pytorch中的torch.nn.Conv2d()函数图文详解
目录
- 一、官方文档介绍
- 二、torch.nn.Conv2d()函数详解
- 参数dilation——扩张卷积(也叫空洞卷积)
- 参数groups——分组卷积
- 总结
一、官方文档介绍
nn.Conv2d:对由多个输入平面组成的输入信号进行二维卷积


二、torch.nn.Conv2d()函数详解
参数详解
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
| 参数 | 参数类型 | ||
|---|---|---|---|
| in_channels | int | Number of channels in the input image | 输入图像通道数 |
| out_channels | int | Number of channels produced by the convolution | 卷积产生的通道数 |
| kernel_size | (int or tuple) | Size of the convolving kernel | 卷积核尺寸,可以设为1个int型数或者一个(int, int)型的元组。例如(2,3)是高2宽3卷积核 |
| stride | (int or tuple, optional) | Stride of the convolution. Default: 1 | 卷积步长,默认为1。可以设为1个int型数或者一个(int, int)型的元组。 |
| padding | (int or tuple, optional) | Zero-padding added to both sides of the input. Default: 0 | 填充操作,控制padding_mode的数目。 |
| padding_mode | (string, optional) | ‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. Default: ‘zeros’ | padding模式,默认为Zero-padding 。 |
| dilation | (int or tuple, optional) | Spacing between kernel elements. Default: 1 | 扩张操作:控制kernel点(卷积核点)的间距,默认值:1。 |
| groups | (int, optional) | Number of blocked connections from input channels to output channels. Default: 1 | group参数的作用是控制分组卷积,默认不分组,为1组。 |
| bias | (bool, optional) | If True, adds a learnable bias to the output. Default: True | 为真,则在输出中添加一个可学习的偏差。默认:True。 |
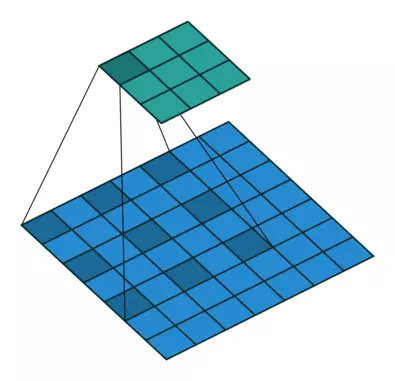
参数dilation——扩张卷积(也叫空洞卷积)
dilation操作动图演示如下:
Dilated Convolution with a 3 x 3 kernel and dilation rate 2
扩张卷积核为3×3,扩张率为2
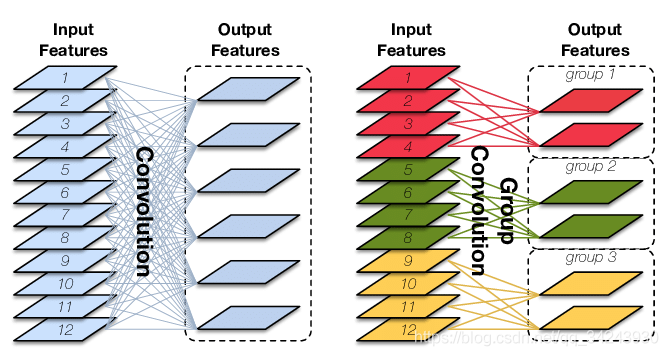
参数groups——分组卷积
Group Convolution顾名思义,则是对输入feature map进行分组,然后每组分别卷积。

三、代码实例
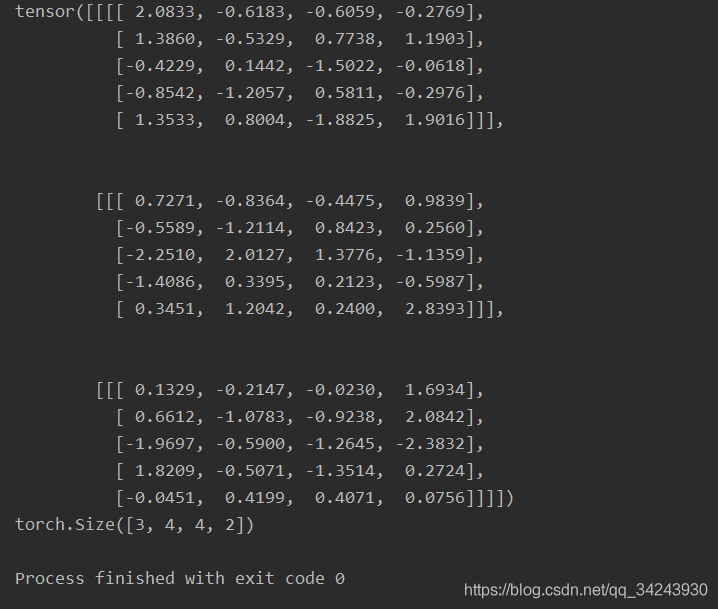
import torch x = torch.randn(3,1,5,4) print(x) conv = torch.nn.Conv2d(1,4,(2,3)) res = conv(x) print(res.shape) # torch.Size([3, 4, 4, 2])
输入:x[ batch_size, channels, height_1, width_1 ]
- batch_size,一个batch中样本的个数 3
- channels,通道数,也就是当前层的深度 1
- height_1, 图片的高 5
- width_1, 图片的宽 4
卷积操作:Conv2d[ channels, output, height_2, width_2 ]
- channels,通道数,和上面保持一致,也就是当前层的深度 1
- output ,输出的深度 4【需要4个filter】
- height_2,卷积核的高 2
- width_2,卷积核的宽 3
输出:res[ batch_size,output, height_3, width_3 ]
- batch_size,,一个batch中样例的个数,同上 3
- output, 输出的深度 4
- height_3, 卷积结果的高度 4
- width_3,卷积结果的宽度 2
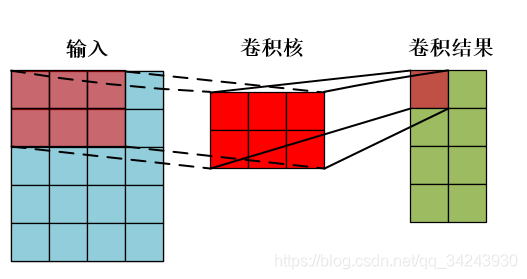
一个样本卷积示例:
总结
到此这篇关于pytorch中torch.nn.Conv2d()函数的文章就介绍到这了,更多相关pytorch torch.nn.Conv2d()函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pytorch.nn.conv2d 过程验证方式(单,多通道卷积过程)
今天在看文档的时候,发现pytorch 的conv操作不是很明白,于是有了一下记录 首先提出两个问题: 1.输入图片是单通道情况下的filters是如何操作的? 即一通道卷积核卷积过程 2.输入图片是多通道情况下的filters是如何操作的? 即多通道多个卷积核卷积过程 这里首先贴出官方文档: classtorch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1
-
pytorch1.0中torch.nn.Conv2d用法详解
Conv2d的简单使用 torch 包 nn 中 Conv2d 的用法与 tensorflow 中类似,但不完全一样. 在 torch 中,Conv2d 有几个基本的参数,分别是 in_channels 输入图像的深度 out_channels 输出图像的深度 kernel_size 卷积核大小,正方形卷积只为单个数字 stride 卷积步长,默认为1 padding 卷积是否造成尺寸丢失,1为不丢失 与tensorflow不一样的是,pytorch中的使用更加清晰化,我们可以使用这种方法定义输
-

pytorch中的torch.nn.Conv2d()函数图文详解
目录 一.官方文档介绍 二.torch.nn.Conv2d()函数详解 参数dilation——扩张卷积(也叫空洞卷积) 参数groups——分组卷积 总结 一.官方文档介绍 官网 nn.Conv2d:对由多个输入平面组成的输入信号进行二维卷积 二.torch.nn.Conv2d()函数详解 参数详解 torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
-
PyTorch基础之torch.nn.Conv2d中自定义权重问题
目录 torch.nn.Conv2d中自定义权重 torch.nn.Conv2d()用法讲解 用法 参数 相关形状 总结 torch.nn.Conv2d中自定义权重 torch.nn.Conv2d函数调用后会自动初始化weight和bias,本文主要涉及 如何自定义weight和bias为需要的数均分布类型: torch.nn.Conv2d.weight.data以及torch.nn.Conv2d.bias.data为torch.tensor类型,因此只要对这两个属性进行操作即可. [sampl
-
PyTorch中clone()、detach()及相关扩展详解
clone() 与 detach() 对比 Torch 为了提高速度,向量或是矩阵的赋值是指向同一内存的,这不同于 Matlab.如果需要保存旧的tensor即需要开辟新的存储地址而不是引用,可以用 clone() 进行深拷贝, 首先我们来打印出来clone()操作后的数据类型定义变化: (1). 简单打印类型 import torch a = torch.tensor(1.0, requires_grad=True) b = a.clone() c = a.detach() a.data *=
-
Windows系统中搭建Go语言开发环境图文详解
目录 1.Go语言简介 2.安装Git 3.Go 工具链(编译器)安装 3.1.环境变量GOROOT 3.2.环境变量GOPATH 3.3.Go常用命令 4.包管理 4.1.go module 4.2.gopm 5.编写Go语言代码的IDE或编辑工具 5.1.基于VSCode的Go开发环境 5.1.1.安装VSCode 5.1.2.安装插件 5.1.3.常用配置 5.2.GoLand 5.3.Vim 5.4.其他Go代码编写工具 6.Go语言学习资料分享 本文详细讲述如何在 Windows 系统
-
Android Studio 中运行 groovy 程序的方法图文详解
Groovy简介 Groovy是一种基于JVM(Java虚拟机)的敏捷开发语言,它结合了Python.Ruby和Smalltalk的许多强大的特性,Groovy 代码能够与 Java 代码很好地结合,也能用于扩展现有代码.由于其运行在 JVM 上的特性,Groovy也可以使用其他非Java语言编写的库. Groovy 是 用于Java虚拟机的一种敏捷的动态语言,它是一种成熟的面向对象编程语言,既可以用于面向对象编程,又可以用作纯粹的脚本语言.使用该种语言不必编写过多的代码,同时又具有闭包和动态语
-
Python中常用的高阶函数实例详解
前言 高阶函数指的是能接收函数作为参数的函数或类:python中有一些内置的高阶函数,在某些场合使用可以提高代码的效率. lambda 当在使用一些函数的时候,我们不需要显式定义函数名称,直接传入lambda匿名函数即可.lambda匿名函数通常和其他函数搭配使用. 比如可以直接使用如下的lambda表达式计算当x=3时,y = x * 3 + 5的函数值. In [1]: (lambda x: x * 3 + 5)(3) Out[1]: 14 map map函数将一个函数和序列/迭代器(可以传
-
numpy中hstack vstack stack concatenate函数示例详解
目录 大纲 1.concatenate() 2.stack() 3.vstack() 4.hstack() 5.tf中的stack() 大纲 本文主要介绍一下numpy中的几个常用函数,包括hstack().vstack().stack().concatenate(). 1.concatenate() 我们先来介绍最全能的concatenate()函数,后面的几个函数其实都可以用concatenate()函数来进行等价操作. concatenate()函数根据指定的维度,对一个元组.列表中的li
-
SQLServer中Partition By及row_number 函数使用详解
partition by关键字是分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组. 今天群里看到一个问题,在这里概述下:查询出不同分类下的最新记录.一看这不是很简单的么,要分类那就用Group By;要最新记录就用Order By呗.然后在自己的表中试着做出来: 首先呢我把表中的数据按照提交时间倒序出来: "corp_name"就是
-
SQL注入报错注入函数图文详解
目录 前言 常用报错函数 用法详解 updatexml()函数 实例 extractvalue()函数 floor()函数 exp()函数 12种报错注入函数 总结 前言 报错注入的前提是当语句发生错误时,错误信息被输出到前端.其漏洞原因是由于开发人员在开发程序时使用了print_r (),mysql_error(),mysqli_connect_error()函数将mysql错误信息输出到前端,因此可以通过闭合原先的语句,去执行后面的语句. 常用报错函数 updatexml()
-
PyTorch中torch.nn.functional.cosine_similarity使用详解
目录 概述 按照dim=0求余弦相似: 按照dim=1求余弦相似: 总结 概述 根据官网文档的描述,其中 dim表示沿着对应的维度计算余弦相似.那么怎么理解呢? 首先,先介绍下所谓的dim: a = torch.tensor([[ [1, 2], [3, 4] ], [ [5, 6], [7, 8] ] ], dtype=torch.float) print(a.shape) """ [ [ [1, 2], [3, 4] ], [ [5, 6], [7, 8] ] ] &qu