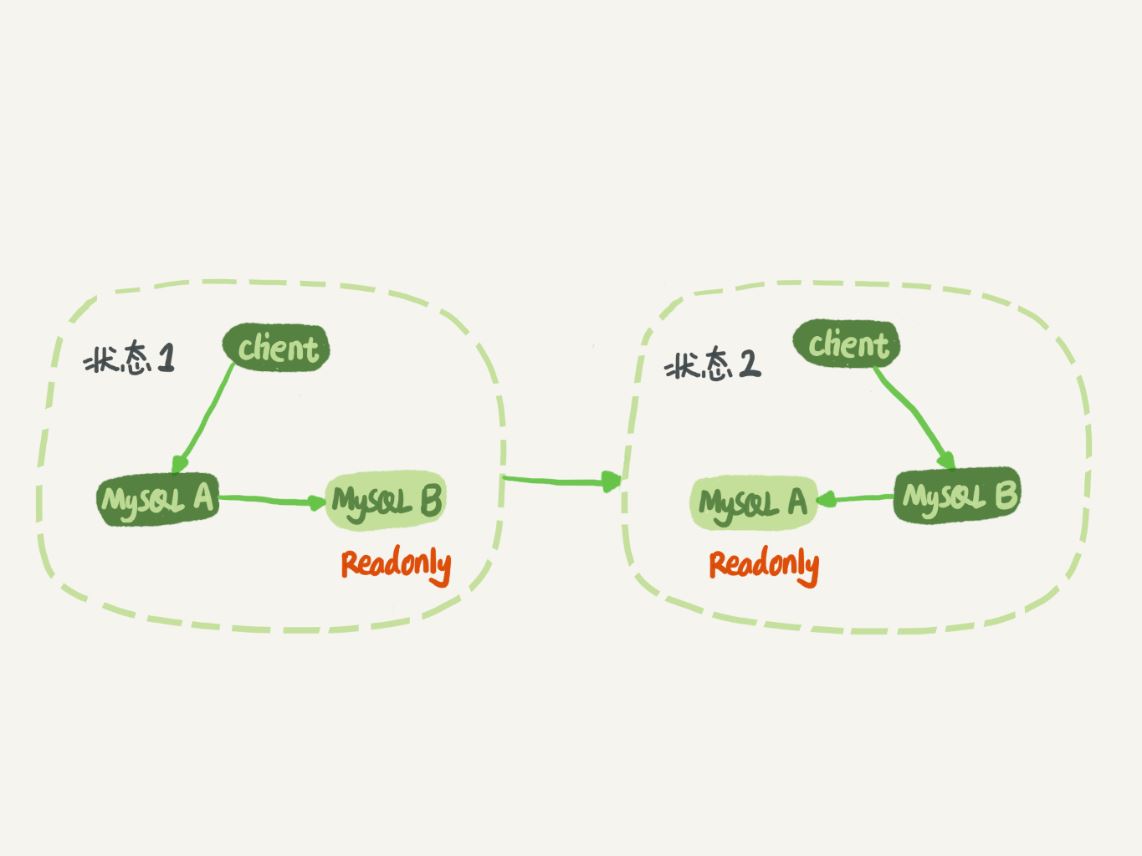
图 1 MySQL 主备切换流程
在状态 1 中,客户端的读写都直接访问节点 A,而节点 B 是 A 的备库,只是将 A 的更新都同步过来,到本地执行。这样可以保持节点 B 和 A 的数据是相同的。
当需要切换的时候,就切成状态 2。这时候客户端读写访问的都是节点 B,而节点 A 是 B 的备库。
在状态 1 中,虽然节点 B 没有被直接访问,但是我依然建议你把节点 B(也就是备库)设置成只读(readonly)模式。这样做,有以下几个考虑:
- 有时候一些运营类的查询语句会被放到备库上去查,设置为只读可以防止误操作;
- 防止切换逻辑有 bug,比如切换过程中出现双写,造成主备不一致;
- 可以用 readonly 状态,来判断节点的角色。
你可能会问,我把备库设置成只读了,还怎么跟主库保持同步更新呢?
这个问题,你不用担心。因为 readonly 设置对超级 (super) 权限用户是无效的,而用于同步更新的线程,就拥有超级权限。
接下来,我们再看看节点 A 到 B 这条线的内部流程是什么样的。图 2 中画出的就是一个 update 语句在节点 A 执行,然后同步到节点 B 的完整流程图。
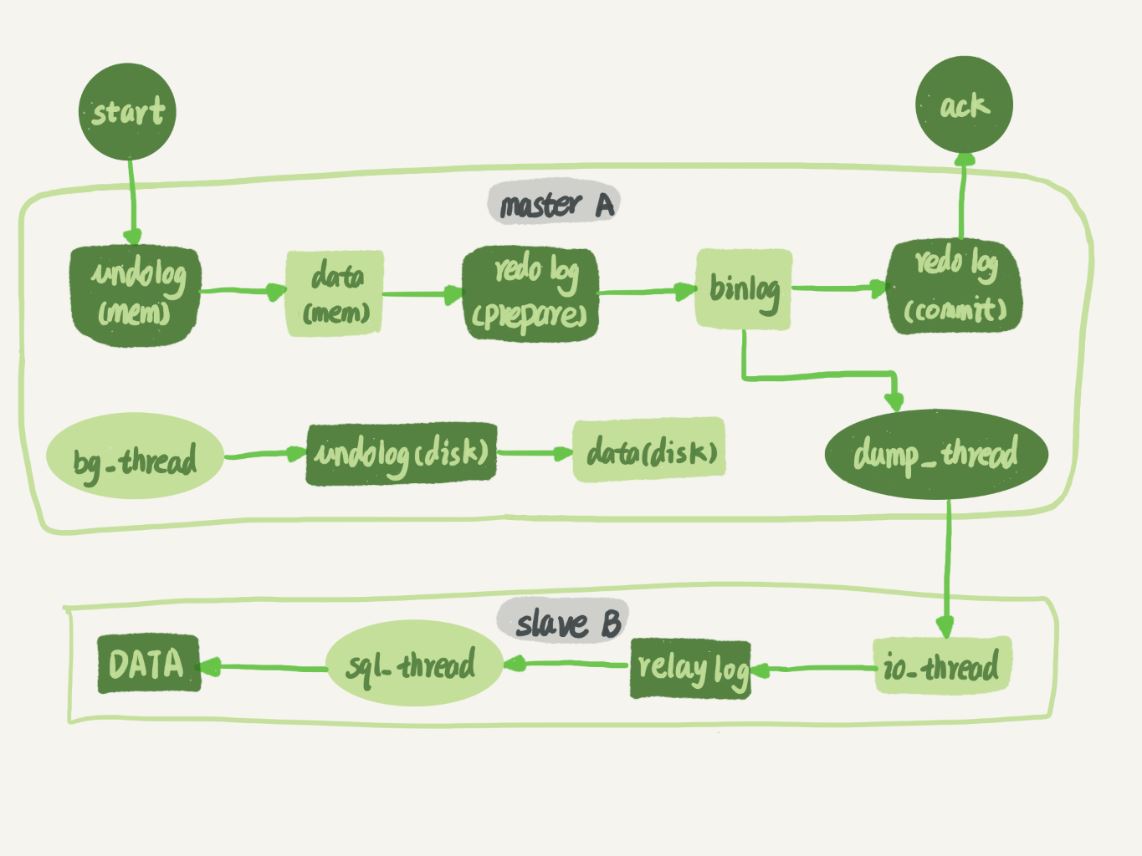
图 2 主备流程图
图 2 中,包含了在上一篇文章中讲到的 binlog 和 redo log 的写入机制相关的内容,可以看到:主库接收到客户端的更新请求后,执行内部事务的更新逻辑,同时写 binlog。
备库 B 跟主库 A 之间维持了一个长连接。主库 A 内部有一个线程,专门用于服务备库 B 的这个长连接。一个事务日志同步的完整过程是这样的:
- 在备库 B 上通过 change master 命令,设置主库 A 的 IP、端口、用户名、密码,以及要从哪个位置开始请求 binlog,这个位置包含文件名和日志偏移量。
- 在备库 B 上执行 start slave 命令,这时候备库会启动两个线程,就是图中的 io_thread 和 sql_thread。其中 io_thread 负责与主库建立连接。
- 主库 A 校验完用户名、密码后,开始按照备库 B 传过来的位置,从本地读取 binlog,发给 B。
- 备库 B 拿到 binlog 后,写到本地文件,称为中转日志(relay log)。
- sql_thread 读取中转日志,解析出日志里的命令,并执行。
binlog 的三种格式对比
binlog 有两种格式,一种是 statement,一种是 row。可能你在其他资料上还会看到有第三种格式,叫作 mixed,其实它就是前两种格式的混合。
为了便于描述 binlog 的这三种格式间的区别,创建了一个表,并初始化几行数据。
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `a` int(11) DEFAULT NULL, `t_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `a` (`a`), KEY `t_modified`(`t_modified`) ) ENGINE=InnoDB; insert into t values(1,1,'2018-11-13'); insert into t values(2,2,'2018-11-12'); insert into t values(3,3,'2018-11-11'); insert into t values(4,4,'2018-11-10'); insert into t values(5,5,'2018-11-09');
如果要在表中删除一行数据的话,我们来看看这个 delete 语句的 binlog 是怎么记录的。
下面这个语句包含注释,如果你用 MySQL 客户端来做这个实验的话,要记得加 -c 参数,否则客户端会自动去掉注释。
mysql> delete from t /*comment*/ where a>=4 and t_modified<='2018-11-10' limit 1;
当 binlog_format=statement 时,binlog 里面记录的就是 SQL 语句的原文。你可以用
mysql> show binlog events in 'master.000001';
命令看 binlog 中的内容。

图 3 statement 格式 binlog 示例
- 第一行 SET @@SESSION.GTID_NEXT='ANONYMOUS’你可以先忽略,后面文章会在介绍主备切换的时候再提到;
- 第二行是一个 BEGIN,跟第四行的 commit 对应,表示中间是一个事务;
- 第三行就是真实执行的语句了。可以看到,在真实执行的 delete 命令之前,还有一个“use ‘test’”命令。这条命令不是我们主动执行的,而是 MySQL 根据当前要操作的表所在的数据库,自行添加的。这样做可以保证日志传到备库去执行的时候,不论当前的工作线程在哪个库里,都能够正确地更新到 test 库的表 t。
- use 'test’命令之后的 delete 语句,就是我们输入的 SQL 原文了。可以看到,binlog“忠实”地记录了 SQL 命令,甚至连注释也一并记录了。
- 最后一行是一个 COMMIT。你可以看到里面写着 xid=61。你还记得这个 XID 是做什么用的吗?
为了说明 statement 和 row 格式的区别,我们来看一下这条 delete 命令的执行效果图:

图 4 delete 执行 warnings
运行这条 delete 命令产生了一个 warning,原因是当前 binlog 设置的是 statement 格式,并且语句中有 limit,所以这个命令可能是 unsafe 的。
这是因为 delete 带 limit,很可能会出现主备数据不一致的情况。比如上面这个例子:
- 如果 delete 语句使用的是索引 a,那么会根据索引 a 找到第一个满足条件的行,也就是说删除的是 a=4 这一行;
- 但如果使用的是索引 t_modified,那么删除的就是 t_modified='2018-11-09’也就是 a=5 这一行。
由于 statement 格式下,记录到 binlog 里的是语句原文,因此可能会出现这样一种情况:在主库执行这条 SQL 语句的时候,用的是索引 a;而在备库执行这条 SQL 语句的时候,却使用了索引 t_modified。因此,MySQL 认为这样写是有风险的。
那么,如果我把 binlog 的格式改为 binlog_format=‘row’, 是不是就没有这个问题了呢?
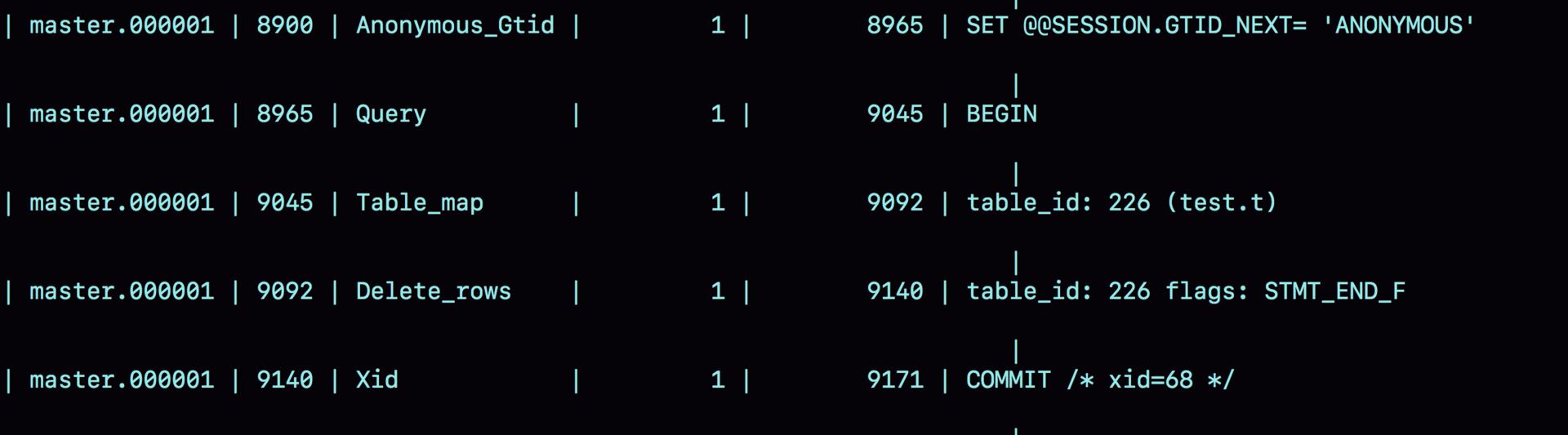
图 5 row 格式 binlog 示例
与 statement 格式的 binlog 相比,前后的 BEGIN 和 COMMIT 是一样的。但是,row 格式的 binlog 里没有了 SQL 语句的原文,而是替换成了两个 event:Table_map 和 Delete_rows。
- Table_map event,用于说明接下来要操作的表是 test 库的表 t;
- Delete_rows event,用于定义删除的行为
其实,我们通过图 5 是看不到详细信息的,还需要借助 mysqlbinlog 工具,用下面这个命令解析和查看 binlog 中的内容。因为图 5 中的信息显示,这个事务的 binlog 是从 8900 这个位置开始的,所以可以用 start-position 参数来指定从这个位置的日志开始解析。
mysqlbinlog -vv data/master.000001 --start-position=8900;

图 6 row 格式 binlog 示例的详细信息
从这个图中,我们可以看到以下几个信息:
- server id 1,表示这个事务是在 server_id=1 的这个库上执行的。
- 每个 event 都有 CRC32 的值,这是因为我把参数 binlog_checksum 设置成了 CRC32。
- Table_map event 跟在图 5 中看到的相同,显示了接下来要打开的表,map 到数字 226。现在我们这条 SQL 语句只操作了一张表,如果要操作多张表呢?每个表都有一个对应的 Table_map event、都会 map 到一个单独的数字,用于区分对不同表的操作。
- 我们在 mysqlbinlog 的命令中,使用了 -vv 参数是为了把内容都解析出来,所以从结果里面可以看到各个字段的值(比如,@1=4、 @2=4 这些值)。
- binlog_row_image 的默认配置是 FULL,因此 Delete_event 里面,包含了删掉的行的所有字段的值。如果把 binlog_row_image 设置为 MINIMAL,则只会记录必要的信息,在这个例子里,就是只会记录 id=4 这个信息。
- 最后的 Xid event,用于表示事务被正确地提交了。
当 binlog_format 使用 row 格式的时候,binlog 里面记录了真实删除行的主键 id,这样 binlog 传到备库去的时候,就肯定会删除 id=4 的行,不会有主备删除不同行的问题。
为什么会有 mixed 格式的 binlog?
基于上面的信息,我们来讨论一个问题:为什么会有 mixed 这种 binlog 格式的存在场景?推论过程是这样的:
- 因为有些 statement 格式的 binlog 可能会导致主备不一致,所以要使用 row 格式。
- 但 row 格式的缺点是,很占空间。比如你用一个 delete 语句删掉 10 万行数据,用 statement 的话就是一个 SQL 语句被记录到 binlog 中,占用几十个字节的空间。但如果用 row 格式的 binlog,就要把这 10 万条记录都写到 binlog 中。这样做,不仅会占用更大的空间,同时写 binlog 也要耗费 IO 资源,影响执行速度。
- 所以,MySQL 就取了个折中方案,也就是有了 mixed 格式的 binlog。mixed 格式的意思是,MySQL 自己会判断这条 SQL 语句是否可能引起主备不一致,如果有可能,就用 row 格式,否则就用 statement 格式。
也就是说,mixed 格式可以利用 statment 格式的优点,同时又避免了数据不一致的风险。
因此,如果你的线上 MySQL 设置的 binlog 格式是 statement 的话,那基本上就可以认为这是一个不合理的设置。你至少应该把 binlog 的格式设置为 mixed。
现在越来越多的场景要求把 MySQL 的 binlog 格式设置成 row。这么做的理由有很多,我来给你举一个可以直接看出来的好处:恢复数据。
接下来,我们就分别从 delete、insert 和 update 这三种 SQL 语句的角度,来看看数据恢复的问题。
通过图 6 你可以看出来,即使我执行的是 delete 语句,row 格式的 binlog 也会把被删掉的行的整行信息保存起来。所以,如果你在执行完一条 delete 语句以后,发现删错数据了,可以直接把 binlog 中记录的 delete 语句转成 insert,把被错删的数据插入回去就可以恢复了。
如果你是执行错了 insert 语句呢?那就更直接了。row 格式下,insert 语句的 binlog 里会记录所有的字段信息,这些信息可以用来精确定位刚刚被插入的那一行。这时,你直接把 insert 语句转成 delete 语句,删除掉这被误插入的一行数据就可以了。
如果执行的是 update 语句的话,binlog 里面会记录修改前整行的数据和修改后的整行数据。所以,如果你误执行了 update 语句的话,只需要把这个 event 前后的两行信息对调一下,再去数据库里面执行,就能恢复这个更新操作了。
其实,由 delete、insert 或者 update 语句导致的数据操作错误,需要恢复到操作之前状态的情况,也时有发生。MariaDB 的Flashback工具就是基于上面介绍的原理来回滚数据的。
虽然 mixed 格式的 binlog 现在已经用得不多了,但这里我还是要再借用一下 mixed 格式来说明一个问题,来看一下这条 SQL 语句:
mysql> insert into t values(10,10, now());
如果我们把 binlog 格式设置为 mixed,你觉得 MySQL 会把它记录为 row 格式还是 statement 格式呢?
先不要着急说结果,我们一起来看一下这条语句执行的效果。

图 7 mixed 格式和 now()
可以看到,MySQL 用的居然是 statement 格式。你一定会奇怪,如果这个 binlog 过了 1 分钟才传给备库的话,那主备的数据不就不一致了吗?
接下来,我们再用 mysqlbinlog 工具来看看:

图 8 TIMESTAMP 命令
从图中的结果可以看到,原来 binlog 在记录 event 的时候,多记了一条命令:SET TIMESTAMP=1546103491。它用 SET TIMESTAMP 命令约定了接下来的 now() 函数的返回时间。
因此,不论这个 binlog 是 1 分钟之后被备库执行,还是 3 天后用来恢复这个库的备份,这个 insert 语句插入的行,值都是固定的。也就是说,通过这条 SET TIMESTAMP 命令,MySQL 就确保了主备数据的一致性。我之前看过有人在重放 binlog 数据的
之前看过有人在重放 binlog 数据的时候,是这么做的:用 mysqlbinlog 解析出日志,然后把里面的 statement 语句直接拷贝出来执行。你现在知道了,这个方法是有风险的。因为有些语句的执行结果是依赖于上下文命令的,直接执行的结果很可能是错误的。
所以,用 binlog 来恢复数据的标准做法是,用 mysqlbinlog 工具解析出来,然后把解析结果整个发给 MySQL 执行。类似下面的命令
mysqlbinlog master.000001 --start-position=2738 --stop-position=2973 | mysql -h127.0.0.1 -P13000 -u$user -p$pwd;
循环复制问题
我们可以认为正常情况下主备的数据是一致的。也就是说,图 1 中 A、B 两个节点的内容是一致的。其实,图 1 中的是 M-S 结构,但实际生产上使用比较多的是双 M 结构,也就是图 9 所示的主备切换流程。

图 9 MySQL 主备切换流程 -- 双 M 结构
对比图 9 和图 1,你可以发现,双 M 结构和 M-S 结构,其实区别只是多了一条线,即:节点 A 和 B 之间总是互为主备关系。这样在切换的时候就不用再修改主备关系。
但是,双 M 结构还有一个问题需要解决。
业务逻辑在节点 A 上更新了一条语句,然后再把生成的 binlog 发给节点 B,节点 B 执行完这条更新语句后也会生成 binlog。(我建议你把参数 log_slave_updates 设置为 on,表示备库执行 relay log 后生成 binlog)
那么,如果节点 A 同时是节点 B 的备库,相当于又把节点 B 新生成的 binlog 拿过来执行了一次,然后节点 A 和 B 间,会不断地循环执行这个更新语句,也就是循环复制了。这个要怎么解决呢?
从上面的图 6 中可以看到,MySQL 在 binlog 中记录了这个命令第一次执行时所在实例的 server id。因此,我们可以用下面的逻辑,来解决两个节点间的循环复制的问题:
- 规定两个库的 server id 必须不同,如果相同,则它们之间不能设定为主备关系;
- 一个备库接到 binlog 并在重放的过程中,生成与原 binlog 的 server id 相同的新的 binlog;
- 每个库在收到从自己的主库发过来的日志后,先判断 server id,如果跟自己的相同,表示这个日志是自己生成的,就直接丢弃这个日志。
按照这个逻辑,如果我们设置了双 M 结构,日志的执行流就会变成这样:
- 从节点 A 更新的事务,binlog 里面记的都是 A 的 server id;
- 传到节点 B 执行一次以后,节点 B 生成的 binlog 的 server id 也是 A 的 server id;
- 再传回给节点 A,A 判断到这个 server id 与自己的相同,就不会再处理这个日志。所以,死循环在这里就断掉了。
小结
binlog 在 MySQL 的各种高可用方案上扮演了重要角色。今天介绍的可以说是所有 MySQL 高可用方案的基础。在这之上演化出了诸如多节点、半同步、MySQL group replication 等相对复杂的方案。
思考题: 说到循环复制问题的时候,我们说 MySQL 通过判断 server id 的方式,断掉死循环。但是,这个机制其实并不完备,在某些场景下,还是有可能出现死循环?又应该怎么解决呢?
答案:一种场景是,在一个主库更新事务后,用命令 set global server_id=x 修改了 server_id。等日志再传回来的时候,发现 server_id 跟自己的 server_id 不同,就只能执行了。
另一种场景是,有三个节点的时候,如图 7 所示,trx1 是在节点 B 执行的,因此 binlog 上的 server_id 就是 B,binlog 传给节点 A,然后 A 和 A’搭建了双 M 结构,就会出现循环复制。
到此这篇关于浅谈如何保证Mysql主从一致的文章就介绍到这了,更多相关Mysql 主从一致内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MYSQL主从不同步延迟原理分析及解决方案
1. MySQL数据库主从同步延迟原理.要说延时原理,得从mysql的数据库主从复制原理说起,mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高,slave的Slave_IO_Running线程到主库取日志,效率很比较高,下一步,问题来了,slave的Slave_SQL_Running线程将主库的DDL和DML操作在slave实施.DML和DDL的IO操作是随即的,不是顺序的,成本高很多,还可能可slave上的其他查询产生lock争
-
mysql主从同步复制错误解决一例
蚊子今天下午搭了一主三从的mysql复制,结果所有服务器都配置好后,发现从上报如下的错误 复制代码 代码如下: Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids; these ids must be different for replication to work (or the --replicate-same-server-i
-
mysql主从数据库不同步的2种解决方法
今天发现Mysql的主从数据库没有同步 先上Master库: mysql>show processlist; 查看下进程是否Sleep太多.发现很正常. show master status; 也正常. mysql> show master status; +-------------------+----------+--------------+-------------------------------+ | File | Position | Binlog_Do_DB | Binlo
-
MYSQL主从数据库同步备份配置的方法
下文分步骤给大家介绍的非常详细,具体详情请看下文吧. 一.准备 用两台服务器做测试: Master Server: 192.0.0.1/Linux/MYSQL 4.1.12 Slave Server: 192.0.0.2/Linux/MYSQL 4.1.18 做主从服务器的原则是,MYSQL版本要相同,如果不能满足,最起码从服务器的MYSQL的版本必须高于主服务器的MYSQL版本 二.配置master服务器 1. 登录Master服务器,编辑my.cnf #vim /etc/my.cnf 在[m
-
Mysql主从同步备份策略分享
环境:主从服务器上的MySQL数据库版本同为5.1.34主机IP:192.168.0.1从机IP:192.168.0.2一. MySQL主服务器配置1.编辑配置文件/etc/my.cnf# 确保有如下行server-id = 1log-bin=mysql-binbinlog-do-db=mysql #需要备份的数据库名,如果备份多个数据库,重复设置这个选项即可binlog-ignore-db=mysql #不需要备份的数据库名,如果备份多个数据库,重复设置这个选项即可log-slave-up
-
MySQL主从复制配置心跳功能介绍
在 MySQL 主从复制时,有时候会碰到这样的故障:在 Slave 上 Slave_IO_Running 和 Slave_SQL_Running 都是 Yes,Slave_SQL_Running_State 显示 Slave has read all relay log; waiting for the slave I/O thread to update it ,看起来状态都正常,但实际却滞后于主,Master_Log_File 和 Read_Master_Log_Pos 也不是实际主上最新的
-
MySQL主从同步、读写分离配置步骤
现在使用的两台服务器已经安装了MySQL,全是rpm包装的,能正常使用. 为了避免不必要的麻烦,主从服务器MySQL版本尽量保持一致; 环境:192.168.0.1 (Master) 192.168.0.2 (Slave) MySQL Version:Ver 14.14 Distrib 5.1.48, for pc-linux-gnu (i686) using readline 5.1 1.登录Master服务器,修改my.cnf,添加如下内容: server-id = 1 //数据库ID号,
-
详解Mysql主从同步配置实战
1.Introduction 之前写过一篇文章:Mysql主从同步的原理. 相信看过这篇文章的童鞋,都摩拳擦掌,跃跃一试了吧? 今天我们就来一次mysql主从同步实战! 2.环境说明 os:ubuntu16.04 mysql:5.7.17 下面的实战演练,都是基于上面的环境.当然,其他环境也大同小异. 3.进入实战 工具 2台机器: master IP:192.168.33.22 slave IP:192.168.33.33 master机器上的操作 1.更改配置文件 我们找到文件 /etc/
-

浅谈如何保证Mysql主从一致
目录 binlog的三种格式对比 为什么会有mixed格式的binlog? 循环复制问题 小结 为什么备库执行了 binlog 就可以跟主库保持一致了呢?今天正式地和你介绍一下它. 在最开始,MySQL 是以容易学习和方便的高可用架构,被开发人员青睐的.而它的几乎所有的高可用架构,都直接依赖于 binlog.虽然这些高可用架构已经呈现出越来越复杂的趋势,但都是从最基本的一主一备演化过来的. MySQL 主备的基本原理 图 1 MySQL 主备切换流程 在状态 1 中,客户端的读写都直接访问节点
-
浅谈Redis跟MySQL的双写问题解决方案
目录 写在前面 三种读写缓存策略 Cache-AsidePattern(旁路缓存模式) Read-Through/Write-Through(读写穿透) WriteBehindPattern(异步缓存写入) 旁路缓存模式解析 CacheAsidePattern的一些疑问 CacheAsidePattern的缺陷 项目中有遇到这个问题,跟MySQL中的数据不一致,研究一番发现这里面细节并不简单,特此记录一下. 写在前面 严格意义上任何非原子操作都不可能保证一致性,除非用阻塞读写实现强一致性,所以缓
-
浅谈PHP值mysql操作类
浅谈PHP值mysql操作类 <?php /** * Created by PhpStorm. * User: Administrator * Date: 2016/6/27 * Time: 18:55 */ Class Mysqls{ private $table; //表 private $opt; public function __construct($host,$user,$pwd,$name,$table_names) { $this->db=new mysqli($host,$u
-
浅谈php中mysql与mysqli的区别分析
首先两个函数都是用来处理DB 的.首先, mysqli 连接是永久连接,而mysql是非永久连接.什么意思呢? mysql连接每当第二次使用的时候,都会重新打开一个新的进程,而mysqli则只使用同一个进程,这样可以很大程度的减轻服务器端压力.其次,mysqli封装了诸如事务等一些高级操作,同时封装了DB操作过程中的很多可用的方法.应用比较多的地方是 mysqli的事务.比如下面的示例: 复制代码 代码如下: $mysqli = new mysqli('localhost','root','',
-
浅谈Python访问MySQL的正确姿势
Py2 时代,访问 MySQL 数据库的模块除了 PyMySQL 和 MySQL-python 之外,还有以速度见长的 Umysql,以及非常小众的 Oursql 模块.进入了 Py3 时代之后,PyMySQL 与时俱进,顺利升级到 Py3 版本, MySQL-python 则被它的一个 Py3 分支--mysqlclient 取代,而 Umysql 和 Oursql 则停留在了属于它们的那个时代. 下表给出了 PyMySQL 模块和 mysqlclient 模块在安装方式.导入方式.支持的Py
-
浅谈MySQL中的自增主键用完了怎么办
在面试中,大家应该经历过如下场景 面试官:"用过mysql吧,你们是用自增主键还是UUID?" 你:"用的是自增主键" 面试官:"为什么是自增主键?" 你:"因为采用自增主键,数据在物理结构上是顺序存储,性能最好,blabla-" 面试官:"那自增主键达到最大值了,用完了怎么办?" 你:"what,没复习啊!!" (然后,你就可以回去等通知了!) 这个问题是一个粉丝给我提的,我觉得
-
浅谈MySQL如何优雅的做大表删除
随着时间的推移或者业务量的增长,数据库空间使用率也不断的呈稳定上升状态,当数据库空间将要达到瓶颈的时候,可能我们才会发现数据库有那么一两张的超级大表!他们堆积了从业务开始到现在的全部数据,但是90%的数据都是没有业务价值的,这时候该如何处理这些大表? 既然是没有价值的数据,我们通常一般会选择直接删除或者归档后删除两种,对于数据删除的操作方式来说又可分为两大类: 通过truncate直接删除表中全部数据 通过delete删除表中满足条件记录 一.Truncate操作 从逻辑意义上来讲,trunca
-
浅谈mysql的索引设计原则以及常见索引的区别
索引定义:是一个单独的,存储在磁盘上的数据库结构,其包含着对数据表里所有记录的引用指针. 数据库索引的设计原则: 为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引. 那么索引设计原则又是怎样的? 1.选择唯一性索引 唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录. 例如,学生表中学号是具有唯一性的字段.为该字段建立唯一性索引可以很快的确定某个学生的信息. 如果使用姓名的话,可能存在同名现象,从而降低查询速度. 2.为经常需要排序.分组和联合操
-
浅谈mysqldump使用方法(MySQL数据库的备份与恢复)
#mysqldump --help 1.mysqldump的几种常用方法: (1)导出整个数据库(包括数据库中的数据) mysqldump -u username -p dbname > dbname.sql (2)导出数据库结构(不含数据) mysqldump -u username -p -d dbname > dbname.sql (3)导出数据库中的某张数据表(包含数据) mysqldump -u username -p dbname tablename > tabl
-
浅谈mysql导出表数据到excel关于datetime的格式问题
最近用mysql导出表数据到excel文件,mysql中的datetime类型导出到excel(excel2016)中被excel识别成它自己默认的日期格式了,在mysql中的格式形如 yyyy-mm-dd hh:mm:ss,到了excel变成了 yyyy/m/d h:mm,看起来不太习惯,当然可以通过设置excel单元格格式改成自定义格式 yyyy-mm-dd hh:mm:ss,但是这样多了一个步骤,能不能直接从mysql导出到excel的就是mysql显示的样式呢?当然可以. 开始猜想是由于