使用Python抓取模板之家的CSS模板
Python版本是2.7.9,在win8上测试成功,就是抓取有点慢,本来想用多线程的,有事就罢了。模板之家的网站上的url参数与页数不匹配,懒得去做分析了,就自己改代码中的url吧。大神勿喷!
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# by ustcwq
# 2015-03-15
import urllib,urllib2,os,time
from bs4 import BeautifulSoup
start = time.clock()
path = os.getcwd()+u'/模板之家抓取的模板/'
if not os.path.isdir(path):
os.mkdir(path)
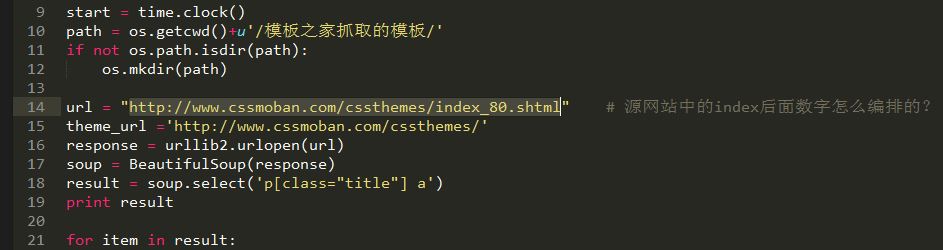
url = "http://www.cssmoban.com/cssthemes/index_80.shtml" # 源网站中的index后面数字怎么编排的?
theme_url ='http://www.cssmoban.com/cssthemes/'
response = urllib2.urlopen(url)
soup = BeautifulSoup(response)
result = soup.select('p[class="title"] a')
print result
for item in result:
link = item['href']
# down_name = item.text # 文件名称
new_url = theme_url+link.split('/')[-1]
response = urllib2.urlopen(new_url)
soup = BeautifulSoup(response)
result = soup.select('.btn a')
down_url = result[1]['href'] # 文件链接
local = path+time.strftime('%Y%m%d%H%M%S',time.localtime(time.time()))+'.zip'
urllib.urlretrieve(down_url, local) # 远程保存函数
end = time.clock()
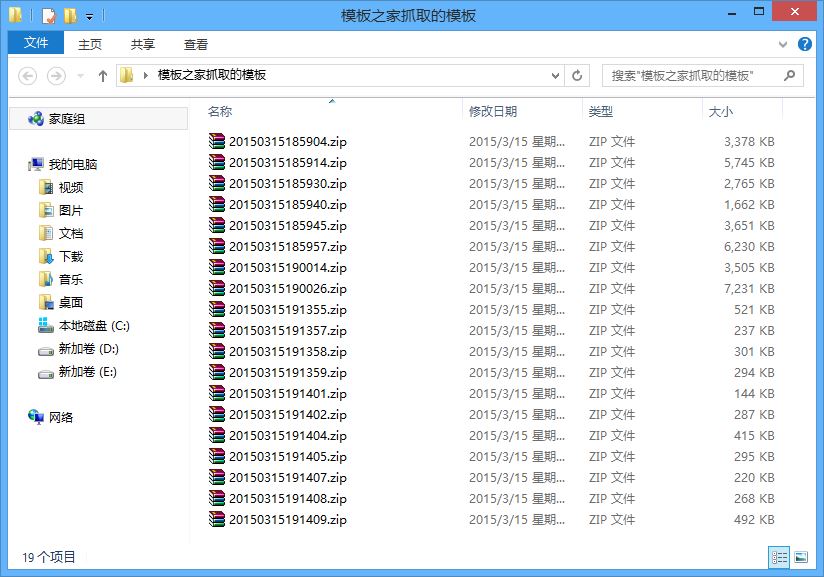
print u'模板抓取完成!'
print u'一共用时:',end-start,u'秒'
以上所述就是本文的全部内容了,希望大家能够喜欢。
相关推荐
-
Python Web开发模板引擎优缺点总结
做 Web 开发少不了要与模板引擎打交道.我陆续也接触了 Python 的不少模板引擎,感觉可以总结一下了. 一.首先按照我的熟悉程度列一下:pyTenjin:我在开发 Doodle 和 91 外教时使用.Tornado.template:我在开发知乎日报时使用.PyJade:我在开发知乎日报时接触过.Mako:我只在一个早期就夭折了的小项目里用过.Jinja2:我只拿它做过一些 demo. 其他就不提了,例如 Django 的模板,据说又慢又难用,我根本就没接触过. 二.再说性能 很多测试就是
-
常用python编程模板汇总
在我们编程时,有一些代码是固定的,例如Socket连接的代码,读取文件内容的代码,一般情况下我都是到网上搜一下然后直接粘贴下来改一改,当然如果你能自己记住所有的代码那更厉害,但是自己写毕竟不如粘贴来的快,而且自己写的代码还要测试,而一段经过测试的代码则可以多次使用,所以这里我就自己总结了一下python中常用的编程模板,如果还有哪些漏掉了请大家及时补充哈. 一.读写文件 1.读文件 (1).一次性读取全部内容 filepath='D:/data.txt' #文件路径 with open(file
-
Python的Django框架中模板碎片缓存简介
你同样可以使用cache标签来缓存模板片段. 在模板的顶端附近加入{% load cache %}以通知模板存取缓存标签. 模板标签{% cache %}在给定的时间内缓存了块的内容. 它至少需要两个参数: 缓存超时时间(以秒计)和指定缓存片段的名称. 示例: {% load cache %} {% cache 500 sidebar %} .. sidebar .. {% endcache %} 有时你可能想缓存基于片段的动态内容的多份拷贝. 比如,你想为上一个例子的每个用户分别缓存侧边栏.
-
详解在Python的Django框架中创建模板库的方法
不管是写自定义标签还是过滤器,第一件要做的事是创建模板库(Django能够导入的基本结构). 创建一个模板库分两步走: 第一,决定模板库应该放在哪个Django应用下. 如果你通过 manage.py startapp 创建了一个应用,你可以把它放在那里,或者你可以为模板库单独创建一个应用. 我们更推荐使用后者,因为你的filter可能在后来的工程中有用. 无论你采用何种方式,请确保把你的应用添加到 INSTALLED_APPS 中. 我们稍后会解释这一点. 第二,在适当的Django应用包里创
-
简介Python设计模式中的代理模式与模板方法模式编程
代理模式 Proxy模式是一种常用的设计模式,它主要用来通过一个对象(比如B)给一个对象(比如A) 提供'代理'的方式方式访问.比如一个对象不方便直接引用,代理就在这个对象和访问者之间做了中介 python的例子 你先设想:一个对象提供rgb三种颜色值,我想获得一个对象的rgb三种颜色,但是我不想让你获得蓝色属性,怎么办? class Proxy(object): def __init__(self, subject): self.__subject = subject # 代理其实本质上就是属
-
基于python实现微信模板消息
我的风格,废话不多说了,直接给大家贴代码了,并在一些难点上给大家附了注释,具体代码如下所示: #!/usr/bin/env python #-*- coding:utf-8 -*- import urllib2,json import datetime,time from config import * import sys reload(sys) sys.setdefaultencoding("utf-8") class WechatPush(): def __init__(self
-

python Django模板的使用方法(图文)
模版基本介绍模板是一个文本,用于分离文档的表现形式和内容. 模板定义了占位符以及各种用于规范文档该如何显示的各部分基本逻辑(模板标签). 模板通常用于产生HTML,但是Django的模板也能产生任何基于文本格式的文档.来一个项目说明1.建立MyDjangoSite项目具体不多说,参考前面.2.在MyDjangoSite(包含四个文件的)文件夹目录下新建templates文件夹存放模版.3.在刚建立的模版下建模版文件user_info.html 复制代码 代码如下: <html> <
-
python中使用sys模板和logging模块获取行号和函数名的方法
对于python,这几天一直有两个问题在困扰我:1.python中没办法直接取得当前的行号和函数名.这是有人在论坛里提出的问题,底下一群人只是在猜测python为什么不像__file__一样提供__line__和__func__,但是却最终也没有找到解决方案.2.如果一个函数在不知道自己名字的情况下,怎么才能递归调用自己.这是我一个同事问我的,其实也是获取函数名,但是当时也是回答不出来. 但是今晚!所有的问题都有了答案.一切还要从我用python的logging模块说起,logging中的for
-
使用Python抓取模板之家的CSS模板
Python版本是2.7.9,在win8上测试成功,就是抓取有点慢,本来想用多线程的,有事就罢了.模板之家的网站上的url参数与页数不匹配,懒得去做分析了,就自己改代码中的url吧.大神勿喷! 复制代码 代码如下: #!/usr/bin/env python # -*- coding: utf-8 -*- # by ustcwq # 2015-03-15 import urllib,urllib2,os,time from bs4 import BeautifulSoup start =
-
Python 抓取微信公众号账号信息的方法
搜狗微信搜索提供两种类型的关键词搜索,一种是搜索公众号文章内容,另一种是直接搜索微信公众号.通过微信公众号搜索可以获取公众号的基本信息及最近发布的10条文章,今天来抓取一下微信公众号的账号信息 爬虫 首先通过首页进入,可以按照类别抓取,通过"查看更多"可以找出页面链接规则: import requests as req import re reTypes = r'id="pc_\d*" uigs="(pc_\d*)">([\s\S]*?)&
-
Python抓取数据到可视化全流程的实现过程
目录 1.爬取目标网站:业绩预告_数据中心_同花顺财经 2.获取序号.股票代码.等你所需要的信息 3.组成DataFrame 4.处理数据 1.爬取目标网站:业绩预告_数据中心_同花顺财经 (ps:headers不会设置的可以看这篇:Python 用requests.get获取网页内容为空 ’ ’) import pandas as pd import numpy as np import matplotlib.pyplot as plt import re import requests##把
-
利用Python抓取阿里云盘资源
目录 网页分析 抓取与解析 模板 完整代码 总结 前阵子阿里云盘大火,送了好多的容量空间.而且阿里云盘下载是不限速,这点比百度网盘好太多了.这两天看到一个第三方网站可以搜索阿里云盘上的资源,但是它的资源顺序不是按时间排序的.这种情况会造成排在前面时间久远的资源是一个已经失效的资源.小编这里用 python 抓取后重新排序. 网页分析 这个网站有两个搜索路线:搜索线路一和搜索线路二,本文章使用的是搜索线路二. 打开控制面板下的网络,一眼就看到一个 seach.html 的 get 请求. 上面带了
-
python抓取网页中图片并保存到本地
在上篇文章给大家分享PHP源码批量抓取远程网页图片并保存到本地的实现方法,感兴趣的朋友可以点击了解详情. #-*-coding:utf-8-*- import os import uuid import urllib2 import cookielib '''获取文件后缀名''' def get_file_extension(file): return os.path.splitext(file)[1] '''創建文件目录,并返回该目录''' def mkdir(path): # 去除左右两边的
-
Python抓取手机号归属地信息示例代码
前言 本文给大家介绍的是利用Python抓取手机归属地信息,文中给出了详细的示例代码,相信对大家的理解和学习很有帮助,以下为Python代码,较为简单,供参考. 示例代码 # -*- coding:utf-8 -*- import requests,re o = open('data.txt','a') e = open('error.txt','a') baseUrl = 'http://www.iluohe.com/' r = requests.get('http://www.iluohe.
-
python抓取最新博客内容并生成Rss
osc的rss不是全文输出的,不开心,所以就有了python抓取osc最新博客生成Rss # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import urllib2 import datetime import time import PyRSS2Gen from email.Utils import formatdate import re import sys import os reload(sys) sys.setdefaul
-
Python抓取Discuz!用户名脚本代码
最近学习Python,于是就用Python写了一个抓取Discuz!用户名的脚本,代码很少但是很搓.思路很简单,就是正则匹配title然后提取用户名写入文本文档.程序以百度站长社区为例(一共有40多万用户),挂在VPS上就没管了,虽然用了延时但是后来发现一共只抓取了50000多个用户名就被封了...代码如下: 复制代码 代码如下: # -*- coding: utf-8 -*-# Author: 天一# Blog: http://www.90blog.org# Version: 1.0# 功能:
-
Python抓取淘宝下拉框关键词的方法
本文实例讲述了Python抓取淘宝下拉框关键词的方法.分享给大家供大家参考.具体如下: import urllib2,re for key in open('key.txt'): do = "http://suggest.taobao.com/sug?code=utf-8&q=%s" % key.rstrip() _re = re.findall('\[\"(.*?)\",\".*?\"\]',urllib2.urlopen(do).re
-
python抓取网页图片并放到指定文件夹
python抓取网站图片并放到指定文件夹 复制代码 代码如下: # -*- coding=utf-8 -*-import urllib2import urllibimport socketimport osimport redef Docment(): print u'把文件存在E:\Python\图(请输入数字或字母)' h=raw_input() path=u'E:\Python\图'+str(h) if not os.path.exists(path):