python爬不同图片分别保存在不同文件夹中的实现
例如,爬取赵丽颖,赵本山,赵文卓,赵欢,赵日天的图片分别保存在赵丽颖,赵本山,赵文卓,赵欢,赵日天命名的文件夹中,
测试代码
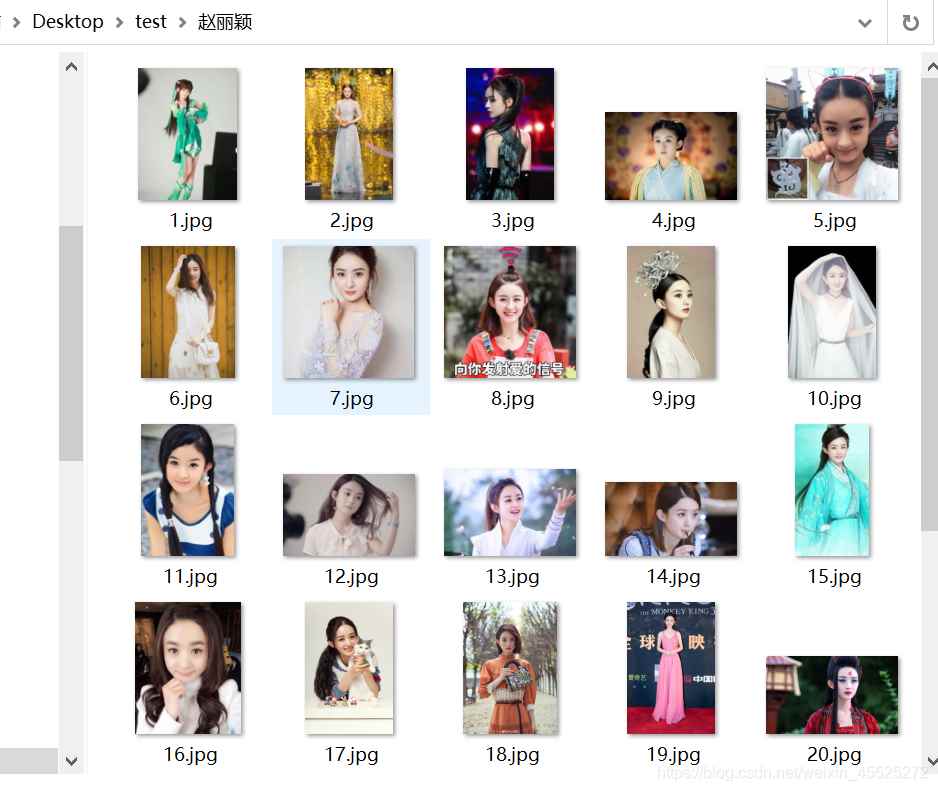
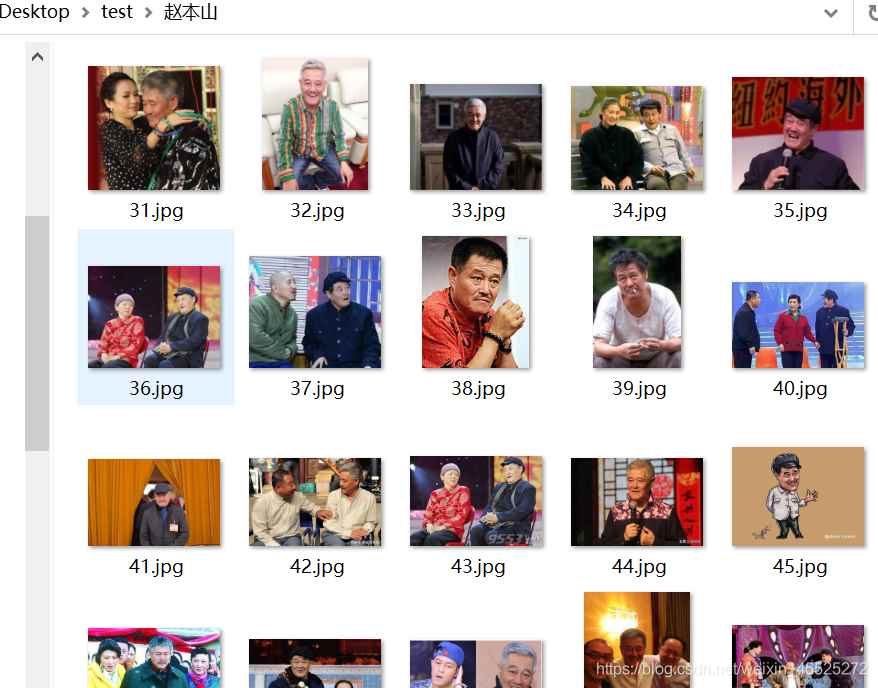
别的图就不放了
import requests
import time
import os
# 请求头,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
# keyword = '云斑白条天牛' # 关键字
keywords = ['赵丽颖','赵本山','赵文卓','赵欢','赵日天']
max_page = 2
i=1 # 记录图片数
for keyword in keywords:
os.makedirs(keyword)
for page in range(1,max_page):
page = page*30
# 网址
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord='\
+keyword+'&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word='\
+keyword+'&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=wallpaper&pn='\
+str(page)+'&rn=30&gsm=1e&1596899786625='
# 请求响应
response = requests.get(url=url,headers=headers)
# 得到相应的json数据
json = response.json()
if json.get('data'):
for item in json.get('data')[:30]:
# 图片地址
img_url = item.get('thumbURL')
# 获取图片
image = requests.get(url=img_url)
# 下载图片
newstr = './'+keyword+'/'+str(i)+'.jpg'
# with open('./%s/%d.jpg'%keywords ,%i,'wb') as f:
with open(newstr,'wb') as f:
f.write(image.content) # 图片二进制数据
time.sleep(1) # 等待1s
print('第%d张%s图片下载完成...'%(i,keyword))
i+=1
print('End!')
你要修改的参数
将你想要爬的数据填入keywords 数组中即可
# 这里放你要查询的数组 keywords = ['','','',']
max_page是爬取百度图片的页数,一页是30张,这里写2的话就能爬30张,3能爬60张,以此类推
max_page = 3
你要的代码
代码如下:
import requests
import time
import os
# 请求头,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
# 这里放你要查询的数组
keywords = ['','','',']
max_page = 4
i=1 # 记录图片数
for keyword in keywords:
os.makedirs(keyword)
for page in range(1,max_page):
page = page*30
# 网址
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord='\
+keyword+'&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word='\
+keyword+'&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=wallpaper&pn='\
+str(page)+'&rn=30&gsm=1e&1596899786625='
# 请求响应
response = requests.get(url=url,headers=headers)
# 得到相应的json数据
json = response.json()
if json.get('data'):
for item in json.get('data')[:30]:
# 图片地址
img_url = item.get('thumbURL')
# 获取图片
image = requests.get(url=img_url)
# 下载图片
newstr = './'+keyword+'/'+str(i)+'.jpg'
# with open('./%s/%d.jpg'%keywords ,%i,'wb') as f:
with open(newstr,'wb') as f:
f.write(image.content) # 图片二进制数据
time.sleep(1) # 等待1s
print('第%d张%s图片下载完成...'%(i,keyword))
i+=1
print('End!')
到此这篇关于python爬不同图片分别保存在不同文件夹中的实现的文章就介绍到这了,更多相关python爬图片保存不同文件夹内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python 爬虫批量爬取网页图片保存到本地的实现代码
其实和爬取普通数据本质一样,不过我们直接爬取数据会直接返回,爬取图片需要处理成二进制数据保存成图片格式(.jpg,.png等)的数据文本. 现在贴一个url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg 请复制上面的url直接在某个浏览器打开,你会看到如下内容: 这就是通过网页访问到的该网站的该图片,于是我们可以直接利用requests模块,进行这个图片的请求,于是这个网站便会返回给我们该图片的数据,我们
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
Python使用爬虫抓取美女图片并保存到本地的方法【测试可用】
本文实例讲述了Python使用爬虫抓取美女图片并保存到本地的方法.分享给大家供大家参考,具体如下: 图片资源来自于www.qiubaichengren.com 代码基于Python 3.5.2 友情提醒:血气方刚的骚年.请 谨慎阅图! 谨慎阅图!! 谨慎阅图!!! code: #!/usr/bin/env python # -*- coding: utf-8 -*- import os import urllib import urllib.request import re from urll
-
Python爬取网站图片并保存的实现示例
先看看结果吧,去bilibili上拿到的图片=-= 第一步,导入模块 import requests from bs4 import BeautifulSoup requests用来请求html页面,BeautifulSoup用来解析html 第二步,获取目标html页面 hd = {'user-agent': 'chrome/10'} # 伪装自己是个(chrome)浏览器=-= def download_all_html(): try: url = 'https://www.bilibili
-
Python3直接爬取图片URL并保存示例
有时候我们会需要从网络上爬取一些图片,来满足我们形形色色直至不可描述的需求. 一个典型的简单爬虫项目步骤包括两步:获取网页地址和提取保存数据. 这里是一个简单的从图片url收集图片的例子,可以成为一个小小的开始. 获取地址 这些图片的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前面部分截取,再在最后递增并字符串化后循环即可. 抑或是它们的URL都保存在某个文件中,这时可以读取到列表中: def getUrls(path): urls = [] with open(
-
Python爬虫获取图片并下载保存至本地的实例
1.抓取煎蛋网上的图片. 2.代码如下: import urllib.request import os #to open the url def url_open(url): req=urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0') response=urllib.request.u
-
python爬不同图片分别保存在不同文件夹中的实现
例如,爬取赵丽颖,赵本山,赵文卓,赵欢,赵日天的图片分别保存在赵丽颖,赵本山,赵文卓,赵欢,赵日天命名的文件夹中, 测试代码 别的图就不放了 import requests import time import os # 请求头,伪装成浏览器 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116
-
Python爬取csnd文章并转为PDF文件
目录 1.导入模块 2.创建文件夹 3.发送请求 4.数据解析 5.如果把列表里面每一个元素 都提取出来 6.替换特殊字符 7.转换成PDF文件 本篇文章流程(爬虫基本思路): 数据来源分析 (只有当你找到数据来源的时候, 才能通过代码实现) 确定需求(要爬取的内容是什么?)爬取CSDN文章内容 保存pdf 通过开发者工具进行抓包分析 分析数据从哪里来的? 代码实现过程: 发送请求 对于文章列表页面发送请求 获取数据 获取网页源代码 解析数据 文章的url 以及 文章标题 发送请求 对于文章详情
-
python读取文件夹中图片的图片名并写入excel表格
有的时候,我们需要读取图片名,写入表格中,以便结合图片的其他信息,做进一步的分析. 假如,现在要读取存放在E盘的origin_file文件夹,读取里面的图片名将其写入到excel文件img.xlsx中. 首先,需要读取图片文件夹路径 import pandas as pd import os os.chdir('E:\\') #1.读取图片文件夹路径 path='origin_file' 然后,pandas建立空白excel文件"img.xlsx" #2.建立空白excel文件&quo
-
Python 实现判断图片格式并转换,将转换的图像存到生成的文件夹中
我就废话不多说了,直接上代码吧! import Image from datetime import datetime import os str = '/home/dltest/caffe/examples/sgg_datas/images/result_test/zutest/' + datetime.now().strftime("%Y%m%d_%H%M%S") while True==os.path.exists(str): str = str + datetime.now()
-
用python删除文件夹中的重复图片(图片去重)
第一部分:判断两张图片是否相同 要查找重复的图片,必然绕不开判断两张图片是否相同.判断两张图片简单呀!图片可以看成数组,比较两个数组是否相等不就行了.但是这样做太过简单粗暴,因为两个数组的每个元素都要一一比较,效率很低.为了尽量避免两个庞大的数组比较: 先进行两张图片的大小(byte)比较,若大小不相同,则两张图片不相同: 在两张图片的大小相同的前提下,进行两张图片的尺寸(长和宽)比较,若尺寸不相同,则两张不相同: 在两张图片的尺寸相同的前提下,进行两张图片的内容(即数组元素)比较,若内容不相同
-
对python遍历文件夹中的所有jpg文件的实例详解
python发现文件夹下所有的jpg文件,并且安装文件排放的顺序输出 glob模块是最简单的模块之一,内容非常少.用它可以查找符合特定规则的文件路径名.跟使用windows下的文件搜索差不多.查找文件只用到三个匹配符:"*", "?", "[]"."*"匹配0个或多个字符:"?"匹配单个字符:"[]"匹配指定范围内的字符,如:[0-9]匹配数字. glob.glob 返回所有匹配的文件路
-
使用Python实现从各个子文件夹中复制指定文件的方法
之前用来整理图片的小程序,拿来备忘,算是使用Python复制文件的一个例子. # -*- coding: utf-8 -*- #程序用来拷贝文件并输出图片采集日期等其他信息到Excel中 #文件夹结构: #2016_07_07 # -Data_07_07_001 # -Random1 # -image001_co.pgm # -image001_c1.pgm # -image002_co.pgm # -image002_c1.pgm # --- # -Random2 # --- # -Data_
-
python+selenium+chrome批量文件下载并自动创建文件夹实例
实现效果:通过url所绑定的关键名创建目录名,每次访问一个网页url后把文件下载下来 代码: 其中 data[i][0].data[i][1] 是代表 关键词(文件保存目录).网站链接(要下载文件的网站) def getDriverHttp(): for i in range(reCount): # 创建Chrome浏览器配置对象实例 chromeOptions = webdriver.ChromeOptions() # 设定下载文件的保存目录为d盘的tudi目录, # 如果该目录不存在,将会自
-
Python实现清除文件夹中重复视频
目录 前言 1.科普 二进制文件 摘要算法(MD5) shutil模块 2.视频清除 视频全在一个文件夹里 视频在不同的文件夹里 3.总结 前言 在早期学Python的时候,买了一本<Python编程快速上手-让繁琐工作自动化>. 这本书里面讲得都比较基础,不过却非常的实用. 估计从书名大家伙们就应该能体会到. 本次根据书中的「读写文件」章节内容,实现一个简单又实用的小操作. 涉及到的模块有os.hashlib.shutil. 利用这三个模块实现对文件夹中的重复视频进行清除,实现文件夹中无重复
-
Python实现比较两个文件夹中代码变化的方法
本文实例讲述了Python实现比较两个文件夹中代码变化的方法.分享给大家供大家参考.具体如下: 这里将修改代码后的目录与原始目录做对比,罗列出新增的代码文件,以及修改过的代码文件 # -*- coding: utf-8 -*- import os; folderA = "F:\\Projects\\FreeImageV3_14_1\\".lower(); folderB = u"E:\\Software\\图像解码库\\FreeImage3141\\FreeImage\\&q