Python字体反爬实战案例分享
目录
- 实战场景
- 实战编码
实战场景
本篇博客学习字体反爬,涉及的站点是实习 x,目标站点地址直接百度搜索即可。
可以看到右侧源码中出现了很多“乱码”,这其中就包含了关键信息。
接下来按照常规的套路,在开发者工具中检索字体相关信息,但是筛选之后,并没有得到反爬的字体,只有一个 file? 有些许的可能性。

这里就是一种新鲜的场景了,如果判断不准,那只能用字体样式和字体标签名进行判断了。
在网页源码中检索 @font-face 和 myFont,得到下图内容,这里发现 file 字体又出现了,看来解决问题的关键已经出现了。

下载文件名之后发现无后缀名,我们可以补上一个 .ttf 的后缀,接下来拖拽到 FontCreator 中,然后进行查阅。

二次刷新页面之后,再次获取一个 file 文件,查看二者是否有编码变化问题。
结论:每次请求字体文件,得到的响应无变化。
既然没有变化,后续的字体反爬实战编码就变的简单了。
实战编码
解析字体文件,获取编码与字符。
from fontTools.ttLib import TTFont
font1 = TTFont('./fonts/file.ttf')
keys,values = [],[]
for k, v in font1.getBestCmap().items():
print(k,v)
得到的结果如下所示:
2 extra bytes in post.stringData array
120 x
57345 uni4E00
57360 uni77
57403 uni56
……
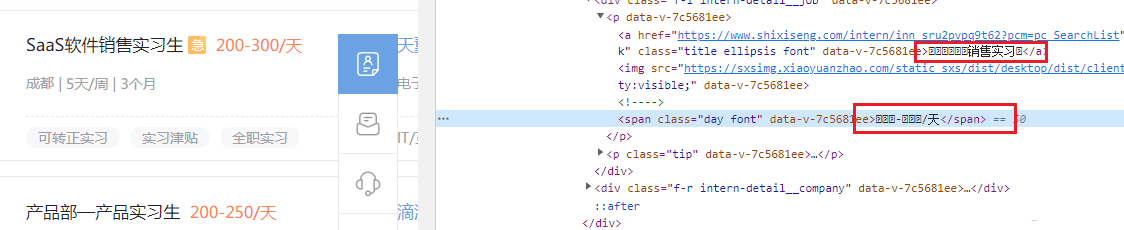
然后我们查看一下实习僧站点返回的数据。
-
这其中又涉及到了编码的转换。
我们拿到一段带编码的文字,如下所示:
销售实习
接下来查看一下页面呈现的文字
SaaS软件销售实习生
其中  对应的是 S 字符,再看一下该字符在字体文件中的编码,如下所示。

但是从刚才的结果中,并未得到 edb3 相关值,但是把十进制的编码进行转换之后,得到下述结果。

到此这篇关于Python字体反爬实战案例分享的文章就介绍到这了,更多相关Python字体反爬 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python政策网字体反爬实例(附完整代码)
目录 1 字体反爬案例 2 使用环境 3 安装python第三方库 4 查看woff文件 5 woff文件解决字体反爬全过程 5.1 调用第三方库 5.2 请求woff链接下载woff文件到本地 5.3 查看woff文件内容,可以通过以下两种方式 5.5 建立字体反爬后与圆字体间对应关系 5.6 得到结果 6 完整代码如下 总结 字体反爬,也是一种常见的反爬技术,这些网站采用了自定义的字体文件,在浏览器上正常显示,但是爬虫抓取下来的数据要么就是乱码,要么就是变成其他字符.下面我们通过其中一种方式
-
python超详细实现字体反爬流程
目录 查策实战场景 字体实战解码 字体反爬编码时间 查策实战场景 本次要采集的目标站点是查策,该测试站点如下所示. 目标站点网址如下 www.chacewang.com/chanye/news?newstype=sbtz 该站点的新闻资讯类信息很容易采集,通过开发者工具查看了一下,并不存在加密反爬. 但字体反爬还是存在的,案例寻找过程非常简单,只需要开发者工具切换到网络,字体视图,然后预览一下字体文件即可. 可以看到仅数字进行了顺序变换. 接下来就是实战解码的过程,可以通过 FontCreato
-
python起点网月票榜字体反爬案例
目录 前言: 1.解析过程 2.开始敲代码 前言: 字体反爬是什么个意思?就是网站把自己的重要数据不直接的在源代码中呈现出来,而是通过相应字体的编码,与一个字体文件(一般后缀为ttf或woff)把相应的编码转换为自己想要的数据,知道了原理,接下来开始展示才艺 1.解析过程 老规矩哈我们先进入起点月票榜f12调试,找到书名与其对应的月票数据所在,使用xpath尝试提取 可以看到刚刚好20条数据,接下来找月票数据: 这是什么鬼xpath检索出来20条数据但是数据为空,element中数据显示
-
Python爬虫实例之2021猫眼票房字体加密反爬策略(粗略版)
前言: 猫眼票房页面的字体加密是动态的,每次或者每天加载页面的字体文件都会有所变化,本篇内容针对这种加密方式进行分析 字体加密原理:简单来说就是程序员在设计网站的时候使用了自己设计的字体代码对关键字进行编码,在浏览器加载的时会根据这个字体文件对这些字体进行编码,从而显示出正确的字体. 已知的使用了字体加密的一些网站: 58同城,起点,猫眼,大众点评,启信宝,天眼查,实习僧,汽车之家 本篇内容不过多解释字体文件的映射关系,不了解的请自行查找其他资料. 如若还未入门爬虫,请往这走 简单粗暴入门法--
-
Python字体反爬实战案例分享
目录 实战场景 实战编码 实战场景 本篇博客学习字体反爬,涉及的站点是实习 x,目标站点地址直接百度搜索即可. 可以看到右侧源码中出现了很多“乱码”,这其中就包含了关键信息. 接下来按照常规的套路,在开发者工具中检索字体相关信息,但是筛选之后,并没有得到反爬的字体,只有一个 file? 有些许的可能性. 这里就是一种新鲜的场景了,如果判断不准,那只能用字体样式和字体标签名进行判断了.在网页源码中检索 @font-face 和 myFont,得到下图内容,这里发现 file 字体又出现了,看来解决
-
python政策网字体反爬实例(附完整代码)
目录 1 字体反爬案例 2 使用环境 3 安装python第三方库 4 查看woff文件 5 woff文件解决字体反爬全过程 5.1 调用第三方库 5.2 请求woff链接下载woff文件到本地 5.3 查看woff文件内容,可以通过以下两种方式 5.5 建立字体反爬后与圆字体间对应关系 5.6 得到结果 6 完整代码如下 总结 字体反爬,也是一种常见的反爬技术,这些网站采用了自定义的字体文件,在浏览器上正常显示,但是爬虫抓取下来的数据要么就是乱码,要么就是变成其他字符.下面我们通过其中一种方式
-
python cookie反爬处理的实现
Cookies的处理 作用 保存客户端的相关状态 在爬虫中如果遇到了cookie的反爬如何处理? 手动处理 在抓包工具中捕获cookie,将其封装在headers中 应用场景:cookie没有有效时长且不是动态变化 自动处理 使用session机制 使用场景:动态变化的cookie session对象:该对象和requests模块用法几乎一致.如果在请求的过程中产生了cookie,如果该请求使用session发起的,则cookie会被自动存储到session中. 案例 爬取
-
Python反爬实战掌握酷狗音乐排行榜加密规则
目录 效果展示 爬取目标 工具使用 项目思路解析 简易源码分享 效果展示 爬取目标 网址:酷我音乐 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,re 项目思路解析 找到需要解析的榜单数据 随意点击一个歌曲获取到音乐的详情数据 通过抓包的方式获取到音乐播放数据 找到MP3的数据提交地址 mp3数据来自于这个url地址 提交数据的网址: https://wwwapi.kugou.com/yy/index.php?r=play/
-
Python和JS反爬之解决反爬参数 signKey
目录 实战场景 系统分析 实战场景 Python 反爬中有一大类,叫做字体反爬,核心的理论就是通过字体文件或者 CSS 偏移,实现加密逻辑 本次要采集的站点是:54yr55y855S15b2x(Base64 加密) 站点地址为:https%3A%2F%2Fmaoyan.com%2Ffilms%2F522013(URL 编码) 上述地址打开之后,用开发者工具选中某文字之后,会发现 Elements 中,无法从源码读取到数据, 如下图所示: 类似的所有场景都属于字体编码系列,简单理解就是: 服务器源
-
Python中常见的反爬机制及其破解方法总结
一.常见反爬机制及其破解方式 封禁IP,使用cookie等前面文章已经讲过 现在主要将下面的: ~ 验证码 -> 文字验证码 -> OCR(光学文字识别)-> 接口 / easyocr 程序自己解决不了的问题就可以考虑使用三方接口(付费/免费) -> 行为验证码 -> 超级鹰 ~ 手机号+短信验证码 -> 接码平台 ~ 动态内容 -> JavaScript逆向 -> 找到提供数据的API接口 -> 手机抓接口 -&g