Python绘制散点密度图的三种方式详解
目录
- 方式一
- 方式二
- 方式三
方式一
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import gaussian_kde
from mpl_toolkits.axes_grid1 import make_axes_locatable
from matplotlib import rcParams
config = {"font.family":'Times New Roman',"font.size": 16,"mathtext.fontset":'stix'}
rcParams.update(config)
# 读取数据
import pandas as pd
filename=r'F:/Rpython/lp37/testdata.xlsx'
df2=pd.read_excel(filename)#读取文件
x=df2['data1'].values
y=df2['data2'].values
xy = np.vstack([x,y])
z = gaussian_kde(xy)(xy)
idx = z.argsort()
x, y, z = x[idx], y[idx], z[idx]
fig,ax=plt.subplots(figsize=(12,9),dpi=100)
scatter=ax.scatter(x,y,marker='o',c=z,edgecolors='',s=15,label='LST',cmap='Spectral_r')
cbar=plt.colorbar(scatter,shrink=1,orientation='vertical',extend='both',pad=0.015,aspect=30,label='frequency') #orientation='horizontal'
font3={'family':'SimHei','size':16,'color':'k'}
plt.ylabel("估计值",fontdict=font3)
plt.xlabel("预测值",fontdict=font3)
plt.savefig('F:/Rpython/lp37/plot70.png',dpi=800,bbox_inches='tight',pad_inches=0)
plt.show()
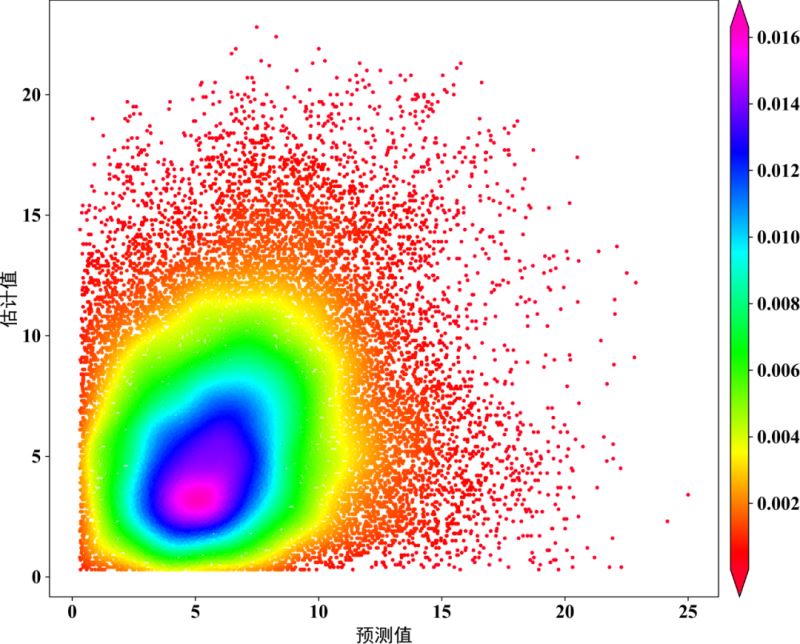
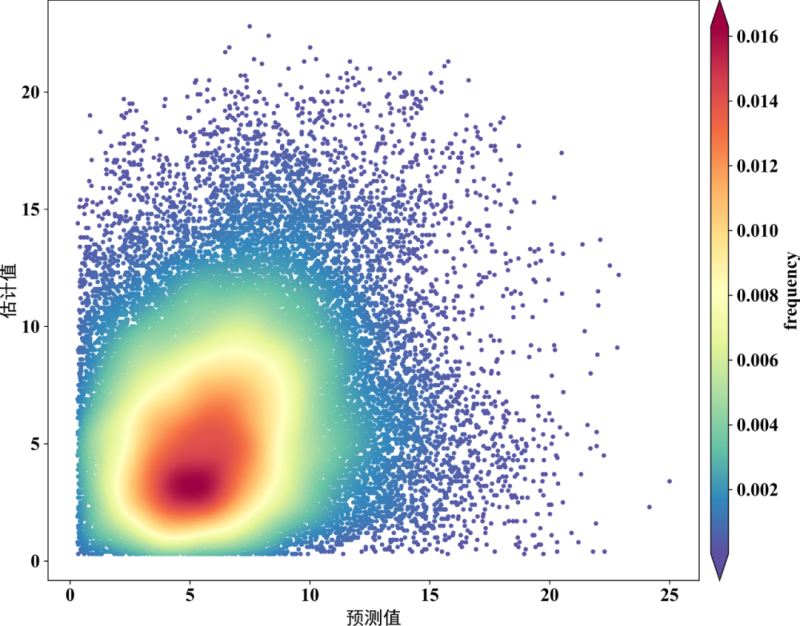
方式二
from statistics import mean
import matplotlib.pyplot as plt
from sklearn.metrics import explained_variance_score,r2_score,median_absolute_error,mean_squared_error,mean_absolute_error
from scipy import stats
import numpy as np
from matplotlib import rcParams
config = {"font.family":'Times New Roman',"font.size": 16,"mathtext.fontset":'stix'}
rcParams.update(config)
def scatter_out_1(x,y): ## x,y为两个需要做对比分析的两个量。
# ==========计算评价指标==========
BIAS = mean(x - y)
MSE = mean_squared_error(x, y)
RMSE = np.power(MSE, 0.5)
R2 = r2_score(x, y)
MAE = mean_absolute_error(x, y)
EV = explained_variance_score(x, y)
print('==========算法评价指标==========')
print('BIAS:', '%.3f' % (BIAS))
print('Explained Variance(EV):', '%.3f' % (EV))
print('Mean Absolute Error(MAE):', '%.3f' % (MAE))
print('Mean squared error(MSE):', '%.3f' % (MSE))
print('Root Mean Squard Error(RMSE):', '%.3f' % (RMSE))
print('R_squared:', '%.3f' % (R2))
# ===========Calculate the point density==========
xy = np.vstack([x, y])
z = stats.gaussian_kde(xy)(xy)
# ===========Sort the points by density, so that the densest points are plotted last===========
idx = z.argsort()
x, y, z = x[idx], y[idx], z[idx]
def best_fit_slope_and_intercept(xs, ys):
m = (((mean(xs) * mean(ys)) - mean(xs * ys)) / ((mean(xs) * mean(xs)) - mean(xs * xs)))
b = mean(ys) - m * mean(xs)
return m, b
m, b = best_fit_slope_and_intercept(x, y)
regression_line = []
for a in x:
regression_line.append((m * a) + b)
fig,ax=plt.subplots(figsize=(12,9),dpi=600)
scatter=ax.scatter(x,y,marker='o',c=z*100,edgecolors='',s=15,label='LST',cmap='Spectral_r')
cbar=plt.colorbar(scatter,shrink=1,orientation='vertical',extend='both',pad=0.015,aspect=30,label='frequency')
plt.plot([0,25],[0,25],'black',lw=1.5) # 画的1:1线,线的颜色为black,线宽为0.8
plt.plot(x,regression_line,'red',lw=1.5) # 预测与实测数据之间的回归线
plt.axis([0,25,0,25]) # 设置线的范围
plt.xlabel('OBS',family = 'Times New Roman')
plt.ylabel('PRE',family = 'Times New Roman')
plt.xticks(fontproperties='Times New Roman')
plt.yticks(fontproperties='Times New Roman')
plt.text(1,24, '$N=%.f$' % len(y), family = 'Times New Roman') # text的位置需要根据x,y的大小范围进行调整。
plt.text(1,23, '$R^2=%.3f$' % R2, family = 'Times New Roman')
plt.text(1,22, '$BIAS=%.4f$' % BIAS, family = 'Times New Roman')
plt.text(1,21, '$RMSE=%.3f$' % RMSE, family = 'Times New Roman')
plt.xlim(0,25) # 设置x坐标轴的显示范围
plt.ylim(0,25) # 设置y坐标轴的显示范围
plt.savefig('F:/Rpython/lp37/plot71.png',dpi=800,bbox_inches='tight',pad_inches=0)
plt.show()
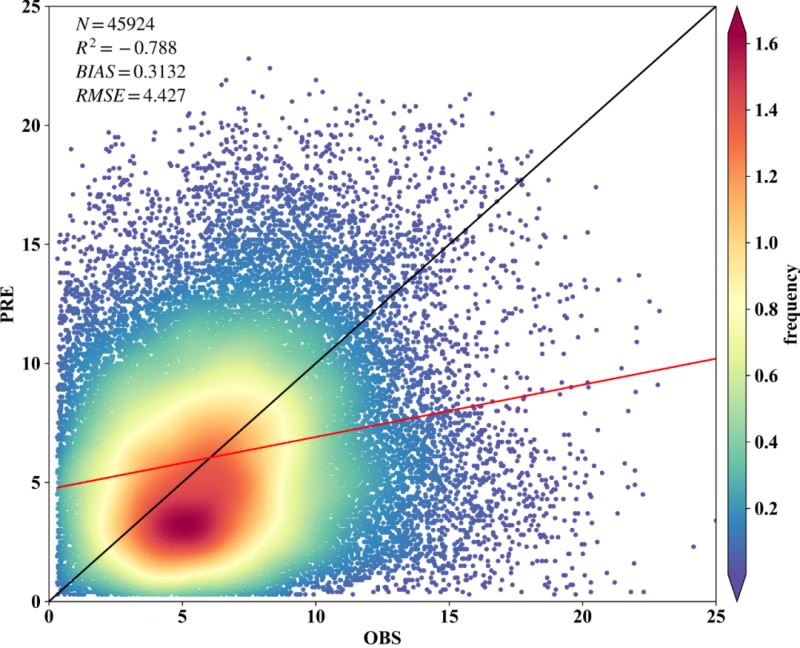
方式三
import pandas as pd
import numpy as np
from scipy import optimize
import matplotlib.pyplot as plt
from matplotlib import cm
from matplotlib.colors import Normalize
from scipy.stats import gaussian_kde
from matplotlib import rcParams
config={"font.family":'Times New Roman',"font.size":16,"mathtext.fontset":'stix'}
rcParams.update(config)
# 读取数据
filename=r'F:/Rpython/lp37/testdata.xlsx'
df2=pd.read_excel(filename)#读取文件
x=df2['data1'].values.ravel()
y=df2['data2'].values.ravel()
N = len(df2['data1'])
#绘制拟合线
x2 = np.linspace(-10,30)
y2 = x2
def f_1(x,A,B):
return A*x + B
A1,B1 = optimize.curve_fit(f_1,x,y)[0]
y3 = A1*x + B1
# Calculate the point density
xy = np.vstack([x,y])
z = gaussian_kde(xy)(xy)
norm = Normalize(vmin = np.min(z), vmax = np.max(z))
#开始绘图
fig,ax=plt.subplots(figsize=(12,9),dpi=600)
scatter=ax.scatter(x,y,marker='o',c=z*100,edgecolors='',s=15,label='LST',cmap='Spectral_r')
cbar=plt.colorbar(scatter,shrink=1,orientation='vertical',extend='both',pad=0.015,aspect=30,label='frequency')
cbar.ax.locator_params(nbins=8)
cbar.ax.set_yticklabels([0.005,0.010,0.015,0.020,0.025,0.030,0.035])#0,0.005,0.010,0.015,0.020,0.025,0.030,0.035
ax.plot(x2,y2,color='k',linewidth=1.5,linestyle='--')
ax.plot(x,y3,color='r',linewidth=2,linestyle='-')
fontdict1 = {"size":16,"color":"k",'family':'Times New Roman'}
ax.set_xlabel("PRE",fontdict=fontdict1)
ax.set_ylabel("OBS",fontdict=fontdict1)
# ax.grid(True)
ax.set_xlim((0,25))
ax.set_ylim((0,25))
ax.set_xticks(np.arange(0,25.1,step=5))
ax.set_yticks(np.arange(0,25.1,step=5))
plt.savefig('F:/Rpython/lp37/plot72.png',dpi=800,bbox_inches='tight',pad_inches=0)
plt.show()
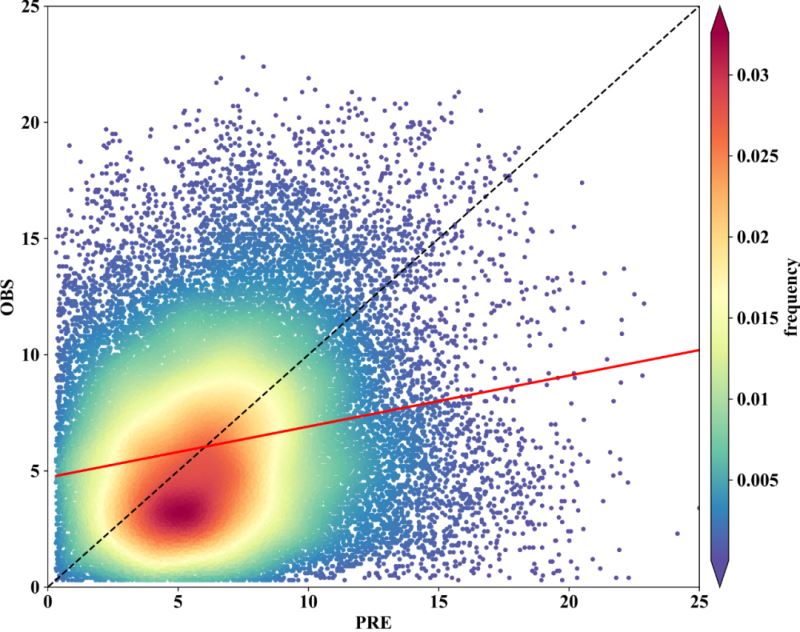
到此这篇关于Python绘制散点密度图的三种方式详解的文章就介绍到这了,更多相关Python散点密度图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python 离散点图画法的实现
目录 基础代码 改进 再次改进: 又次改进: 改进:----加准确率 基础代码 pred_y = test_output.data.numpy() pred_y = pred_y.flatten() print(pred_y, 'prediction number') print(test_y[:355].numpy(), 'real number') import matplotlib.pyplot as plt plt.rc("font", family='KaiTi') pl
-
Python绘制散点图的教程详解
少废话,直接上代码 import matplotlib.pyplot as plt import numpy as np # 1. 首先是导入包,创建数据 n = 10 x = np.random.rand(n) * 2# 随机产生10个0~2之间的x坐标 y = np.random.rand(n) * 2# 随机产生10个0~2之间的y坐标 # 2.创建一张figure fig = plt.figure(1) # 3. 设置颜色 color 值[可选参数,即可填可不填],方式有几种 # col
-
Python绘制简单散点图的方法
散点图,顾名思义是一些散乱的点构成的图.那么这些散乱的点有什么作用呢?散点图通过用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式. 绘制方法大体上与折线图一致,只是对点不需要去拟合折线,使用plt.scatter()函数替代plt.plot()即可.例如绘制三月份与十一月份的气温散点图,代码如下: ''' 绘制散点图,要点:plt.scatter(x,y) ''' # 导入模块 from matplotlib import pyplot a
-
python绘制直方图和密度图的实例
对于pandas的dataframe,绘制直方图方法如下: //pdf是pandas的dataframe, delta_time是其中一列 //xlim是x轴的范围,bins是分桶个数 pdf.delta_time.plot(kind='hist', xlim=(-50,300), bins=500) 对于pandas的dataframe,绘制概率密度图方法如下: //pdf是pandas的dataframe, delta_time是其中一列 pdf.delta_time.dropna().pl
-
python散点图的绘制
目录 一.二维散点图的绘制 1.采用pandas.plotting.scatter_matrix函数绘制 2. 采用seaborn进行绘制 二. 三维散点图绘制 一.二维散点图的绘制 1.采用pandas.plotting.scatter_matrix函数绘制 pd.plotting.scatter_matrix(iris_data, figsize=(10, 10), alpha=1, hist_kwds={"bins": 20}) 2. 采用seaborn进行绘制 # No.
-
Python绘制散点密度图的三种方式详解
目录 方式一 方式二 方式三 方式一 import matplotlib.pyplot as plt import numpy as np from scipy.stats import gaussian_kde from mpl_toolkits.axes_grid1 import make_axes_locatable from matplotlib import rcParams config = {"font.family":'Times New Roman',"fo
-
Python图片存储和访问的三种方式详解
目录 前言 数据准备 一个可以玩的数据集 图像存储的设置 LMDB HDF5 单一图像的存储 存储到 磁盘 存储到 LMDB 存储 HDF5 存储方式对比 多个图像的存储 多图像调整代码 准备数据集对比 单一图像的读取 从 磁盘 读取 从 LMDB 读取 从 HDF5 读取 读取方式对比 多个图像的读取 多图像调整代码 准备数据集对比 读写操作综合比较 数据对比 并行操作 前言 ImageNet 是一个著名的公共图像数据库,用于训练对象分类.检测和分割等任务的模型,它包含超过 1400 万张图像
-
Python写入MySQL数据库的三种方式详解
目录 场景一:数据不需要频繁的写入mysql 场景二:数据是增量的,需要自动化并频繁写入mysql 方式一 方式二 总结 大家好,Python 读取数据自动写入 MySQL 数据库,这个需求在工作中是非常普遍的,主要涉及到 python 操作数据库,读写更新等,数据库可能是 mongodb. es,他们的处理思路都是相似的,只需要将操作数据库的语法更换即可. 本篇文章会给大家分享数据如何写入到 mysql,分为两个场景,三种方式. 场景一:数据不需要频繁的写入mysql 使用 navicat 工
-
Tensorflow 2.4加载处理图片的三种方式详解
目录 前言 数据准备 使用内置函数读取并处理磁盘数据 自定义方式读取和处理磁盘数据 从网络上下载数据 前言 本文通过使用 cpu 版本的 tensorflow 2.4 ,介绍三种方式进行加载和预处理图片数据. 这里我们要确保 tensorflow 在 2.4 版本以上 ,python 在 3.8 版本以上,因为版本太低有些内置函数无法使用,然后要提前安装好 pillow 和 tensorflow_datasets ,方便进行后续的数据加载和处理工作. 由于本文不对模型进行质量保证,只介绍数据的加
-
Python获取协程返回值的四种方式详解
目录 介绍 源码 依次执行结果 介绍 获取协程返回值的四种方式: 1.通过ensure_future获取,本质是future对象中的result方 2.使用loop自带的create_task, 获取返回值 3.使用callback, 一旦await地方的内容运行完,就会运行callback 4.使用partial这个模块向callback函数中传入值 源码 import asyncio from functools import partial async def talk(name): pr
-
Pandas保存csv数据的三种方式详解
目录 方法一 方法二 方法三 补充 方法一 import os import pandas as pd path = 'data/train/' img_label_list=[] testList = os.listdir(path) for file in testList: label='aa' img_label_list.append([file, label]) df1 = pd.DataFrame(data=img_label_list, columns=['id', 'label
-
Java实现AOP代理的三种方式详解
目录 1.JDK实现 2.CGLIB实现 3.boot注解实现[注意只对bean有效] 业务场景:首先你有了一个非常好的前辈无时无刻的在“教育”你.有这么一天,它叫你将它写好的一个方法进行改进测试,这时出现了功能迭代的情况.然后前辈好好“教育”你的说,不行改我的代码!改就腿打折!悲催的你有两条路可走,拿出你10年跆拳道的功夫去火拼一波然后拍拍屁股潇洒走人,要么就是悲催的开始百度...这时你会发现,我擦怎么把AOP代理这种事给忘了?[其实在我们工作中很少去手写它,但是它又是很常见的在使用(控制台日
-
Android Flutter实现搜索的三种方式详解
目录 示例 1 :使用搜索表单创建全屏模式 编码 示例 2:AppBar 内的搜索字段(最常见于娱乐应用程序) 编码 示例 3:搜索字段和 SliverAppBar 编码 结论 示例 1 :使用搜索表单创建全屏模式 我们要构建的小应用程序有一个应用程序栏,右侧有一个搜索按钮.按下此按钮时,将出现一个全屏模式对话框.它不会突然跳出来,而是带有淡入淡出动画和幻灯片动画(从上到下).在圆形搜索字段旁边,有一个取消按钮,可用于关闭模式.在搜索字段下方,我们会显示一些搜索历史记录(您可以添加其他内容,如建
-
Flutter控制组件显示和隐藏三种方式详解
目录 方式一:if语句控制 方式二:Offstage组件 方式三: Visibility Offstage和Visibility的区别: 方式一:if语句控制 // 例如: Column( mainAxisAlignment: MainAxisAlignment.center, children: [ if(a=="显示") Text("显示"), Offstage( offstage: false, child: Text("显示"), ),
-
命令行运行Python脚本时传入参数的三种方式详解
如果在运行python脚本时需要传入一些参数,例如gpus与batch_size,可以使用如下三种方式. python script.py 0,1,2 10 python script.py -gpus=0,1,2 --batch-size=10 python script.py -gpus=0,1,2 --batch_size=10 这三种格式对应不同的参数解析方式,分别为sys.argv, argparse, tf.app.run, 前两者是python自带的功能,最后一个是tensorfl